Clear Sky Science · nl
FERMam: een lichtgewicht fusion-framework met dubbele bron en meerdere schalen voor herkenning van gezichtsuitdrukkingen
Waarom het belangrijk is dat computers gezichten kunnen "lezen"
Onze telefoons, auto’s en huishoudelijke apparaten worden steeds beter in het begrijpen van wat we zeggen, maar ze hebben nog moeite om te voelen hoe we ons voelen. Gezichtsuitdrukkingsherkenning probeert dat te veranderen door machines in staat te stellen menselijke emoties af te leiden uit gezichten op foto’s of in video. Dat kan online lessen responsiever maken, systemen voor bestuurdersbewaking veiliger en sociale robots natuurlijker om mee te interacteren. De uitdaging is dit nauwkeurig en snel te doen op alledaagse apparaten zoals telefoons, tablets en servicerobots die niet de rekenkracht van een groot datacenter hebben. Dit artikel introduceert FERMam, een nieuwe methode die is ontworpen om uitdrukkingen betrouwbaar te lezen terwijl hij veel minder rekenkracht gebruikt dan veel huidige systemen.
Het gezicht bekijken vanuit twee nuttige invalshoeken
De meeste bestaande systemen bekijken een gezicht op één van twee manieren. Convolutionele neurale netwerken zijn goed in het herkennen van lokale details zoals rimpels of de vorm van wenkbrauwen, maar hebben moeite om te zien hoe verre delen van het gezicht zich tot elkaar verhouden. Transformer-gebaseerde modellen leggen langeafstandsrelaties goed vast, maar zijn zwaar en traag, waardoor ze moeilijk op kleine apparaten draaien. FERMam combineert de sterktes van beide werelden met een "dual-source" ontwerp. De ene tak richt zich op het algemene uiterlijk van het gezicht, met een krachtige maar efficiënte beeldencoder. De andere tak volgt belangrijke gezichtslandmarks — punten rond de ogen, mond en andere relevante regio’s. Deze landmarks benadrukken de geometrie van het gezicht, die doorgaans stabiel blijft zelfs wanneer verlichting, huidskleur of achtergrond veranderen. Door uiterlijk en geometrie te mengen, kan FERMam zich concentreren op de subtiele regio’s waar emoties echt zichtbaar worden.
