Clear Sky Science · sv
FERMam: ett lättviktigt tvåkälligt och flerskaligt fusionsramverk för igenkänning av ansiktsuttryck
Varför det spelar roll att lära datorer att läsa ansikten
Våra telefoner, bilar och hemenheter blir bättre på att förstå vad vi säger, men de har fortfarande svårt att uppfatta hur vi känner oss. Igenkänning av ansiktsuttryck syftar till att ändra på det genom att låta maskiner ”läsa” mänskliga känslor från ansikten i bilder eller video. Det kan göra nätbaserade lektioner mer responsiva, övervakningssystem för förare säkrare och sociala robotar mer naturliga att interagera med. Utmaningen är att göra detta både noggrant och snabbt på vardagsenheter som telefoner, surfplattor och servicerobotar som saknar datacenterkraft. Denna artikel introducerar FERMam, en ny metod designad för att läsa uttryck tillförlitligt samtidigt som den använder avsevärt mindre beräkningskraft än många nuvarande system.
Att se ansiktet från två kompletterande perspektiv
De flesta befintliga system betraktar ett ansikte på ett av två sätt. Konvolutionella neurala nätverk är bra på att upptäcka lokala detaljer som rynkor eller ögonbrynens form, men har svårt att se hur avlägsna delar av ansiktet relaterar till varandra. Transformerbaserade modeller fångar långräckta relationer väl men är tunga och långsamma, vilket gör dem svåra att köra på små enheter. FERMam förenar styrkorna från båda världarna med en ”tvåkällig” design. En gren fokuserar på ansiktets övergripande utseende genom en stark men effektiv bildkodare. Den andra grenen följer nyckellandmärken i ansiktet — punkter runt ögon, mun och andra viktiga regioner. Dessa landmärken betonar ansiktets geometri, som tenderar att vara stabil även när ljus, hudton eller bakgrund skiftar. Genom att blanda utseende och geometri kan FERMam koncentrera sig på de subtila regioner där känslor verkligen visar sig.
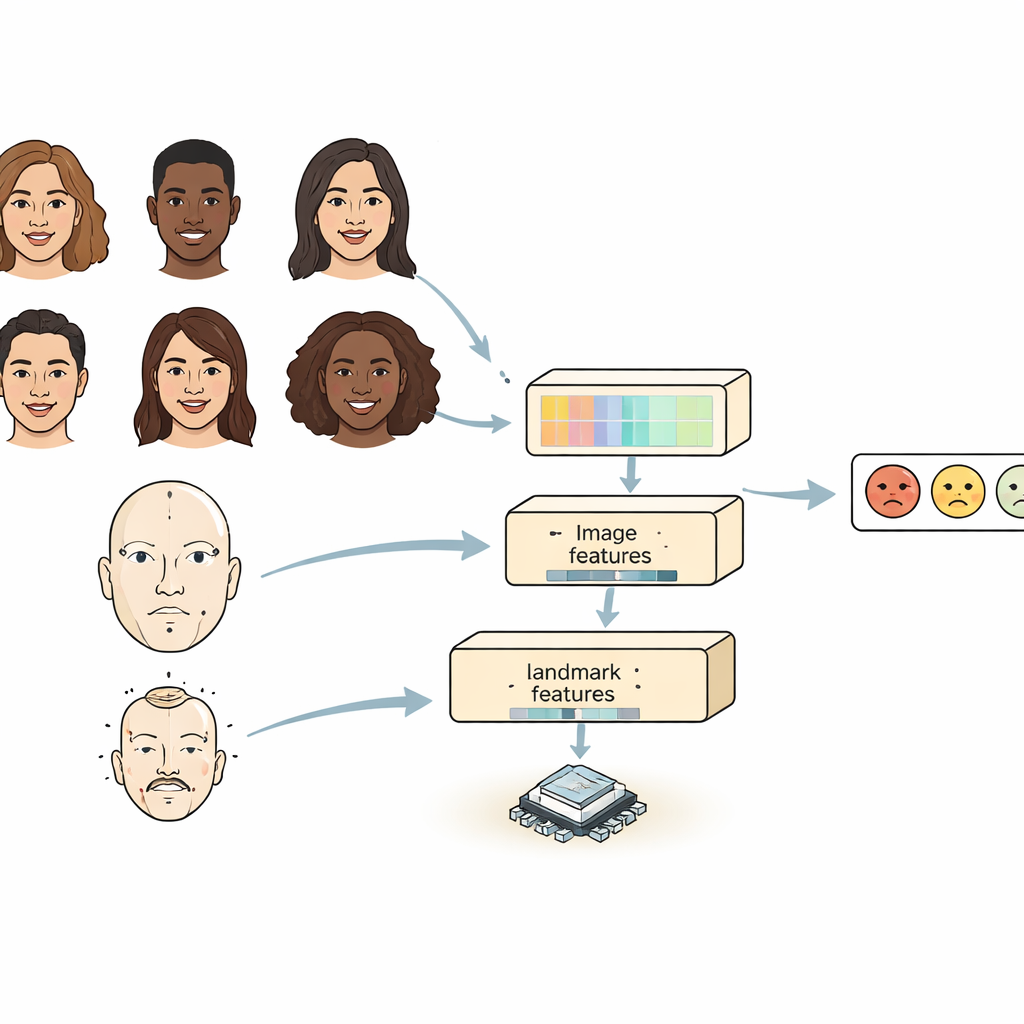
Att fånga både små detaljer och helhetsbilden
