Clear Sky Science · it
FERMam: un framework leggero a doppia fonte e multi-scala per il riconoscimento delle espressioni facciali
Perché insegnare ai computer a leggere i volti è importante
I nostri telefoni, le auto e i dispositivi domestici stanno migliorando nella comprensione di ciò che diciamo, ma faticano ancora a percepire come ci sentiamo. Il riconoscimento delle espressioni facciali punta a cambiare questo permettendo alle macchine di “leggere” le emozioni umane dai volti in foto o video. Questo potrebbe rendere le lezioni online più reattive, i sistemi di monitoraggio del conducente più sicuri e i robot sociali più naturali con cui interagire. La sfida è farlo in modo accurato e veloce su dispositivi di uso quotidiano come telefoni, tablet e robot di servizio che non dispongono della potenza di un grande centro dati. Questo articolo presenta FERMam, un nuovo metodo progettato per leggere le espressioni in modo affidabile utilizzando molto meno potere di calcolo rispetto a molti sistemi attuali.
Osservare il volto da due prospettive utili
La maggior parte dei sistemi esistenti guarda un volto in uno di due modi. Le reti neurali convoluzionali sono abili a individuare dettagli locali come rughe o la forma delle sopracciglia, ma faticheranno a cogliere come parti distanti del viso siano correlate. I modelli basati su transformer catturano bene le relazioni a lunga distanza ma sono pesanti e lenti, difficili da eseguire su dispositivi piccoli. FERMam combina i punti di forza di entrambi con un design “a doppia fonte”. Un ramo si concentra sull’aspetto complessivo del volto, usando un encoder d’immagine potente ma efficiente. L’altro ramo traccia i principali punti di riferimento facciali — punti intorno agli occhi, alla bocca e ad altre regioni importanti. Questi landmark enfatizzano la geometria del volto, che tende a rimanere stabile anche quando cambiano illuminazione, tonalità della pelle o sfondo. Mescolando apparenza e geometria, FERMam può concentrarsi sulle regioni sottili in cui le emozioni si manifestano realmente.
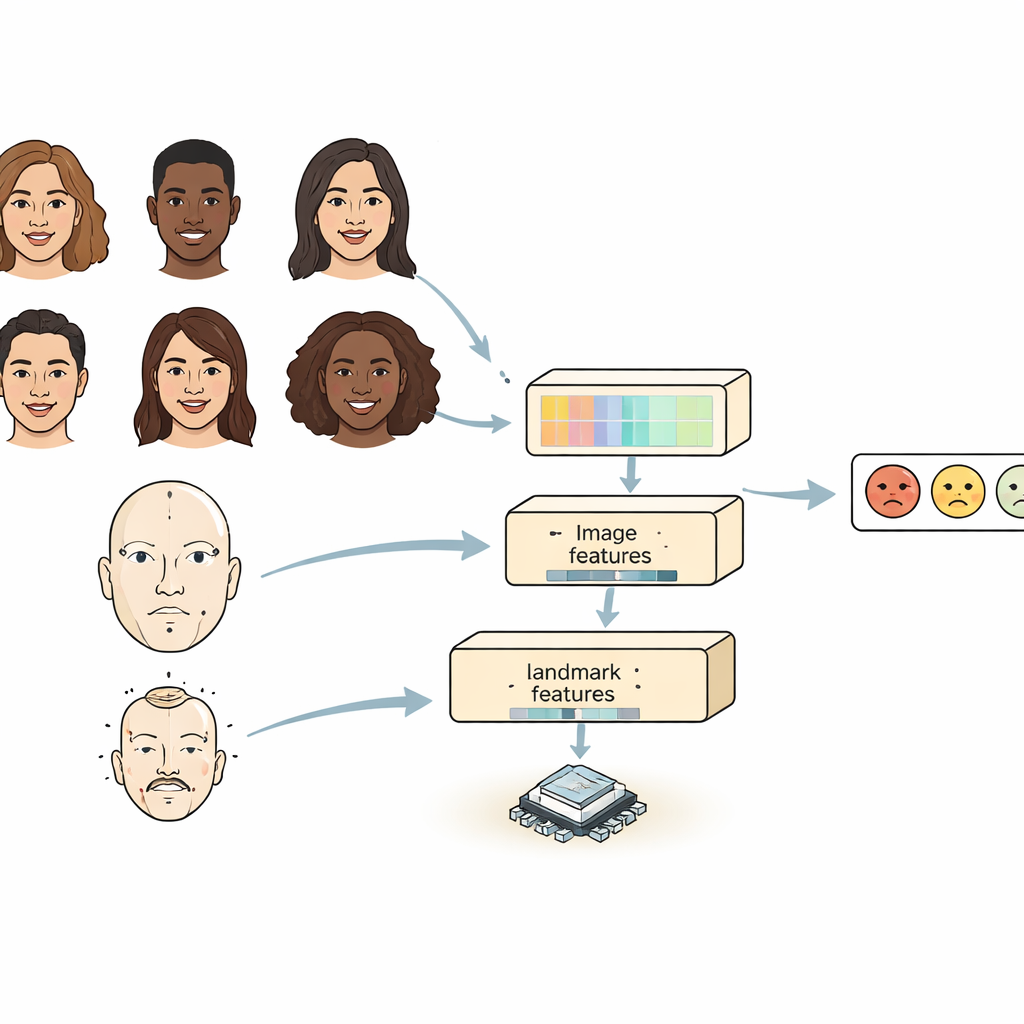
