Clear Sky Science · es
FERMam: un marco ligero de fusión de doble fuente y multi-escala para el reconocimiento de expresiones faciales
Por qué importa enseñar a los ordenadores a leer rostros
Nuestros teléfonos, coches y dispositivos domésticos están mejorando en comprender lo que decimos, pero aún les cuesta captar cómo nos sentimos. El reconocimiento de expresiones faciales pretende cambiar eso permitiendo que las máquinas "lean" las emociones humanas a partir de caras en fotos o vídeo. Esto podría hacer que las clases online sean más receptivas, que los sistemas de supervisión del conductor sean más seguros y que los robots sociales resulten más naturales al interactuar. El reto es hacerlo con precisión y rapidez en dispositivos cotidianos como teléfonos, tabletas y robots de servicio que no disponen de la potencia de un gran centro de datos. Este artículo presenta FERMam, un nuevo método diseñado para leer expresiones de forma fiable utilizando mucha menos potencia de cálculo que muchos sistemas actuales.
Ver el rostro desde dos puntos de vista complementarios
La mayoría de los sistemas existentes observan una cara de una de dos maneras. Las redes convolucionales son buenas detectando detalles locales como arrugas o la forma de las cejas, pero tienen dificultades para ver cómo se relacionan partes distantes del rostro. Los modelos basados en transformadores capturan bien las relaciones a larga distancia pero son pesados y lentos, lo que dificulta ejecutarlos en dispositivos pequeños. FERMam combina las fortalezas de ambos enfoques con un diseño de "doble fuente". Una rama se centra en la apariencia global del rostro, usando un codificador de imágenes potente pero eficiente. La otra rama sigue puntos clave del rostro —marcadores alrededor de los ojos, la boca y otras regiones importantes—. Estos marcadores enfatizan la geometría facial, que tiende a mantenerse estable incluso cuando cambian la iluminación, el tono de piel o el fondo. Al mezclar apariencia y geometría, FERMam puede centrarse en las regiones sutiles donde las emociones se manifiestan realmente.
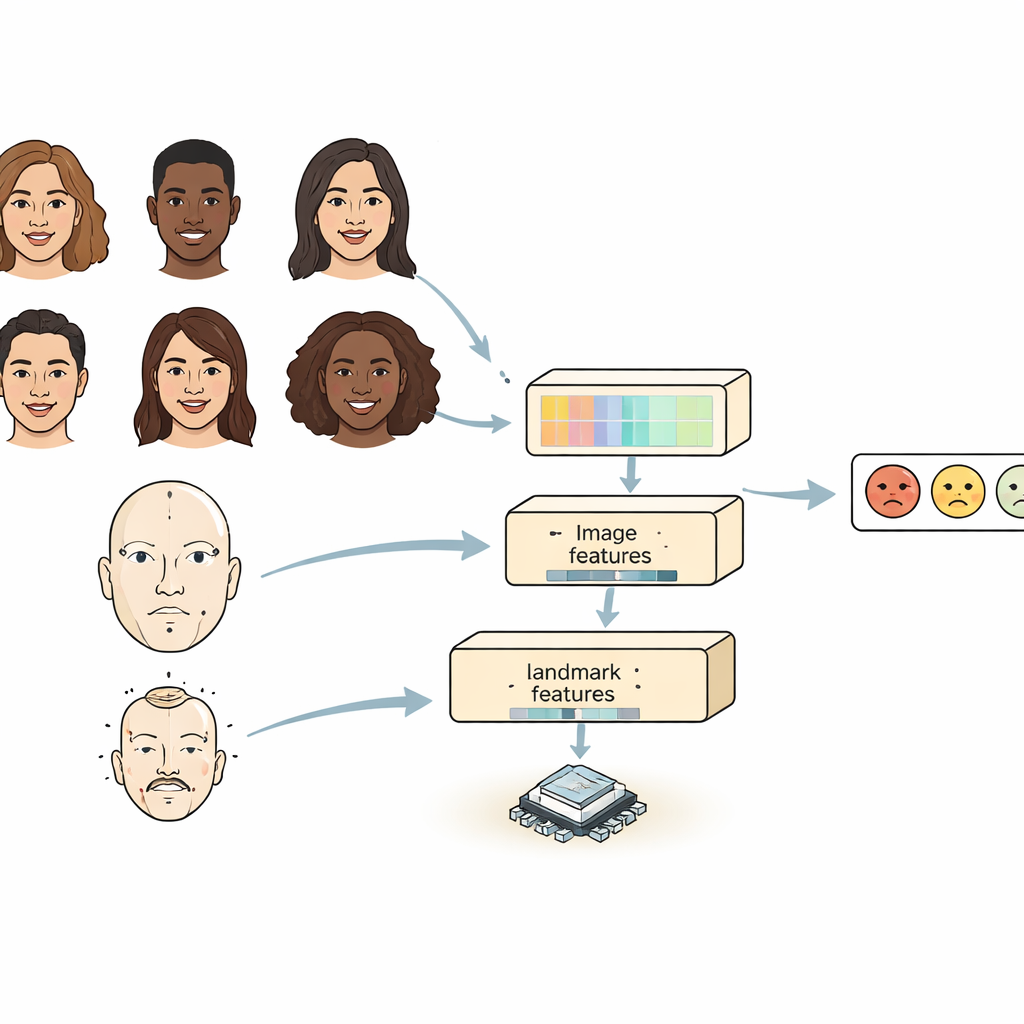
Capturar tanto los pequeños detalles como la visión de conjunto
