Clear Sky Science · en
FERMam: a lightweight dual-source and multi-scale fusion framework for facial expression recognition
Why teaching computers to read faces matters
Our phones, cars, and home devices are getting better at understanding what we say, but they still struggle to sense how we feel. Facial Expression Recognition aims to change that by letting machines "read" human emotions from faces in photos or video. This could make online classes more responsive, driver monitoring systems safer, and social robots more natural to interact with. The challenge is doing this accurately and quickly on everyday devices like phones, tablets, and service robots that do not have the power of a large data center. This article introduces FERMam, a new method designed to read expressions reliably while using far less computing power than many current systems.
Seeing the face from two helpful viewpoints
Most existing systems look at a face in one of two ways. Convolutional neural networks are good at spotting local details such as wrinkles or eyebrow shapes, but they have trouble seeing how distant parts of the face relate to one another. Transformer-based models capture long-range relationships well but are heavy and slow, making them hard to run on small devices. FERMam combines the strengths of both worlds with a "dual-source" design. One branch focuses on the overall look of the face, using a strong but efficient image encoder. The other branch tracks key facial landmarks — points around the eyes, mouth, and other important regions. These landmarks emphasize the geometry of the face, which tends to stay stable even when lighting, skin tone, or background change. By blending appearance and geometry, FERMam can concentrate on the subtle regions where emotions truly show.
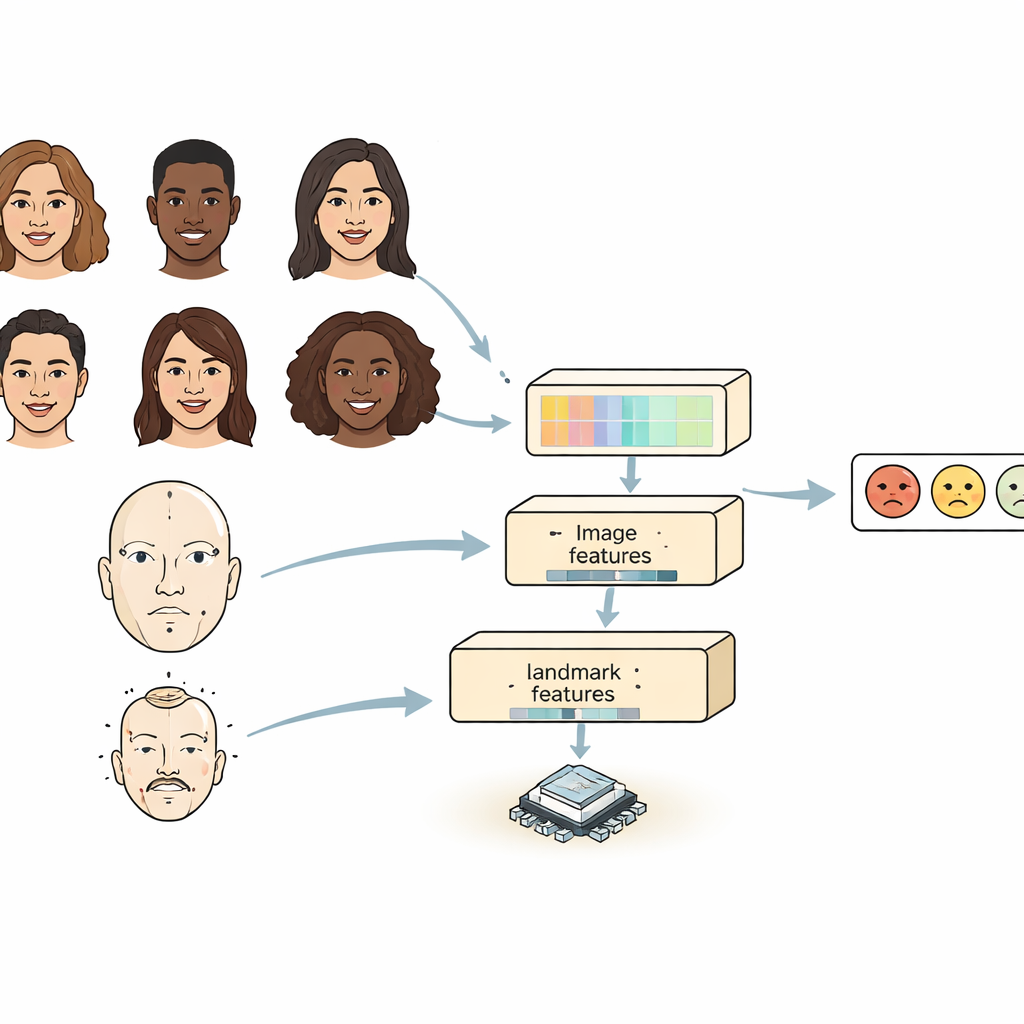
Capturing both small details and the big picture
After basic features are extracted, FERMam passes them through a special module called Conv-SSM. One path in this module behaves like a traditional convolutional network, sharpening fine details such as edges and textures around the eyes and mouth. The other path uses a newer family of models known as state-space models, in particular a variant called Mamba. Instead of comparing every part of the image with every other part, Mamba “scans” across the face in several directions, building up a memory of how features change from place to place. This allows the system to capture long-range relationships, such as how a raised eyebrow and a tight mouth together might signal anger, while keeping the amount of computation under control. The outputs of these two paths are then cleverly shuffled and recombined so that local and global information can interact.