Catturare sia i piccoli dettagli che il quadro generale
Dopo l’estrazione delle caratteristiche di base, FERMam le passa attraverso un modulo speciale chiamato Conv-SSM. Un percorso in questo modulo si comporta come una rete convoluzionale tradizionale, affinando dettagli fini come bordi e texture intorno agli occhi e alla bocca. L’altro percorso utilizza una famiglia più recente di modelli noti come modelli a spazio di stato, in particolare una variante chiamata Mamba. Invece di confrontare ogni parte dell’immagine con ogni altra parte, Mamba “scansiona” il volto in più direzioni, costruendo una memoria di come le caratteristiche cambiano da una zona all’altra. Questo permette al sistema di cogliere relazioni a lungo raggio, per esempio come un sopracciglio sollevato e una bocca contratta possano insieme segnalare rabbia, mantenendo al contempo sotto controllo il costo computazionale. Le uscite di questi due percorsi vengono poi abilmente rimescolate e ricombinate in modo che informazione locale e globale possano interagire.
Fondere informazioni su diverse scale
Le emozioni possono apparire come piccoli cambiamenti in una regione limitata o come spostamenti ampi su tutto il volto. Per gestire questo, FERMam usa una struttura di fusione a piramide. Crea diverse versioni della mappa delle caratteristiche a risoluzioni differenti, dalla più grossolana alla più fine, e processa ciascun livello con un modulo di Refinement adattivo delle caratteristiche a spazio di stato (Adaptive State-space Feature Refinement). A ogni scala, questo modulo rafforza i pattern locali importanti tramite convoluzioni leggere e poi usa una scansione semplificata a spazio di stato per collegare regioni distanti. Un meccanismo di gating integrato può potenziare i segnali provenienti da aree ricche di espressione, come occhi e bocca, attenuando al contempo distrazioni dovute allo sfondo o a dettagli legati all’identità. Dopo il raffinamento, le informazioni di tutte le scale vengono ricombinate, formando un riassunto ricco ma compatto che infine viene passato a un piccolo classificatore per decidere quale emozione è mostrata.
