Clear Sky Science · fr
FERMam : un cadre de fusion multi-source et multi-échelle léger pour la reconnaissance des expressions faciales
Pourquoi apprendre aux ordinateurs à lire les visages est important
Nos téléphones, voitures et appareils domestiques comprennent de mieux en mieux ce que nous disons, mais ils ont encore du mal à percevoir comment nous nous sentons. La reconnaissance des expressions faciales vise à changer cela en permettant aux machines de « lire » les émotions humaines à partir de visages sur des photos ou des vidéos. Cela pourrait rendre les cours en ligne plus adaptés, les systèmes de surveillance des conducteurs plus sûrs, et les robots sociaux plus naturels à fréquenter. Le défi consiste à faire cela de façon précise et rapide sur des appareils du quotidien comme les téléphones, tablettes et robots de service qui ne disposent pas de la puissance d’un grand centre de données. Cet article présente FERMam, une nouvelle méthode conçue pour lire les expressions de façon fiable tout en utilisant beaucoup moins de puissance de calcul que de nombreux systèmes actuels.
Voir le visage depuis deux points de vue complémentaires
La plupart des systèmes existants regardent un visage selon l’un de deux angles. Les réseaux de neurones convolutionnels excellent pour repérer des détails locaux comme les rides ou la forme des sourcils, mais peinent à saisir comment des régions distantes du visage se relient entre elles. Les modèles basés sur les transformers captent bien les relations à longue portée mais sont lourds et lents, difficiles à exécuter sur de petits appareils. FERMam combine les forces des deux approches avec une conception « à double source ». Une branche se concentre sur l’apparence globale du visage, en utilisant un encodeur d’images puissant mais efficace. L’autre suit des points clés du visage — des repères autour des yeux, de la bouche et d’autres zones importantes. Ces repères mettent en avant la géométrie du visage, qui reste souvent stable même lorsque l’éclairage, le ton de peau ou l’arrière-plan changent. En mêlant apparence et géométrie, FERMam peut se focaliser sur les régions subtiles où les émotions se manifestent vraiment.
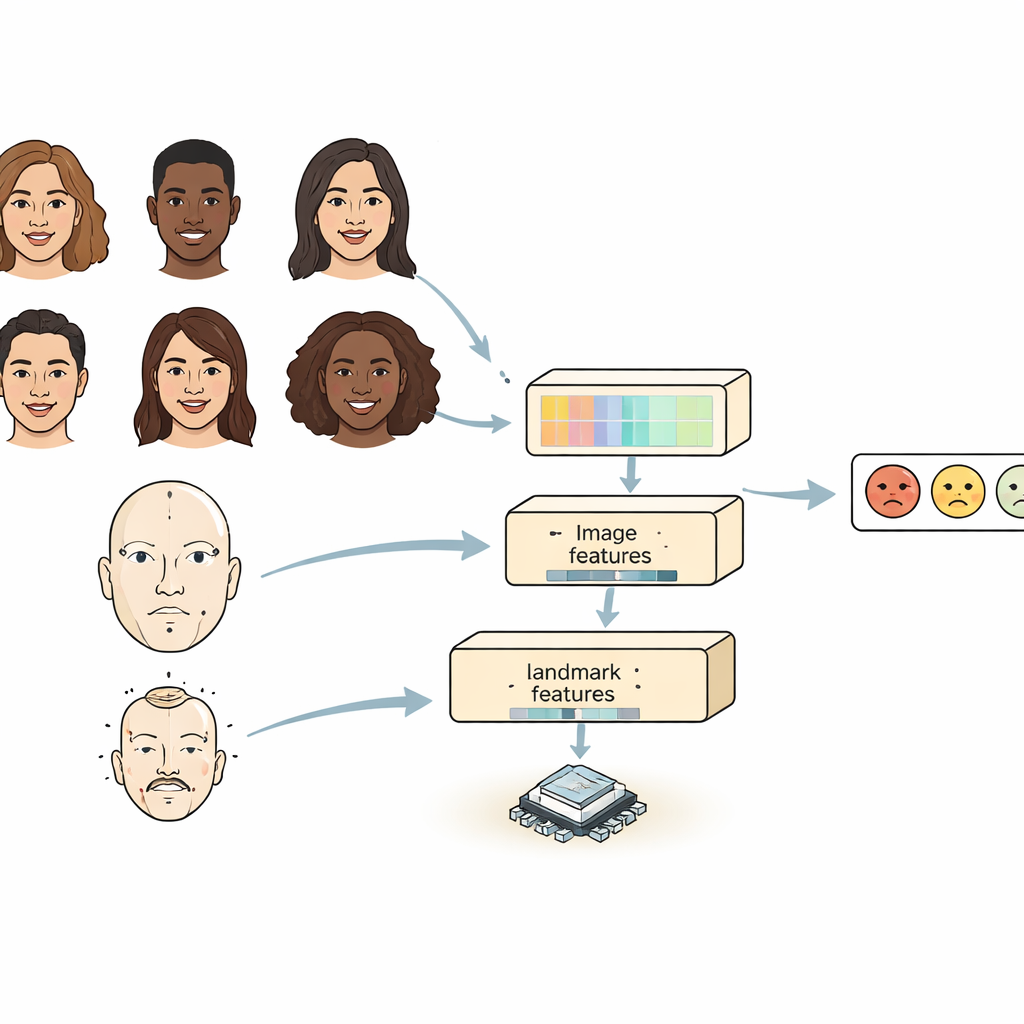
Capturer à la fois les petits détails et la vue d’ensemble