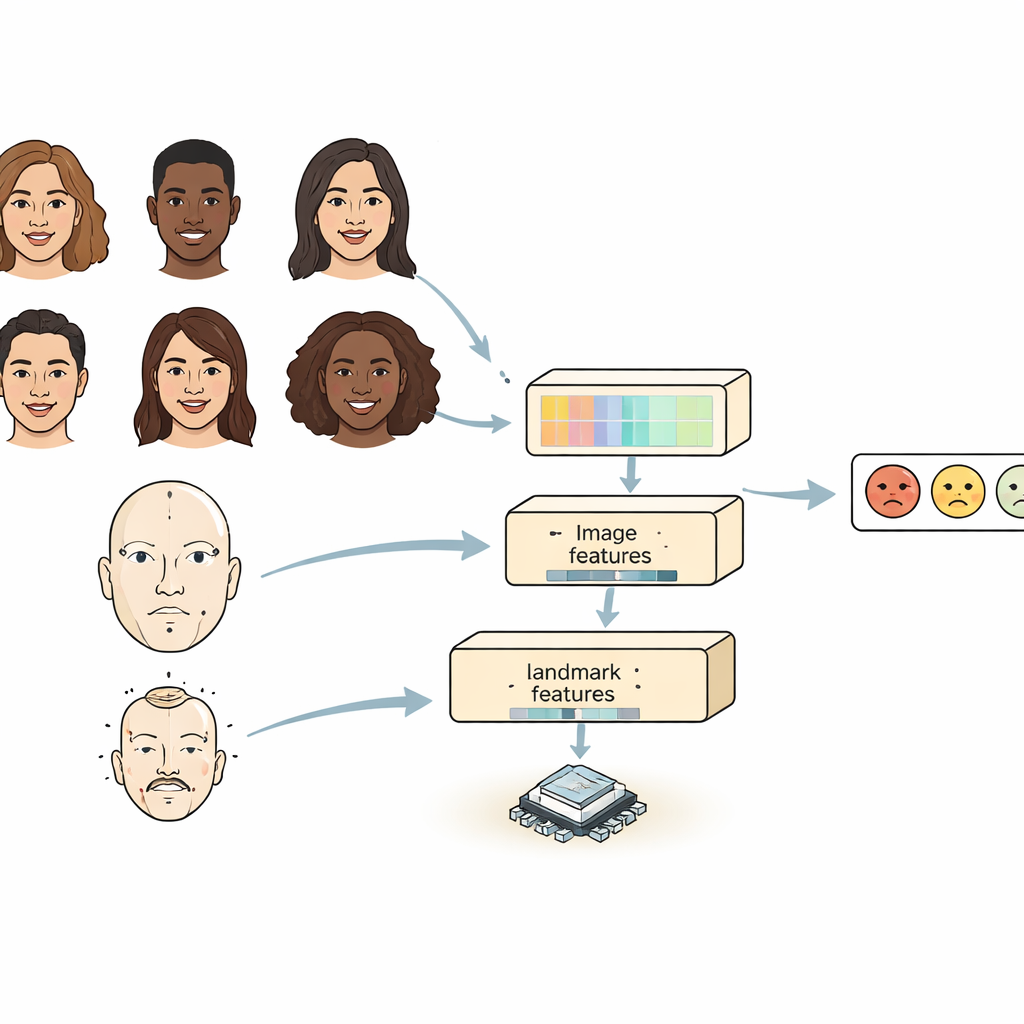
Zowel kleine details als het grote geheel vastleggen
Nadat basiskenmerken zijn geëxtraheerd, leidt FERMam ze door een speciaal module genaamd Conv-SSM. Het ene pad in dit module gedraagt zich als een traditioneel convolutioneel netwerk en verscherpt fijne details zoals randen en texturen rond de ogen en mond. Het andere pad gebruikt een nieuwere familie modellen die bekend staat als state-space-modellen, in het bijzonder een variant genaamd Mamba. In plaats van elk deel van de afbeelding met elk ander deel te vergelijken, "scan"t Mamba over het gezicht in meerdere richtingen en bouwt zo een geheugen op van hoe kenmerken zich van plaats tot plaats veranderen. Dit stelt het systeem in staat langeafstandsrelaties vast te leggen — bijvoorbeeld hoe een opgetrokken wenkbrauw en een gespannen mond samen woede kunnen signaleren — terwijl de rekenkosten beheersbaar blijven. De uitgangen van deze twee paden worden vervolgens slim gehusseld en opnieuw gecombineerd zodat lokale en globale informatie met elkaar kunnen interageren.
Informatie over verschillende schalen mengen
Emoties kunnen verschijnen als kleine veranderingen in een klein gebied of als brede verschuivingen over het hele gezicht. Om hiermee om te gaan gebruikt FERMam een piramide-fusiestructuur. Het maakt verschillende versies van de featuremap op uiteenlopende resoluties, van grof tot fijn, en verwerkt elk niveau met een Adaptive State-space Feature Refinement-module. Op elke schaal versterkt deze module belangrijke lokale patronen via lichtgewicht convoluties en gebruikt vervolgens een gestroomlijnde state-space scan om verre regio’s te koppelen. Een ingebouwd gate-mechanisme kan signalen van expressierijke gebieden, zoals ogen en mond, versterken terwijl afleidingen uit de achtergrond of identiteitsspecifieke details worden onderdrukt. Na verfijning wordt de informatie van alle schalen weer samengebracht, waardoor een rijke maar compacte samenvatting ontstaat die uiteindelijk naar een kleine classifier gaat om te beslissen welke emotie wordt weergegeven.
