Clear Sky Science · pl
FERMam: lekka ramowa metoda fuzji wieloźródłowej i wieloskalowej do rozpoznawania mimiki
Dlaczego warto uczyć komputery czytania twarzy
Nasze telefony, samochody i urządzenia domowe coraz lepiej rozumieją, co mówimy, ale wciąż mają trudności z wyczuwaniem, co czujemy. Rozpoznawanie mimiki ma to zmienić, pozwalając maszynom „czytać” ludzkie emocje z twarzy na zdjęciach lub wideo. Może to uczynić zajęcia online bardziej reagującymi, systemy monitorowania kierowców bezpieczniejszymi, a roboty społeczne bardziej naturalnymi w interakcji. Wyzwanie polega na wykonywaniu tego dokładnie i szybko na codziennych urządzeniach, takich jak telefony, tablety czy roboty serwisowe, które nie dysponują mocą dużego centrum danych. Artykuł przedstawia FERMam — nową metodę zaprojektowaną tak, by wiarygodnie odczytywać wyrazy twarzy przy znacznie niższym zapotrzebowaniu na obliczenia niż wiele obecnych systemów.
Postrzeganie twarzy z dwóch użytecznych perspektyw
Większość istniejących systemów patrzy na twarz na jeden z dwóch sposobów. Sieci konwolucyjne dobrze wychwytują lokalne detale, takie jak zmarszczki czy kształt brwi, ale mają problem z powiązaniami między odległymi częściami twarzy. Modele oparte na transformatorach dobrze uchwytują relacje na dużą skalę, ale są ciężkie i wolne, co utrudnia ich uruchomienie na małych urządzeniach. FERMam łączy zalety obu podejść w projekcie „dual-source”. Jedna gałąź koncentruje się na ogólnym wyglądzie twarzy, używając wydajnego enkodera obrazu. Druga śledzi kluczowe punkty na twarzy — punkty wokół oczu, ust i innych istotnych obszarów. Te punkty podkreślają geometrię twarzy, która zwykle pozostaje stabilna mimo zmian oświetlenia, koloru skóry czy tła. Łącząc wygląd i geometrię, FERMam może skupić się na subtelnych obszarach, w których emocje faktycznie się ujawniają.
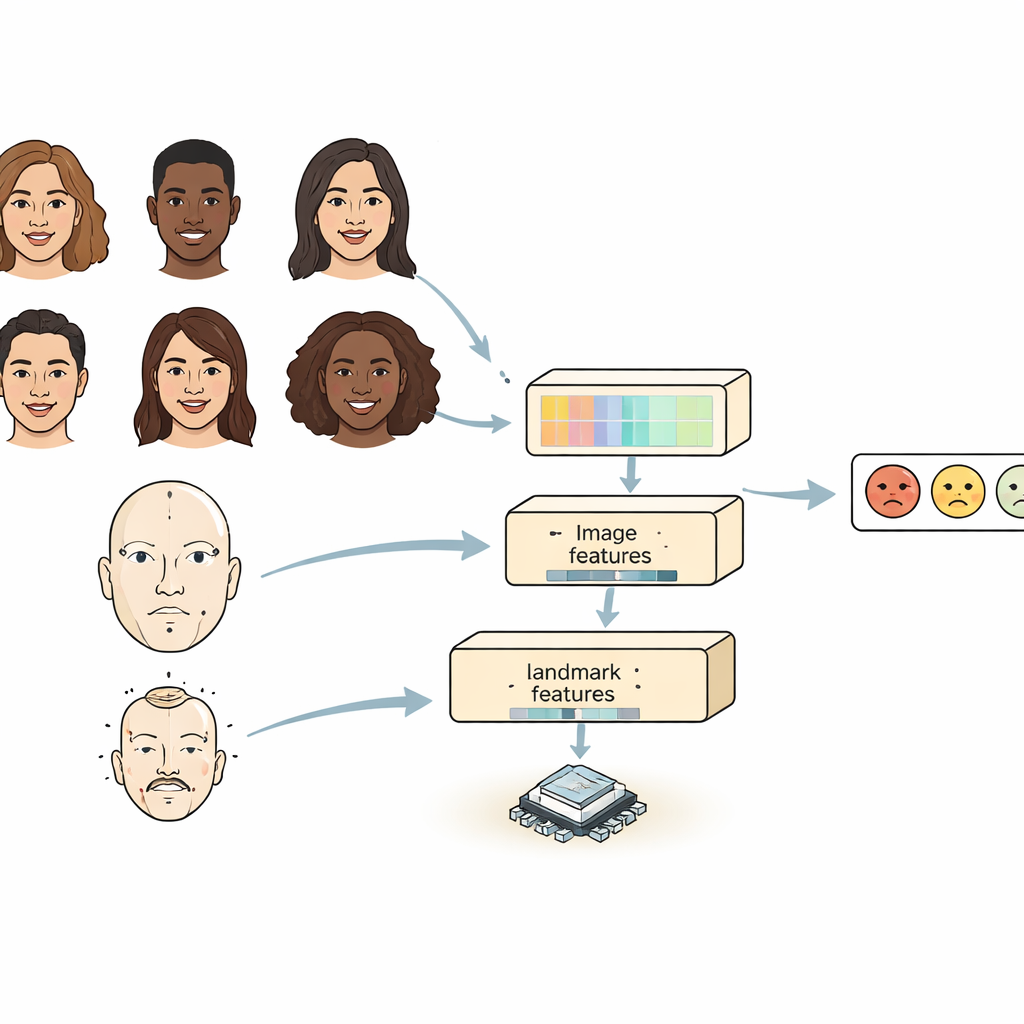
Uchwycenie zarówno drobnych detali, jak i szerokiego kontekstu
