Clear Sky Science · pt
FERMam: uma estrutura leve de fusão multi-fonte e multi-escala para reconhecimento de expressão facial
Por que ensinar computadores a ler rostos importa
Nossos telefones, carros e dispositivos domésticos estão ficando melhores em entender o que dizemos, mas ainda têm dificuldade em perceber como nos sentimos. O Reconhecimento de Expressão Facial busca mudar isso ao permitir que máquinas “leiam” emoções humanas a partir de rostos em fotos ou vídeos. Isso pode tornar aulas online mais responsivas, sistemas de monitoramento de motoristas mais seguros e robôs sociais mais naturais de interagir. O desafio é fazer isso com precisão e rapidez em dispositivos do dia a dia — como telefones, tablets e robôs de serviço — que não dispõem do poder de um grande centro de dados. Este artigo apresenta o FERMam, um novo método projetado para ler expressões de forma confiável usando muito menos poder de computação do que muitos sistemas atuais.
Ver o rosto a partir de duas perspectivas úteis
A maioria dos sistemas existentes observa um rosto de uma de duas maneiras. Redes neurais convolucionais são boas em identificar detalhes locais, como rugas ou formato das sobrancelhas, mas têm dificuldade em perceber como partes distantes do rosto se relacionam entre si. Modelos baseados em transformers capturam bem relações de longo alcance, mas são pesados e lentos, dificultando sua execução em dispositivos pequenos. O FERMam combina as forças de ambos com um projeto “de fonte dupla”. Um ramo concentra-se na aparência geral do rosto, usando um codificador de imagem potente porém eficiente. O outro ramo acompanha marcos faciais — pontos ao redor dos olhos, da boca e outras regiões importantes. Esses marcos enfatizam a geometria do rosto, que tende a se manter estável mesmo quando mudam iluminação, tom de pele ou fundo. Ao misturar aparência e geometria, o FERMam pode focar nas regiões sutis onde as emoções realmente se manifestam.
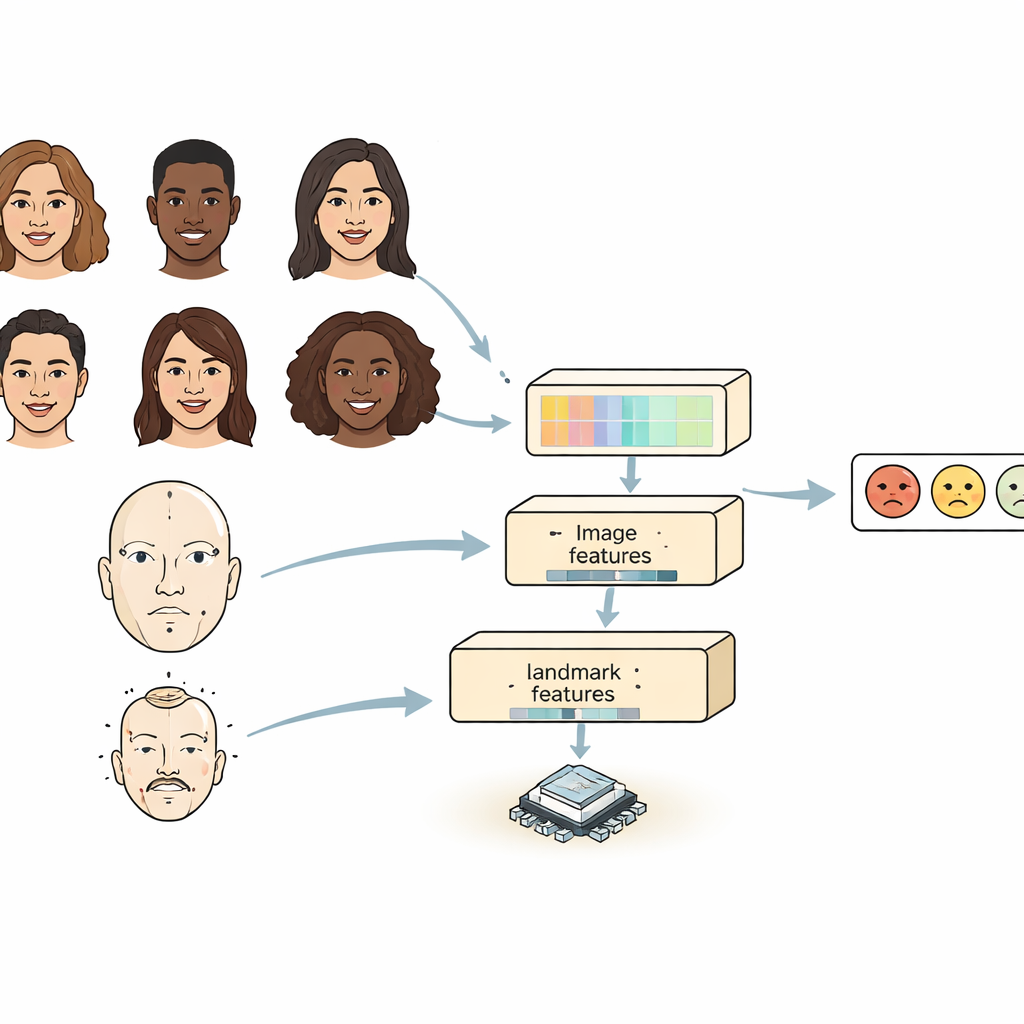
Capturando tanto detalhes pequenos quanto a visão global