Blending information across different scales
Emotions can appear as tiny changes in a small region or as broad shifts across the whole face. To handle this, FERMam uses a pyramid fusion structure. It creates several versions of the feature map at different resolutions, from coarse to fine, and processes each level with an Adaptive State-space Feature Refinement module. At each scale, this module strengthens important local patterns through lightweight convolution and then uses a streamlined state-space scan to link distant regions. A built-in gating mechanism can boost signals from expression-rich areas, such as the eyes and mouth, while downplaying distractions from background or identity-specific details. After refinement, the information from all scales is brought back together, forming a rich yet compact summary that is finally passed to a small classifier to decide which emotion is being shown.
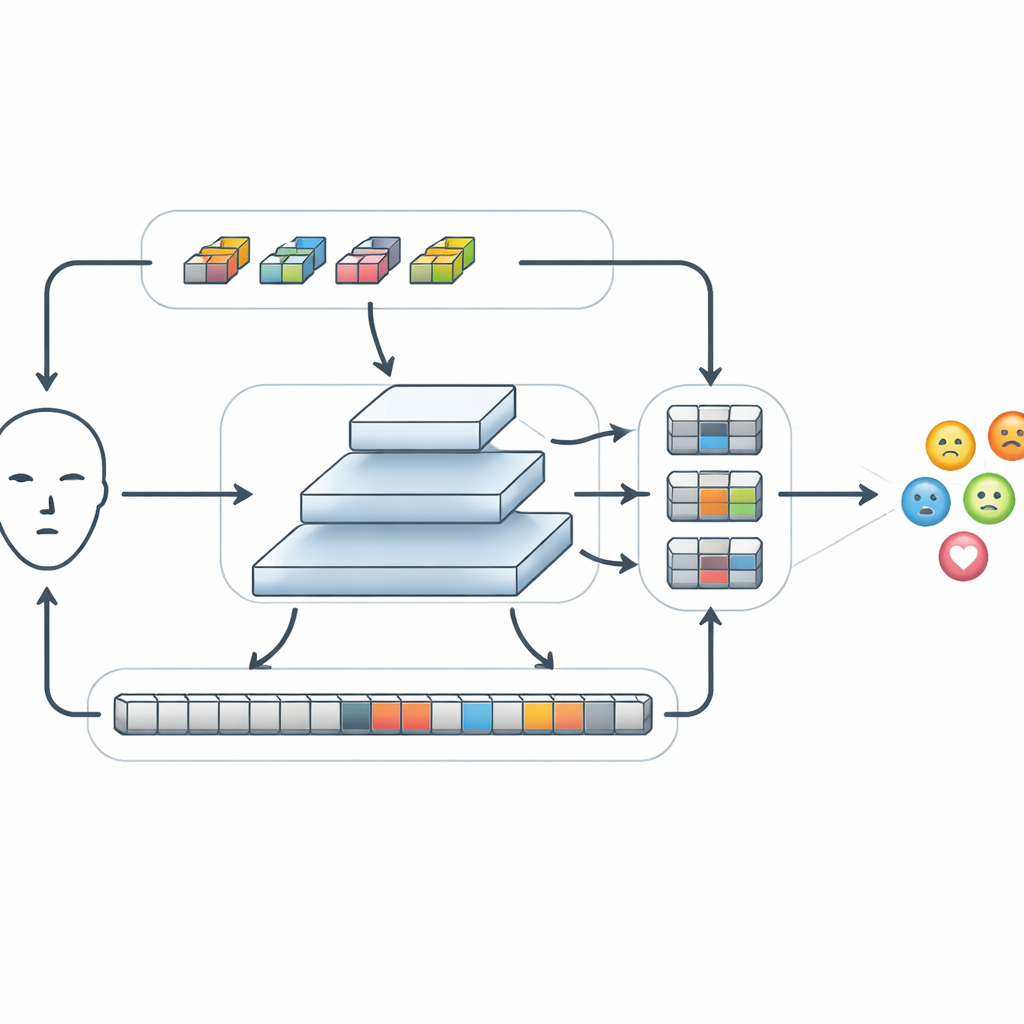
Matching powerful models with much less computing
The authors tested FERMam on three major facial expression benchmarks: RAF-DB, AffectNet, and FERPlus. These collections contain tens to hundreds of thousands of faces drawn from real-world conditions, including varied lighting, ages, and poses. On these datasets, FERMam reached accuracy levels close to or better than many leading methods that rely on heavy transformer architectures. On one widely used dataset, its performance nearly matches the best published transformer-based system, yet it uses roughly one third to one half as many parameters and far fewer operations. In practice, this means that FERMam can run more than twice as fast, process many more images per second in batch mode, and still keep recognition quality high. Ablation studies — controlled experiments in which parts of the design are removed — show that each component, from the landmark branch to the pyramid fusion, plays a meaningful role in this balance.
What this means for everyday technologies
In simple terms, the study shows that it is possible to build an emotion-reading system that is both smart and frugal. By combining two views of the face — how it looks and how it is shaped — and by carefully organizing how information flows across space and scale, FERMam achieves strong recognition without demanding a supercomputer. This makes it a promising candidate for use in phones, home robots, driver-assistance cameras, and other devices that need to respond sensitively to human emotions in real time. While future work will need to tackle more extreme conditions such as heavy occlusion or very low-resolution images, FERMam points the way toward practical, efficient, and more human-aware computing.
Citation: Gao, C., Ji, X., Zhang, Q. et al. FERMam: a lightweight dual-source and multi-scale fusion framework for facial expression recognition. Sci Rep 16, 13826 (2026). https://doi.org/10.1038/s41598-026-44396-6
Keywords: facial expression recognition, emotion-aware AI, lightweight deep learning, state space models, human–computer interaction