Po wydobyciu podstawowych cech FERMam przepuszcza je przez specjalny moduł nazwany Conv-SSM. Jedna ścieżka w tym module działa jak tradycyjna sieć konwolucyjna, wyostrza drobne detale, takie jak krawędzie i tekstury wokół oczu i ust. Druga ścieżka wykorzystuje nowszą rodzinę modeli znanych jako modele przestrzeni stanu, w szczególności wariant o nazwie Mamba. Zamiast porównywać każdą część obrazu z każdą inną, Mamba „skanuje” twarz w kilku kierunkach, budując pamięć o tym, jak cechy zmieniają się w przestrzeni. Pozwala to systemowi uchwycić relacje na dużą odległość, na przykład jak uniesione brew i ściągnięte usta razem mogą sygnalizować złość, przy jednoczesnym kontrolowaniu kosztu obliczeniowego. Wyjścia z obu ścieżek są następnie sprytnie przetasowane i ponownie połączone, tak aby informacje lokalne i globalne mogły ze sobą oddziaływać.
Fuzja informacji na różnych skalach
Emocje mogą ujawniać się jako drobne zmiany w niewielkim obszarze lub jako szerokie przesunięcia na całej twarzy. Aby to obsłużyć, FERMam wykorzystuje strukturę piramidy fuzji. Tworzy kilka wersji mapy cech o różnych rozdzielczościach, od współrzędnych grubych do drobnych, i przetwarza każdy poziom za pomocą modułu Adaptive State-space Feature Refinement. Na każdej skali moduł ten wzmacnia istotne wzorce lokalne przez lekką konwolucję, a następnie używa uproszczonego skanowania przestrzeni stanu, aby połączyć odległe obszary. Wbudowany mechanizm bramek może wzmocnić sygnały z obszarów bogatych w ekspresję, takich jak oczy i usta, jednocześnie tłumiąc zakłócenia pochodzące z tła lub szczegółów identycznościowych. Po refinamencie informacje ze wszystkich skal są ponownie scalane, tworząc bogate, a jednocześnie zwarte podsumowanie, które ostatecznie trafia do małego klasyfikatora decydującego o pokazywanej emocji.
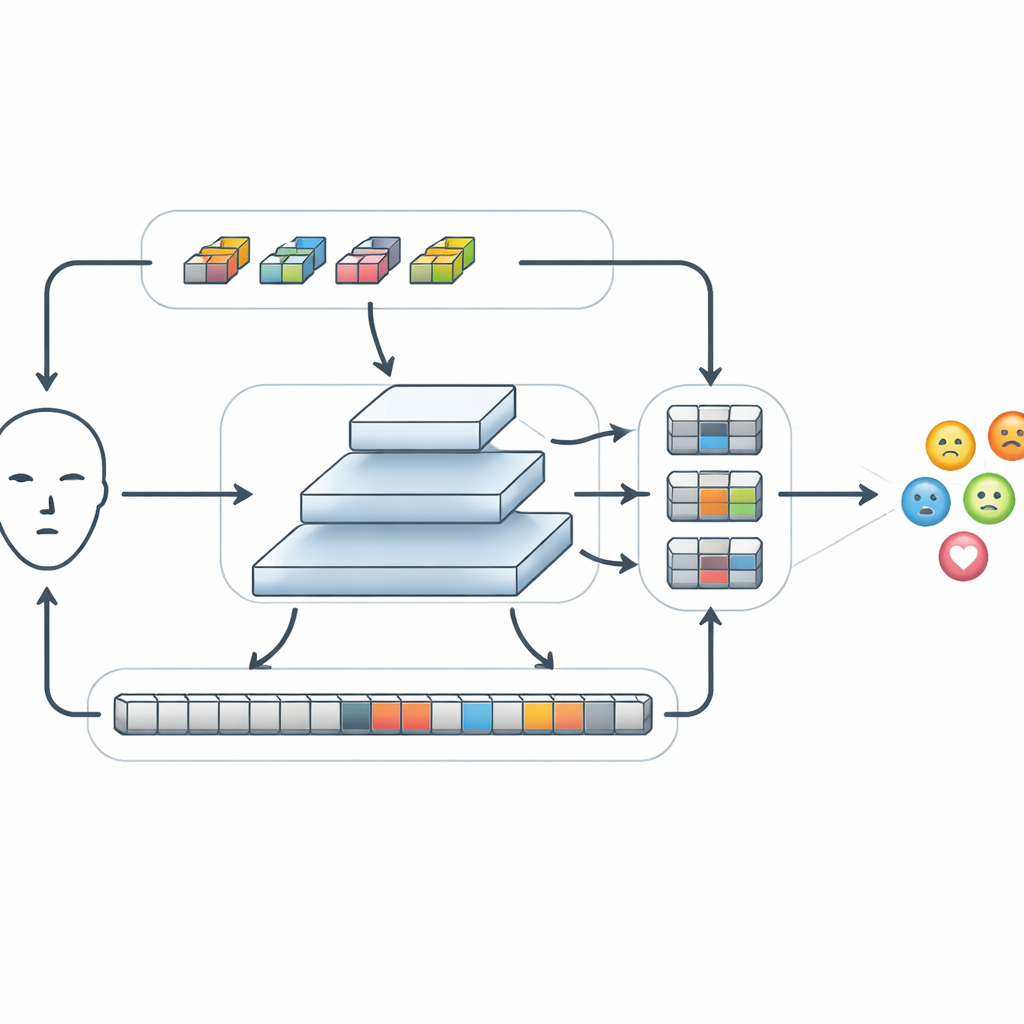
Dopasowanie wydajnych modeli przy znacznie niższym koszcie obliczeniowym