När grundläggande drag har extraherats skickar FERMam dem genom en särskild modul kallad Conv-SSM. En väg i denna modul beter sig som ett traditionellt konvolutionsnät och skärper fina detaljer som kanter och texturer kring ögon och mun. Den andra vägen använder en nyare familj modeller kända som tillståndsrymdsmodeller, i synnerhet en variant kallad Mamba. Istället för att jämföra varje del av bilden med varje annan del ”skannar” Mamba över ansiktet i flera riktningar och bygger upp ett minne av hur drag förändras från plats till plats. Det gör att systemet kan fånga långräckta relationer, till exempel hur ett höjt ögonbryn och en hårt sluten mun tillsammans kan signalera ilska, samtidigt som beräkningsmängden hålls i schack. Utflödena från dessa två vägar blandas sedan skickligt om och återkombineras så att lokal och global information kan interagera.
Att blanda information över olika skalor
Känslor kan visa sig som små förändringar i en liten region eller som breda skiftningar över hela ansiktet. För att hantera detta använder FERMam en pyramidfusionsstruktur. Den skapar flera versioner av funktionskartan på olika upplösningar, från grov till fin, och bearbetar varje nivå med en adaptiv förfiningsmodul för tillståndsrymdsdrag (Adaptive State-space Feature Refinement). Vid varje skala stärker denna modul viktiga lokala mönster genom lättviktskonvolution och använder sedan en strömlinjeformad tillståndsrymdsskanning för att länka avlägsna regioner. En inbyggd grindmekanism kan förstärka signaler från uttrycksrika områden, såsom ögon och mun, samtidigt som den dämpar störningar från bakgrund eller identitetsspecifika detaljer. Efter förfining förenas informationen från alla skalor igen och bildar en rik men kompakt sammanfattning som slutligen skickas till en liten klassificerare för att avgöra vilken känsla som visas.
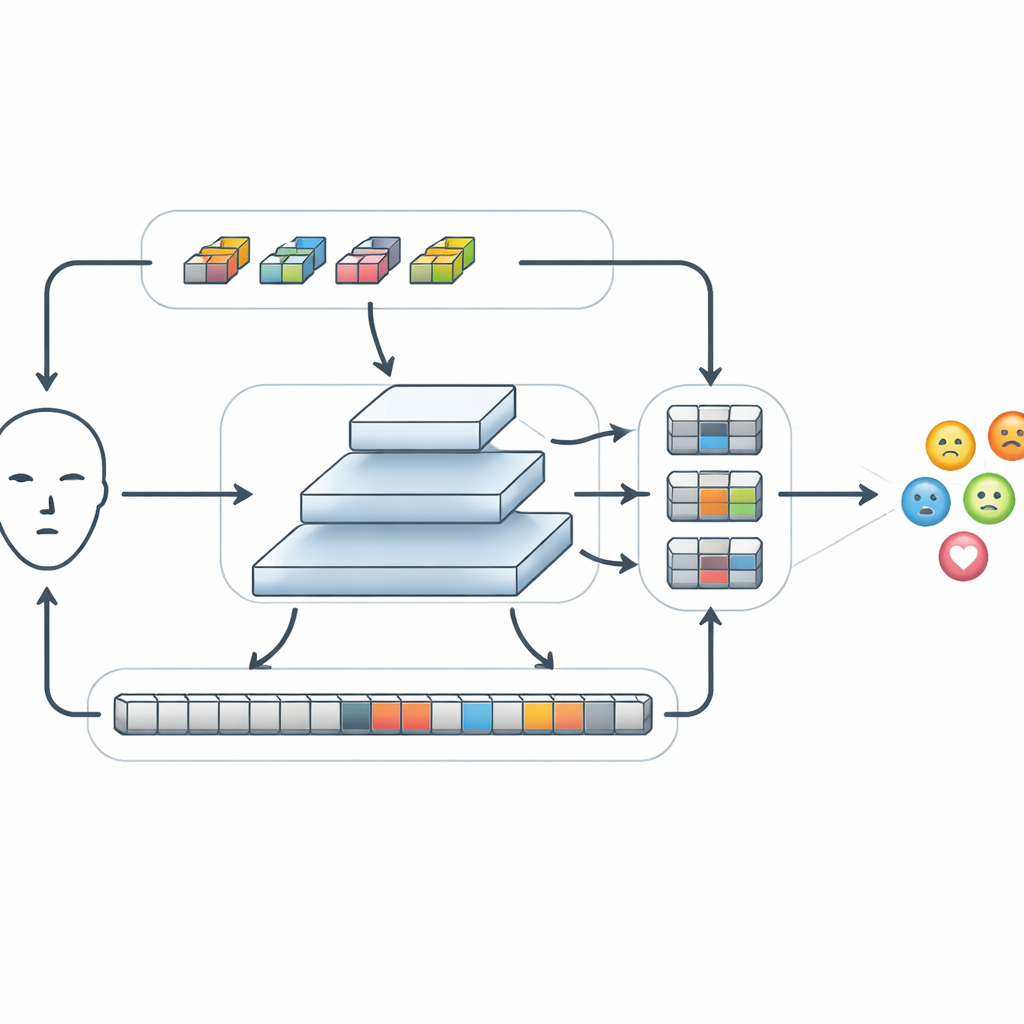
Att matcha kraftfulla modeller med mycket mindre beräkning
