Clear Sky Science · ru
FERMam: легковесная двухисточниковая и мульти масштабная схема слияния для распознавания выражений лица
Почему важно научить компьютеры «читать» лицо
Наши телефоны, автомобили и бытовые устройства становятся всё лучше в понимании сказанного нами, но им по‑прежнему трудно уловить, что мы чувствуем. Распознавание выражений лица стремится это изменить, позволяя машинам «прочитывать» человеческие эмоции по лицу на фото или видео. Это может сделать онлайн‑занятия более адаптивными, системы мониторинга водителя — безопаснее, а социальных роботов — более естественными для общения. Задача — выполнить это точно и быстро на повседневных устройствах, таких как телефоны, планшеты и сервисные роботы, которые не обладают мощью большого дата‑центра. В этой статье представлена FERMam — новый метод, спроектированный для надёжного распознавания выражений при значительно меньших вычислительных затратах по сравнению с многими современными системами.
Рассматривать лицо с двух полезных точек зрения
Большинство существующих решений смотрят на лицо одним из двух способов. Сверточные нейронные сети хорошо выявляют локальные детали, такие как морщины или форма бровей, но им трудно уловить взаимосвязи между дальними участками лица. Трансформерные модели захватывают дальние зависимости, но тяжелы и медленны, что затрудняет их запуск на небольших устройствах. FERMam объединяет сильные стороны обоих подходов в «двухисточниковой» конструкции. Одна