Autorzy przetestowali FERMam na trzech głównych benchmarkach rozpoznawania mimiki: RAF-DB, AffectNet i FERPlus. Zbiory te zawierają dziesiątki do setek tysięcy twarzy pochodzących z warunków rzeczywistych, obejmujących zróżnicowane oświetlenie, wiek i pozy. Na tych danych FERMam osiągnął poziomy dokładności zbliżone do, a w niektórych przypadkach lepsze niż wiele czołowych metod opartych na ciężkich architekturach transformatorowych. Na jednym szeroko stosowanym zbiorze jego wydajność niemal dorównuje najlepszemu opublikowanemu systemowi opartemu na transformatorach, przy jednoczesnym wykorzystaniu około jednej trzeciej do połowy liczby parametrów i znacznie mniejszej liczby operacji. W praktyce oznacza to, że FERMam może działać ponad dwukrotnie szybciej, przetwarzać znacznie więcej obrazów na sekundę w trybie wsadowym i nadal utrzymywać wysoką jakość rozpoznawania. Badania ablationowe — kontrolowane eksperymenty, w których usuwane są części projektu — pokazują, że każdy element, od gałęzi punktów charakterystycznych po piramidalną fuzję, odgrywa istotną rolę w tej równowadze.
Co to oznacza dla technologii codziennego użytku
Mówiąc prosto, badanie pokazuje, że można zbudować system czytania emocji, który jest jednocześnie inteligentny i oszczędny. Łącząc dwa spojrzenia na twarz — jak wygląda i jak jest ukształtowana — oraz starannie organizując przepływ informacji w przestrzeni i skali, FERMam osiąga silne rozpoznawanie bez potrzeby superkomputera. To czyni go obiecującym kandydatem do zastosowania w telefonach, robotach domowych, kamerach wspomagających kierowcę i innych urządzeniach, które muszą w czasie rzeczywistym wrażliwie reagować na ludzkie emocje. Prace przyszłe będą musiały zmierzyć się z trudniejszymi warunkami, takimi jak silne zasłonięcia czy bardzo niska rozdzielczość obrazów, ale FERMam wskazuje drogę ku praktycznym, wydajnym i bardziej świadomym emocjonalnie systemom obliczeniowym.
Cytowanie: Gao, C., Ji, X., Zhang, Q. et al. FERMam: a lightweight dual-source and multi-scale fusion framework for facial expression recognition. Sci Rep 16, 13826 (2026). https://doi.org/10.1038/s41598-026-44396-6
Słowa kluczowe: rozpoznawanie mimiki, AI rozumiejąca emocje, lekka głęboka nauka, modele przestrzeni stanu, interakcja człowiek–komputer