Depois que características básicas são extraídas, o FERMam as processa por um módulo especial chamado Conv-SSM. Um caminho nesse módulo se comporta como uma rede convolucional tradicional, acentuando detalhes finos, como bordas e texturas ao redor dos olhos e da boca. O outro caminho usa uma família mais recente de modelos conhecida como modelos de espaço de estado, em particular uma variante chamada Mamba. Em vez de comparar cada parte da imagem com todas as outras, o Mamba “varre” o rosto em várias direções, construindo uma memória de como as características mudam de um ponto a outro. Isso permite ao sistema capturar relações de longo alcance — por exemplo, como uma sobrancelha levantada e uma boca contraída juntas podem sinalizar raiva — ao mesmo tempo em que mantém o custo computacional sob controle. As saídas desses dois caminhos são então inteligentemente embaralhadas e recombinadas para que informação local e global possam interagir.
Misturando informações através de diferentes escalas
As emoções podem aparecer como pequenas alterações em uma região reduzida ou como mudanças amplas em todo o rosto. Para lidar com isso, o FERMam usa uma estrutura de fusão em pirâmide. Ele cria várias versões do mapa de características em diferentes resoluções, do grosso ao fino, e processa cada nível com um módulo de Refinamento de Características por Espaço de Estado Adaptativo. Em cada escala, esse módulo fortalece padrões locais importantes por meio de convolução leve e então usa uma varredura de espaço de estado simplificada para conectar regiões distantes. Um mecanismo de gating embutido pode aumentar sinais de áreas ricas em expressão, como olhos e boca, enquanto reduz distrações vindas do plano de fundo ou de detalhes específicos de identidade. Após o refinamento, a informação de todas as escalas é reunida, formando um resumo rico porém compacto que é finalmente passado a um classificador pequeno para decidir qual emoção está sendo mostrada.
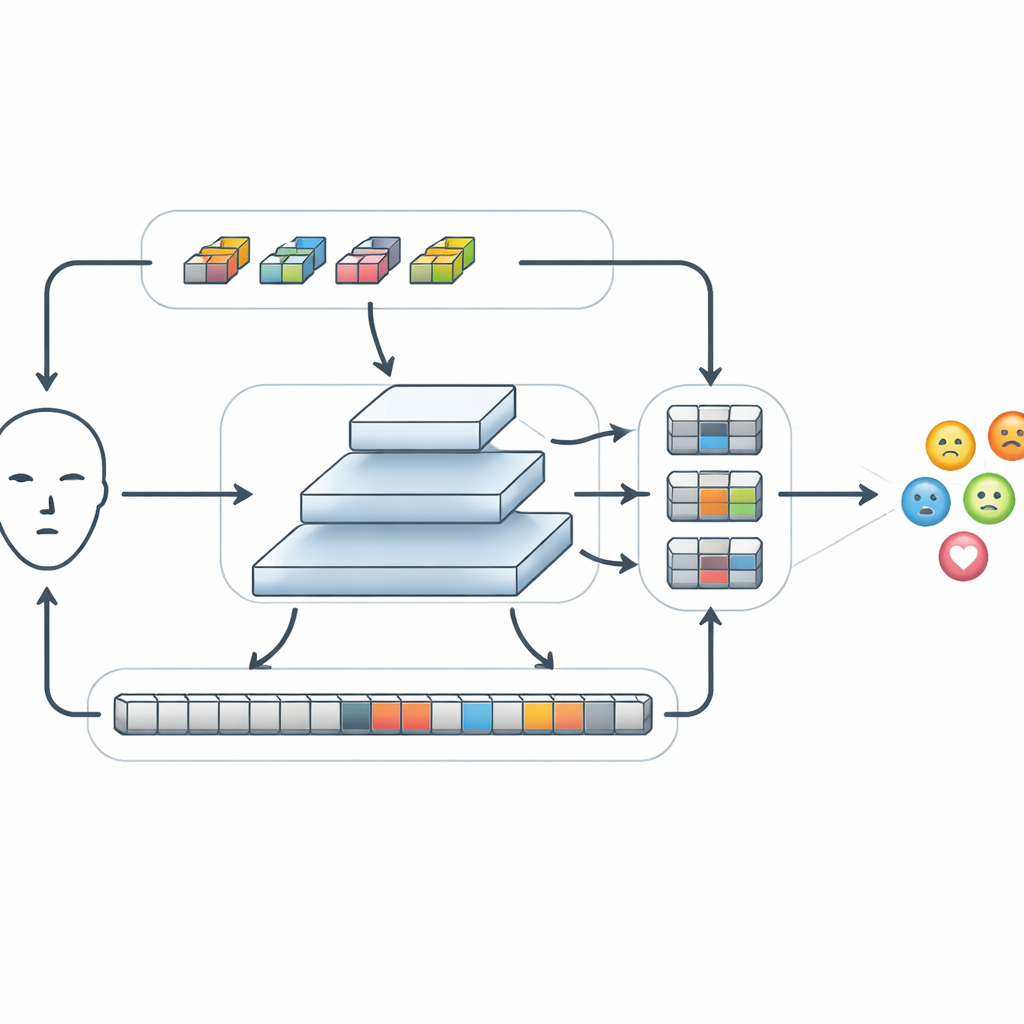
Equivalendo modelos poderosos com muito menos computação