Författarna testade FERMam på tre stora databanker för ansiktsuttryck: RAF-DB, AffectNet och FERPlus. Dessa samlingar innehåller tiotusentals till hundratusentals ansikten hämtade från verkliga förhållanden, inklusive varierande ljusförhållanden, åldrar och poser. På dessa dataset nådde FERMam noggrannhetsnivåer som låg nära eller över många ledande metoder som förlitar sig på tunga transformerarkitekturer. På ett välanvänt dataset matchade dess prestanda nästan det bästa publicerade transformerbaserade systemet, men använder ungefär en tredjedel till hälften så många parametrar och avsevärt färre operationer. I praktiken innebär det att FERMam kan köras mer än två gånger snabbare, bearbeta betydligt fler bilder per sekund i batchläge och ändå behålla hög igenkänningskvalitet. Ablationsstudier — kontrollerade experiment där delar av designen tas bort — visar att varje komponent, från landmärkesgrenen till pyramidfusionen, spelar en betydelsefull roll i denna balans.
Vad det betyder för vardagsteknik
Enkelt uttryckt visar studien att det är möjligt att bygga ett känslesystem som är både smart och sparsamt. Genom att kombinera två vyer av ansiktet — hur det ser ut och hur det är format — och genom att noggrant organisera hur information flödar över rum och skala, uppnår FERMam stark igenkänning utan att kräva en superdator. Det gör den till en lovande kandidat för användning i telefoner, hemmarobotar, förarassistanskameror och andra enheter som behöver reagera inkännande på mänskliga känslor i realtid. Medan framtida arbete behöver hantera mer extrema förhållanden som kraftig ocklusion eller mycket lågupplösta bilder, pekar FERMam vägen mot praktisk, effektiv och mer människomedveten databehandling.
Citering: Gao, C., Ji, X., Zhang, Q. et al. FERMam: a lightweight dual-source and multi-scale fusion framework for facial expression recognition. Sci Rep 16, 13826 (2026). https://doi.org/10.1038/s41598-026-44396-6
Nyckelord: igenkänning av ansiktsuttryck, känslomedveten AI, lättviktig djupinlärning, tillståndsrymdsmodeller, människa–dator-interaktion