ветвь сосредоточена на общем внешнем виде лица и использует мощный, но эффективный энкодер изображений. Другая ветвь отслеживает ключевые лицевые маркеры — точки вокруг глаз, рта и других важных областей. Эти маркеры подчёркивают геометрию лица, которая остаётся стабильной даже при смене освещения, тонома кожи или фона. Смешивая внешность и геометрию, FERMam может концентрироваться на тех тонких участках, где эмоции проявляются особенно явно.
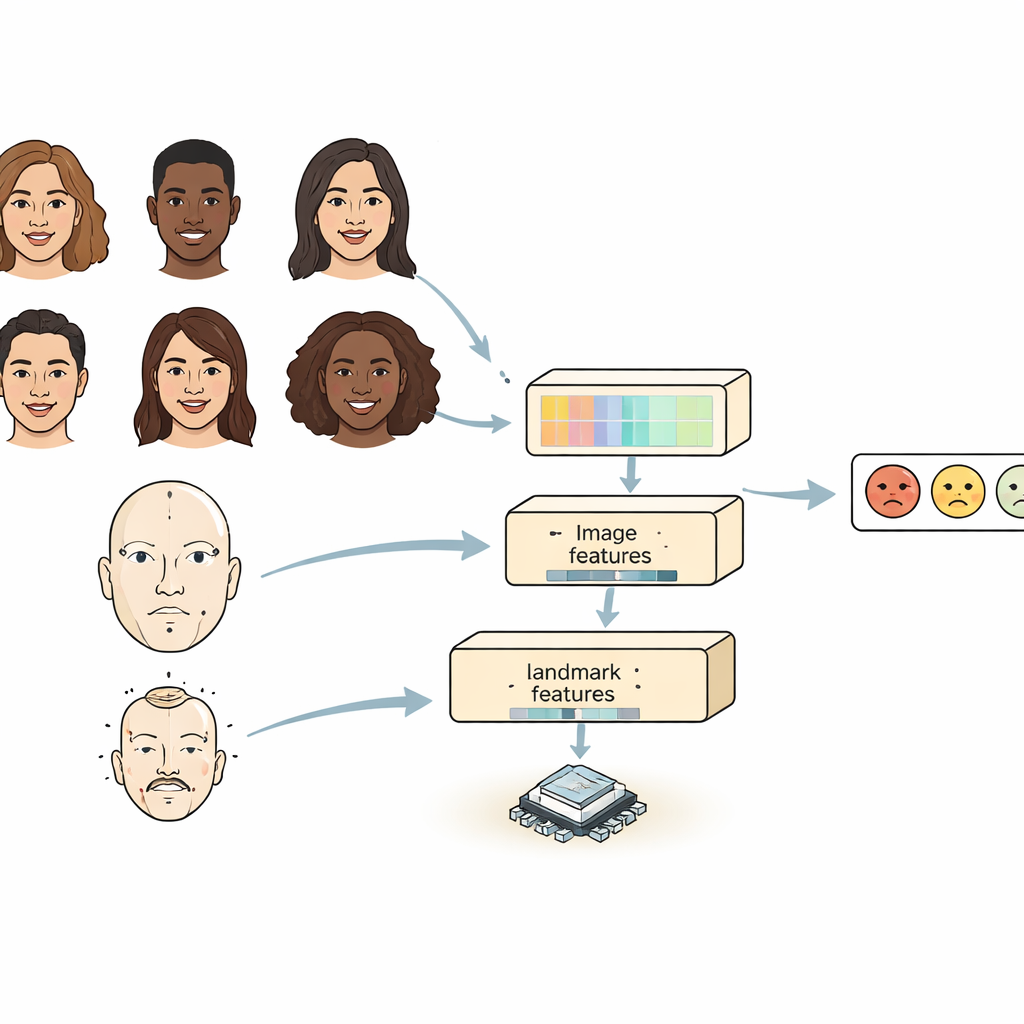
Фиксация мелких деталей и общей картины
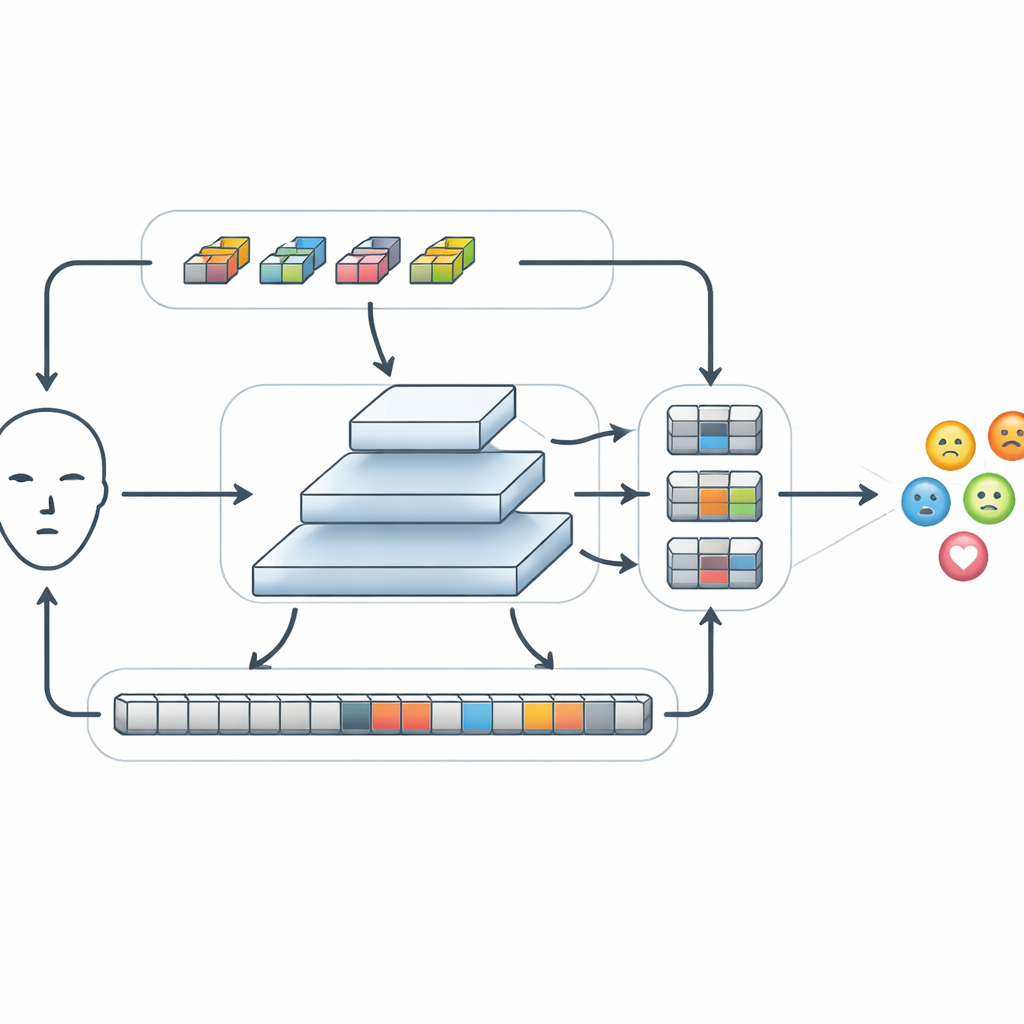
После извлечения базовых признаков FERMam пропускает их через специальный модуль под названием Conv-SSM. Один путь в этом модуле ведёт себя как традиционная сверточная сеть, подчёркивая тонкие детали — края и текстуры вокруг глаз и рта. Другой путь использует более новую семью моделей, известных как модели в пространстве состояний, а именно вариант под названием Mamba. Вместо того чтобы сравнивать каждую часть изображения с каждой другой, Mamba «сканирует» лицо в нескольких направлениях, накапливая память о том, как признаки изменяются от места к месту. Это позволяет системе захватывать дальние взаимосвязи — например, как поднятая бровь вместе со сжатым ртом может сигнализировать об гневе — при этом контролируя вычислительные затраты. Выходы этих двух путей затем хитро переставляются и комбинируются, давая возможность локальной и глобальной информации взаимодействовать.
