Clear Sky Science · zh
一种带结构感知损失的 CNN‑Transformer 双分支网络用于高分辨率边缘检测
为何数字图像中清晰轮廓很重要
无论是在自动驾驶场景中检测汽车、在医学影像中勾画肿瘤,还是将照片转成整洁的素描,计算机都依赖于找到清晰的边缘——即物体之间的边界。然而即便是当今强大的深度学习系统,也常常将这些轮廓画成断裂、模糊或略微偏移的线条。本文提出了一种新的方法,教会神经网络在高分辨率图像中绘制更干净、更连续的边缘,使后续的视觉任务更可靠且在视觉上更具说服力。
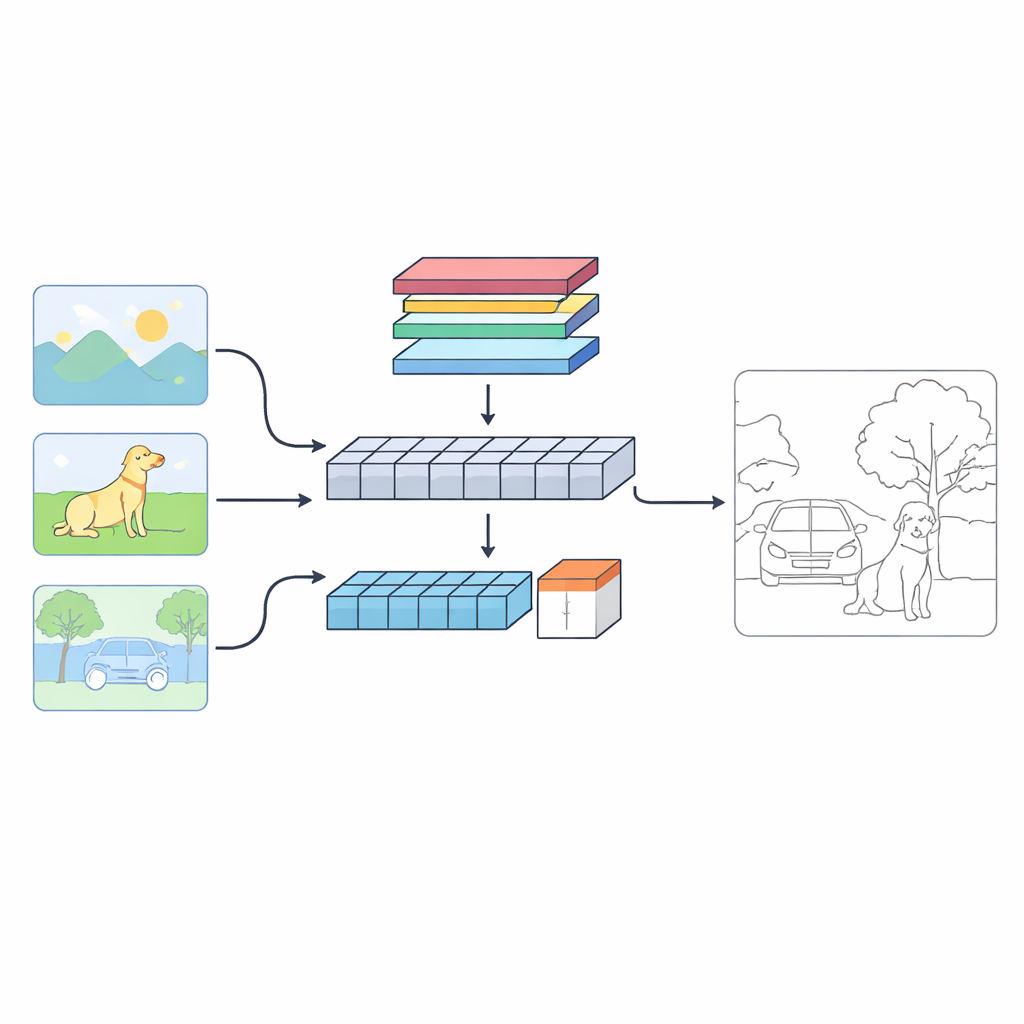
重新审视机器如何寻找边界
早期的计算机视觉工具,例如 1980 年代的经典边缘检测器,会查看像素的小邻域并突出亮度突变的位置。它们速度很快,但容易被纹理、阴影或噪声干扰。现代深度网络通过从大规模图像集学习并堆叠多层来识别不同尺度的边缘,从而改进了这一点。然而,大多数方法仍然将每个像素视为一个孤立的二元决策:“边缘”或“非边缘”。这种逐像素的视角忽略了现实世界边界是平滑、连续且具有一致方向的曲线这一事实,而不是随机的斑点。因此,网络可能在数值指标上表现良好,但仍生成看上去断裂或模糊的轮廓。
对每张图像使用两只“眼睛”的网络
作者提出了一个名为 C‑TDED 的双分支系统,从两种互补的视角观察每张图像。一个分支基于卷积神经网络,保持接近图像的原始分辨率,擅长捕捉细微细节,例如发丝、物体轮廓和微小角点。另一个分支采用 Transformer 风格的设计,善于捕捉长程关系和整体场景布局——例如理解树干和枝条即便在图像中相距较远也属于同一物体。一个专门的融合模块随后将这两种视角结合起来,利用注意力和保持边缘细节的操作在保留精细结构的同时兼顾全局语境。两个分支协同工作,像放大镜与广角镜共同观测。
教网络什么才是真正“好的”边缘
核心创新不仅在于架构,更在于网络的训练方式——即损失函数。作者设计了一种结构感知损失,而不是仅仅奖励网络匹配正确像素,这种损失编码了三种关于良好边缘的直观属性。首先,梯度项鼓励在边界处产生强且清晰的跃变,而不是模糊的斜坡。第二,连贯性项对边缘中的间隙和突断进行惩罚,推动模型画出连续不断的线条。第三,方向项要求相邻的边缘片段具有一致的朝向,抑制参差或之字形的模式。这些成分与处理类别不平衡和区域重叠的标准损失项相结合,形成了更能反映人类对干净轮廓感知的统一目标。
从易到难的渐进式学习
为了使训练稳定且高效,作者引入了一个三阶段的计划,随着时间推移调整不同损失分量的重要性。开始阶段,网络侧重于简单地得到正确的像素,使用传统的像素级项来找到边缘的粗略草图。中间阶段,重点转向形成完整的区域和连续的轮廓。最终阶段,结构性项(与锐利度和方向相关)接管,打磨轮廓使之变得清晰且几何一致。这种类似课程学习的方法帮助模型避免陷入劣解,并稳步提升数值性能和视觉质量。
更清晰的轮廓且计算负担更小
在若干标准基准上测试(包括自然照片和带深度信息的室内场景),该方法始终能匹配或超过领先对手。它在关键质量指标上取得了领先成绩,同时使用的参数比许多竞品更少,使其对必须快速运行或在受限硬件上部署的真实系统更具吸引力。对非专业人士而言,结论很简单:通过为网络明确什么使边缘看起来“正确”——强烈、连续并且方向平滑——这项工作使计算机视觉更接近人类直观感知的物体边界,进而实现更准确可靠的图像理解。
引用: Jiang, J., Guo, J. & Yang, Z. A CNN-transformer dual-branch network with structure-aware loss for high-resolution edge detection. Sci Rep 16, 14191 (2026). https://doi.org/10.1038/s41598-026-44362-2
关键词: 边缘检测, 计算机视觉, 深度学习, 图像分割, Transformer 网络