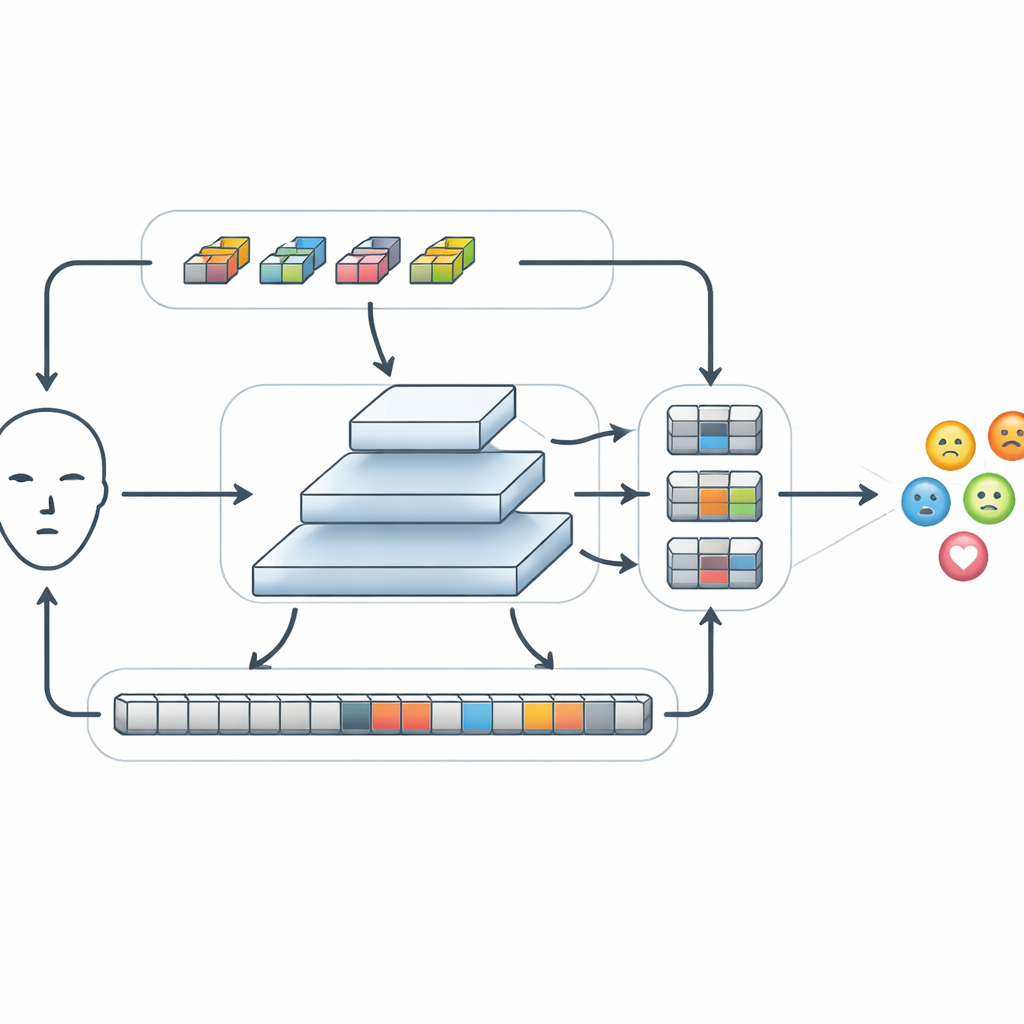
Prestazioni dei modelli potenti con molto meno calcolo
Gli autori hanno testato FERMam su tre principali benchmark per le espressioni facciali: RAF-DB, AffectNet e FERPlus. Queste raccolte contengono decine o centinaia di migliaia di volti tratti da condizioni del mondo reale, con illuminazione, età e pose variabili. Su questi dataset, FERMam ha raggiunto livelli di accuratezza vicini o superiori a molti metodi di punta che si affidano a architetture transformer pesanti. Su uno dei dataset più usati, le sue prestazioni si avvicinano quasi al miglior sistema pubblicato basato su transformer, pur usando circa un terzo o la metà dei parametri e molte meno operazioni. Nella pratica, questo significa che FERMam può funzionare più del doppio della velocità, elaborare molte più immagini al secondo in modalità batch e mantenere comunque alta la qualità del riconoscimento. Studi di ablazione — esperimenti controllati in cui parti del progetto vengono rimosse — mostrano che ogni componente, dal ramo dei landmark alla fusione a piramide, gioca un ruolo significativo in questo equilibrio.
Cosa significa per le tecnologie di tutti i giorni
In termini semplici, lo studio dimostra che è possibile costruire un sistema di lettura delle emozioni che sia sia intelligente sia parsimonioso. Combinando due viste del volto — come appare e come è strutturato — e organizzando con cura il flusso di informazione nello spazio e nella scala, FERMam ottiene un riconoscimento efficace senza richiedere un supercomputer. Questo lo rende un candidato promettente per l’uso in telefoni, robot domestici, telecamere di assistenza alla guida e altri dispositivi che devono rispondere in tempo reale e con sensibilità alle emozioni umane. Sebbene lavori futuri dovranno affrontare condizioni più estreme come forti occlusioni o immagini a risoluzione molto bassa, FERMam indica la strada verso un calcolo pratico, efficiente e più attento all’essere umano.
Citazione: Gao, C., Ji, X., Zhang, Q. et al. FERMam: a lightweight dual-source and multi-scale fusion framework for facial expression recognition. Sci Rep 16, 13826 (2026). https://doi.org/10.1038/s41598-026-44396-6
Parole chiave: riconoscimento delle espressioni facciali, IA sensibile alle emozioni, deep learning leggero, modelli a spazio di stato, interazione uomo–computer