Après extraction des caractéristiques de base, FERMam les fait passer par un module spécial appelé Conv-SSM. Un chemin de ce module se comporte comme un réseau convolutionnel traditionnel, affinant les détails fins tels que les contours et les textures autour des yeux et de la bouche. L’autre chemin utilise une famille plus récente de modèles connue sous le nom de modèles d’état (state-space models), en particulier une variante appelée Mamba. Plutôt que de comparer chaque partie de l’image à toutes les autres, Mamba « balaye » le visage dans plusieurs directions, construisant une mémoire de la façon dont les caractéristiques évoluent d’un endroit à l’autre. Cela permet au système de saisir des relations à longue portée, par exemple comment un sourcil relevé associé à une bouche tendue peut signaler la colère, tout en maîtrisant la charge de calcul. Les sorties de ces deux chemins sont ensuite astucieusement réordonnées et recombinées pour que l’information locale et globale puisse interagir.
Mélanger l’information à différentes échelles
Les émotions peuvent se manifester par de petits changements dans une zone restreinte ou par des modifications étendues sur l’ensemble du visage. Pour y répondre, FERMam utilise une structure de fusion en pyramide. Il crée plusieurs versions de la carte de caractéristiques à différentes résolutions, du grossier au fin, et traite chaque niveau avec un module de raffinement adaptatif des caractéristiques d’état (Adaptive State-space Feature Refinement). À chaque échelle, ce module renforce les motifs locaux importants via des convolutions légères puis utilise un balayage d’état simplifié pour relier des régions distantes. Un mécanisme de gating intégré peut amplifier les signaux provenant des zones riches en expressions, comme les yeux et la bouche, tout en atténuant les distractions dues à l’arrière-plan ou aux détails spécifiques à l’identité. Après raffinement, les informations de toutes les échelles sont réunies, formant un résumé riche mais compact qui est finalement transmis à un petit classifieur pour décider de l’émotion affichée.
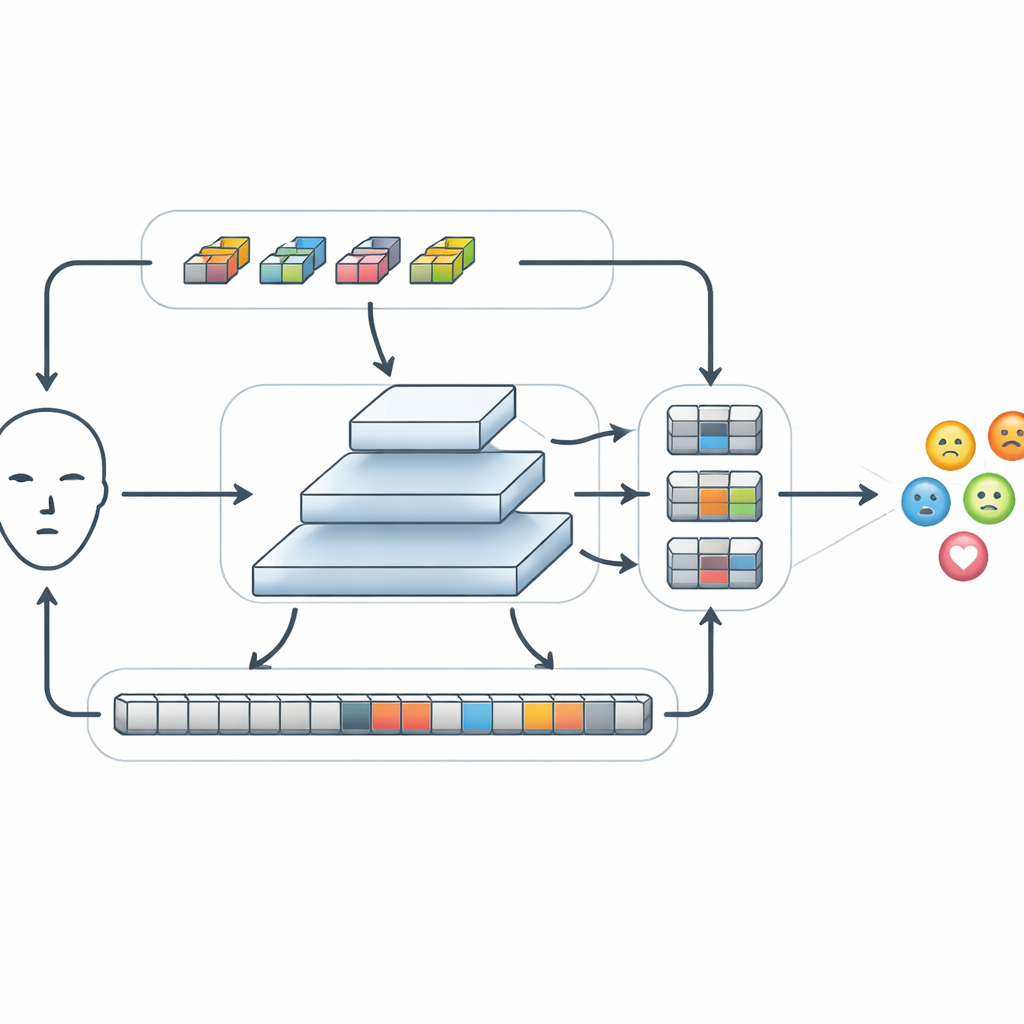
Associer des modèles puissants à une consommation de calcul bien moindre