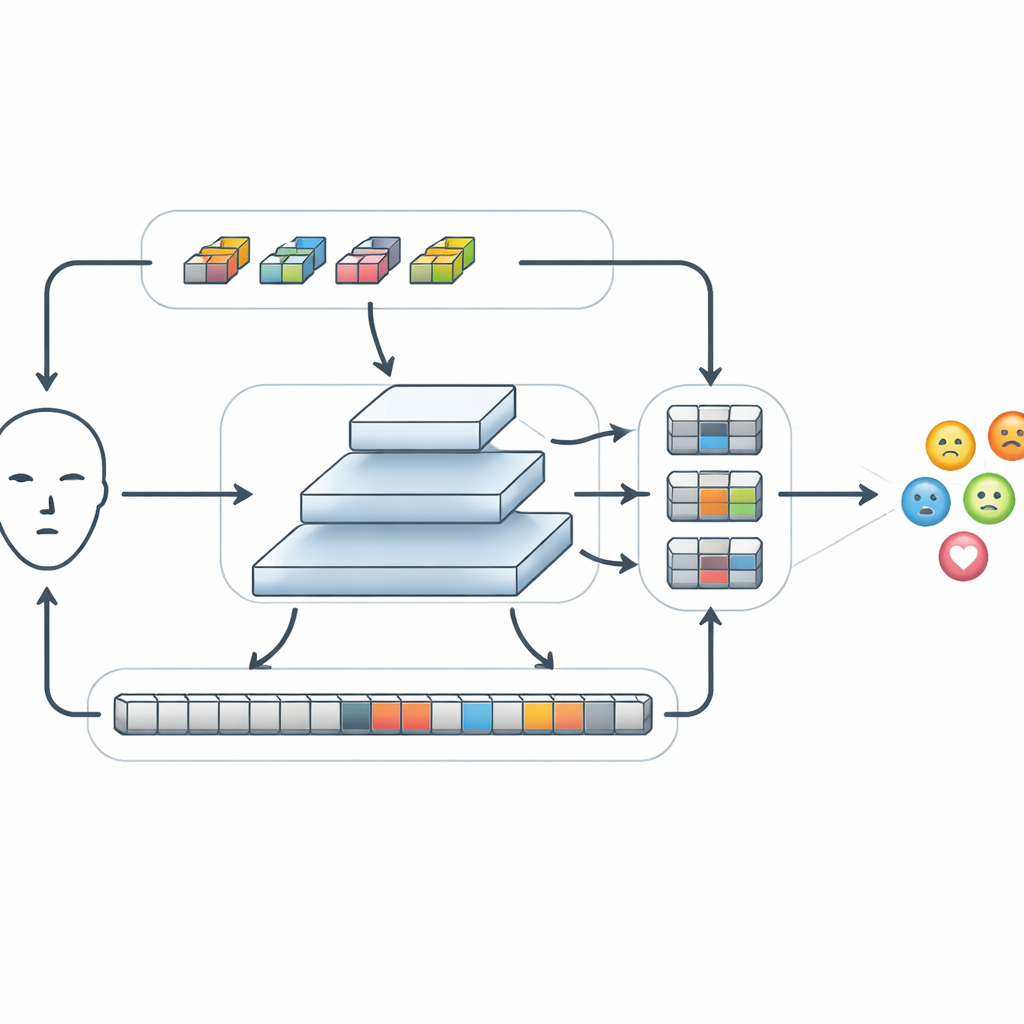
Krachtige modellen matchen met veel minder rekenkracht
De auteurs testten FERMam op drie belangrijke benchmarks voor gezichtsuitdrukkingen: RAF-DB, AffectNet en FERPlus. Deze datasets bevatten tienduizenden tot honderdduizenden gezichten uit realistische omstandigheden, met gevarieerde verlichting, leeftijden en poses. Op deze datasets bereikte FERMam nauwkeurigheidsniveaus die dicht bij of beter waren dan veel toonaangevende methoden die op zware transformer-architecturen vertrouwen. Op één veelgebruikt dataset benadert de prestatie bijna het beste gepubliceerde transformer-gebaseerde systeem, terwijl het ongeveer een derde tot de helft van het aantal parameters gebruikt en veel minder bewerkingen vereist. In de praktijk betekent dit dat FERMam meer dan twee keer zo snel kan draaien, veel meer beelden per seconde in batchmodus kan verwerken en toch een hoge herkenningskwaliteit behoudt. Ablatie-studies — gecontroleerde experimenten waarin onderdelen van het ontwerp worden verwijderd — tonen aan dat elk component, van de landmark-tak tot de piramide-fusie, een betekenisvolle rol speelt in dit evenwicht.
Wat dit betekent voor alledaagse technologieën
Eenvoudig gezegd laat de studie zien dat het mogelijk is een emotieherkenningssysteem te bouwen dat zowel slim als zuinig is. Door twee gezichtszichten te combineren — hoe het eruitziet en hoe het gevormd is — en door zorgvuldig te organiseren hoe informatie stroomt over ruimte en schaal, bereikt FERMam sterke herkenning zonder een supercomputer te vereisen. Dat maakt het een veelbelovende kandidaat voor gebruik in telefoons, huishoudrobots, camera’s voor bestuurdersassistentie en andere apparaten die in realtime gevoelig op menselijke emoties moeten reageren. Hoewel toekomstig werk nog zwaardere omstandigheden zal moeten aanpakken, zoals sterke occlusie of zeer lage resolutie afbeeldingen, wijst FERMam de weg naar praktische, efficiënte en meer mensgerichte computing.
Bronvermelding: Gao, C., Ji, X., Zhang, Q. et al. FERMam: a lightweight dual-source and multi-scale fusion framework for facial expression recognition. Sci Rep 16, 13826 (2026). https://doi.org/10.1038/s41598-026-44396-6
Trefwoorden: herkenning van gezichtsuitdrukkingen, emotie-bewuste AI, lichtgewicht deep learning, state-space-modellen, mens-computerinteractie