Tras extraer las características básicas, FERMam las pasa por un módulo especial llamado Conv-SSM. Un camino en este módulo actúa como una red convolucional tradicional, agudizando detalles finos como bordes y texturas alrededor de los ojos y la boca. El otro camino utiliza una familia más reciente de modelos conocida como modelos de espacio de estados, en particular una variante llamada Mamba. En lugar de comparar cada parte de la imagen con todas las demás, Mamba "explora" el rostro en varias direcciones, construyendo una memoria de cómo cambian las características de un lugar a otro. Esto permite al sistema capturar relaciones a larga distancia, por ejemplo cómo una ceja levantada y una boca tensada juntas pueden señalar ira, al tiempo que mantiene controlado el coste computacional. Las salidas de estos dos caminos se entrelazan y recombinan de forma ingeniosa para que la información local y global pueda interactuar.
Mezclar información a través de distintas escalas
Las emociones pueden aparecer como cambios minúsculos en una región pequeña o como variaciones amplias en todo el rostro. Para manejar esto, FERMam utiliza una estructura de fusión en pirámide. Crea varias versiones del mapa de características a diferentes resoluciones, de grueso a fino, y procesa cada nivel con un módulo de Refinamiento Adaptativo de Características de Espacio de Estados. En cada escala, este módulo refuerza patrones locales importantes mediante convoluciones ligeras y luego usa un escaneo de espacio de estados optimizado para vincular regiones distantes. Un mecanismo de compuertas integrado puede potenciar señales procedentes de áreas ricas en expresión, como ojos y boca, mientras atenúa distracciones del fondo o detalles específicos de identidad. Tras el refinamiento, la información de todas las escalas se reúne, formando un resumen denso pero compacto que finalmente pasa a un clasificador pequeño para decidir qué emoción se muestra.
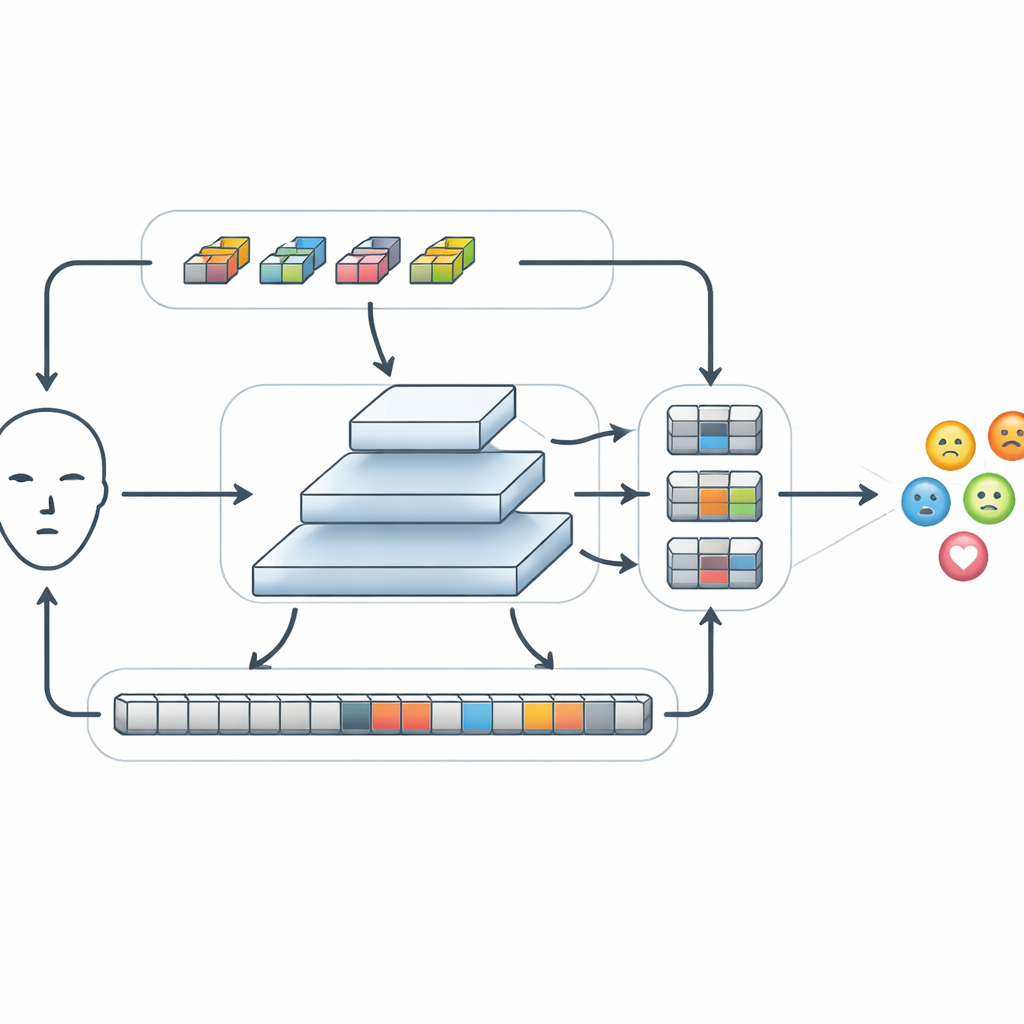
Igualar a modelos potentes con mucha menos computación