Les auteurs ont évalué FERMam sur trois grandes références en reconnaissance d’expressions faciales : RAF-DB, AffectNet et FERPlus. Ces collections contiennent des dizaines à centaines de milliers de visages provenant de conditions réelles, incluant des variations d’éclairage, d’âge et de pose. Sur ces jeux de données, FERMam a atteint des niveaux de précision proches ou supérieurs à ceux de nombreuses méthodes de pointe reposant sur des architectures lourdes de type transformer. Sur l’un des jeux de données largement utilisés, ses performances approchent celles du meilleur système publié basé sur les transformers, tout en utilisant environ un tiers à la moitié moins de paramètres et bien moins d’opérations. En pratique, cela signifie que FERMam peut s’exécuter plus de deux fois plus vite, traiter beaucoup plus d’images par seconde en mode lot, tout en maintenant une haute qualité de reconnaissance. Les études d’ablation — des expériences contrôlées où des composants sont retirés — montrent que chaque élément, de la branche des repères à la fusion en pyramide, joue un rôle significatif dans cet équilibre.
Ce que cela signifie pour les technologies du quotidien
En termes simples, l’étude montre qu’il est possible de construire un système de lecture des émotions à la fois performant et économe. En combinant deux vues du visage — son apparence et sa géométrie — et en organisant soigneusement le flux d’information dans l’espace et entre les échelles, FERMam obtient une forte reconnaissance sans exiger un superordinateur. Cela en fait un candidat prometteur pour les téléphones, robots domestiques, caméras d’assistance à la conduite et autres dispositifs qui doivent répondre de manière sensible aux émotions humaines en temps réel. Si des travaux futurs devront aborder des conditions plus extrêmes comme de fortes occultations ou des images de très basse résolution, FERMam montre la voie vers un calcul pratique, efficace et plus conscient de l’humain.
Citation: Gao, C., Ji, X., Zhang, Q. et al. FERMam: a lightweight dual-source and multi-scale fusion framework for facial expression recognition. Sci Rep 16, 13826 (2026). https://doi.org/10.1038/s41598-026-44396-6
Mots-clés: reconnaissance des expressions faciales, IA sensible aux émotions, apprentissage profond léger, modèles d'état, interaction homme–machine