Os autores testaram o FERMam em três grandes benchmarks de expressão facial: RAF-DB, AffectNet e FERPlus. Esses conjuntos contêm dezenas a centenas de milhares de rostos coletados em condições do mundo real, incluindo variações de iluminação, idades e poses. Nesses conjuntos, o FERMam alcançou níveis de acurácia próximos ou superiores a muitos métodos de ponta que dependem de arquiteturas pesadas baseadas em transformers. Em um dos conjuntos amplamente usados, seu desempenho quase iguala o melhor sistema publicado baseado em transformer, porém utiliza cerca de um terço a metade do número de parâmetros e muito menos operações. Na prática, isso significa que o FERMam pode rodar mais de duas vezes mais rápido, processar muito mais imagens por segundo em modo batch e ainda manter alta qualidade de reconhecimento. Estudos de ablação — experimentos controlados nos quais partes do projeto são removidas — mostram que cada componente, do ramo de marcos à fusão em pirâmide, desempenha um papel significativo nesse equilíbrio.
O que isso significa para tecnologias do dia a dia
Em termos simples, o estudo mostra que é possível construir um sistema de leitura emocional que seja ao mesmo tempo inteligente e econômico. Ao combinar duas vistas do rosto — sua aparência e sua forma — e ao organizar cuidadosamente como a informação flui pelo espaço e pela escala, o FERMam alcança reconhecimento robusto sem exigir um supercomputador. Isso o torna um candidato promissor para uso em telefones, robôs domésticos, câmeras de assistência ao motorista e outros dispositivos que precisam responder sensivelmente às emoções humanas em tempo real. Embora trabalhos futuros precisem enfrentar condições mais extremas, como forte oclusão ou imagens de muito baixa resolução, o FERMam aponta o caminho para uma computação prática, eficiente e mais consciente do humano.
Citação: Gao, C., Ji, X., Zhang, Q. et al. FERMam: a lightweight dual-source and multi-scale fusion framework for facial expression recognition. Sci Rep 16, 13826 (2026). https://doi.org/10.1038/s41598-026-44396-6
Palavras-chave: reconhecimento de expressão facial, IA sensível a emoções, aprendizado profundo leve, modelos de espaço de estado, interação humano–computador