Los autores probaron FERMam en tres conjuntos de referencia principales para expresiones faciales: RAF-DB, AffectNet y FERPlus. Estas colecciones contienen decenas a cientos de miles de caras extraídas de condiciones reales, incluyendo variaciones de iluminación, edades y poses. En estos conjuntos, FERMam alcanzó niveles de precisión cercanos o superiores a muchos métodos líderes que dependen de arquitecturas transformadoras pesadas. En un conjunto de datos ampliamente usado, su rendimiento casi iguala al mejor sistema publicado basado en transformadores, pero utiliza aproximadamente entre un tercio y la mitad de parámetros y muchas menos operaciones. En la práctica, esto significa que FERMam puede ejecutarse más de dos veces más rápido, procesar muchas más imágenes por segundo en modo por lotes y mantener una alta calidad de reconocimiento. Los estudios de ablación —experimentos controlados en los que se eliminan partes del diseño— muestran que cada componente, desde la rama de marcadores hasta la fusión en pirámide, desempeña un papel relevante en este equilibrio.
Qué significa esto para las tecnologías cotidianas
En términos sencillos, el estudio demuestra que es posible construir un sistema lector de emociones que sea a la vez inteligente y austero en recursos. Al combinar dos miradas del rostro —cómo se ve y cómo está formado— y al organizar cuidadosamente el flujo de información a través del espacio y la escala, FERMam logra un reconocimiento sólido sin exigir un superordenador. Esto lo convierte en un candidato prometedor para su uso en teléfonos, robots domésticos, cámaras de asistencia al conductor y otros dispositivos que necesitan responder con sensibilidad a las emociones humanas en tiempo real. Si bien trabajos futuros deberán abordar condiciones más extremas, como oclusiones severas o imágenes de muy baja resolución, FERMam apunta el camino hacia una informática práctica, eficiente y más consciente del factor humano.
Cita: Gao, C., Ji, X., Zhang, Q. et al. FERMam: a lightweight dual-source and multi-scale fusion framework for facial expression recognition. Sci Rep 16, 13826 (2026). https://doi.org/10.1038/s41598-026-44396-6
Palabras clave: reconocimiento de expresiones faciales, IA sensible a las emociones, aprendizaje profundo ligero, modelos de espacio de estados, interacción humano–computadora