Слияние информации на разных масштабах
Эмоции могут проявляться как в крошечных изменениях в небольшой области, так и в широких сдвигах по всему лицу. Чтобы справляться с этим, FERMam использует пирамидальную структуру слияния. Она создаёт несколько версий карты признаков на разных разрешениях — от грубых к детальным — и обрабатывает каждый уровень с помощью модуля Adaptive State-space Feature Refinement. На каждом масштабе этот модуль усиливает важные локальные паттерны через лёгкую свёртку, а затем использует упрощённое сканирование в пространстве состояний, чтобы связать отдалённые участки. Встроенный механизм гейтинга может усиливать сигналы из областей, богатых выражениями, таких как глаза и рот, одновременно ослабляя помехи от фона или особенностей личности. После уточнения информация со всех масштабов снова объединяется, формируя богатое, но компактное представление, которое в финале передаётся небольшому классификатору для определения демонстрируемой эмоции.
Сопоставимая мощь при гораздо меньших вычислениях
Авторы протестировали FERMam на трёх крупных бенчмарках по распознаванию выражений лица: RAF-DB, AffectNet и FERPlus. Эти наборы данных содержат десятки и сотни тысяч лиц, собранных в реальных условиях с разным освещением, возрастами и позами. На этих датасетах FERMam достиг точности, близкой к или превосходящей многие передовые методы, опирающиеся на тяжёлые трансформеры. На одном широко используемом наборе его результат почти сопоставим с лучшей опубликованной трансформерной системой, при этом он использует примерно в три — два раза меньше параметров и значительно меньше операций. На практике это означает, что FERMam может работать более чем вдвое быстрее, обрабатывать в пакетном режиме значительно больше изображений в секунду и при этом сохранять высокое качество распознавания. Абляционные исследования — контролируемые эксперименты с удалением частей конструкции — показывают, что каждый компонент, от ветви с маркерами до пирамидального слияния, вносит значимый вклад в этот баланс.
Что это значит для повседневных технологий
Проще говоря, исследование показывает, что возможно создать систему чтения эмоций, которая одновременно умна и экономна. Комбинируя два взгляда на лицо — как оно выглядит и каково его строение — и осторожно организуя поток информации по пространству и масштабам, FERMam достигает высокой точности распознавания без требований к суперкопьютеру. Это делает её многообещающим кандидатом для использования в телефонах, домашних роботах, камерах помощи водителю и других устройствах, которым нужно чувствительно реагировать на эмоции человека в реальном времени. Хотя в будущей работе придётся решать более экстремальные условия, такие как сильное перекрытие лица или очень низкое разрешение, FERMam указывает путь к практичному, эффективному и более «человекоориентированному» вычислительному подходу.
Цитирование: Gao, C., Ji, X., Zhang, Q. et al. FERMam: a lightweight dual-source and multi-scale fusion framework for facial expression recognition. Sci Rep 16, 13826 (2026). https://doi.org/10.1038/s41598-026-44396-6
Ключевые слова: распознавание выражений лица, ИИ, чувствующий эмоции, легковесное глубокое обучение, модели в пространстве состояний, взаимодействие человек–компьютер