Clear Sky Science · ru
Двухветвная сеть CNN‑трансформер со структурно‑осознанной функцией потерь для детекции краев в высоком разрешении
Почему чёткие контуры важны в цифровых изображениях
Будь то обнаружение автомобиля в сцене для автономного вождения, выделение опухоли на медицинском снимке или преобразование фотографии в аккуратный рисунок, компьютеры опираются на обнаружение чётких границ — разделов между объектами. Тем не менее даже современные мощные модели глубокого обучения нередко дают разорванные, размытые или слегка смещённые контуры. В этой работе предложен новый способ обучения нейросетей, позволяющий получать более чистые, непрерывные края в изображениях высокого разрешения, что делает последующие задачи зрительного анализа более надёжными и визуально убедительными.
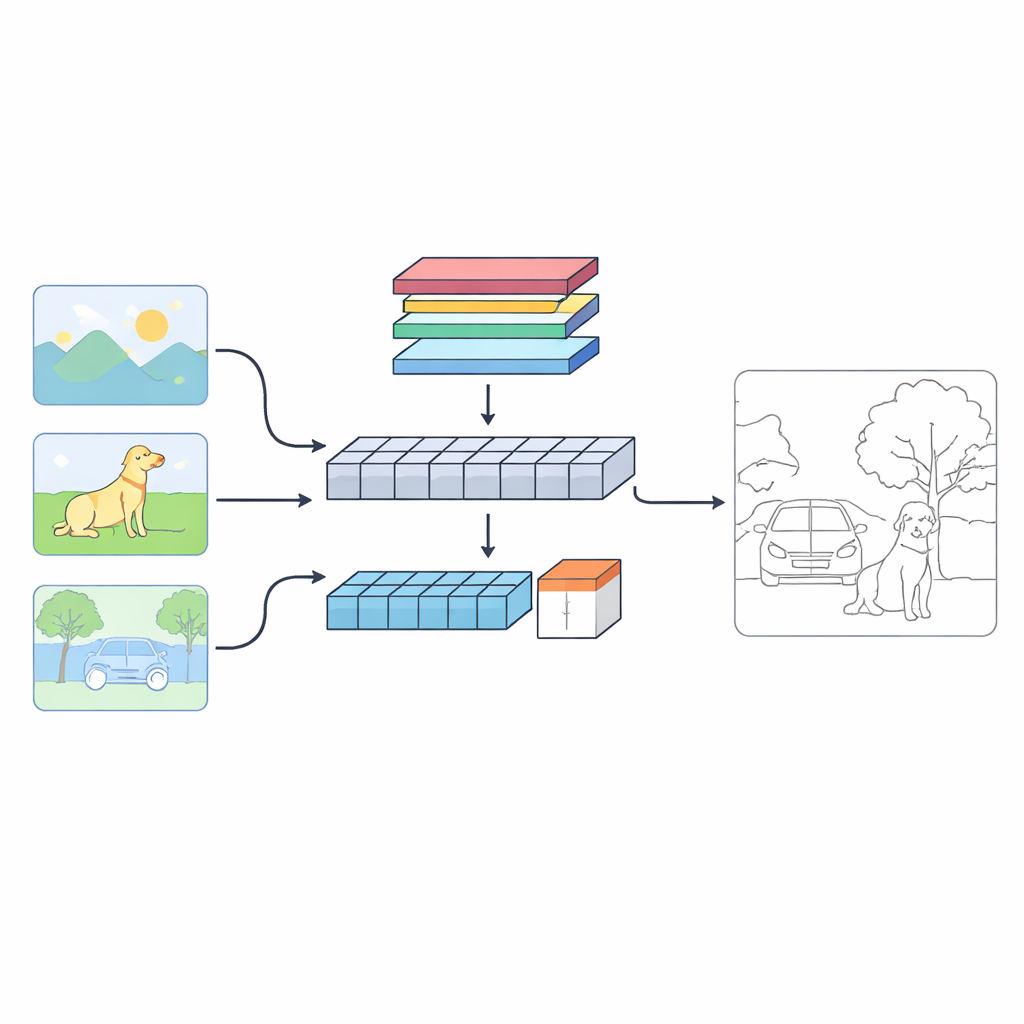
Новый взгляд на то, как машины находят границы
Ранние инструменты компьютерного зрения, такие как классические детекторы краёв из 1980‑х, анализировали небольшие окрестности пикселей и отмечали места резкой смены яркости. Они были быстрыми, но их легко вводили в заблуждение текстуры, тени или шум. Современные глубокие сети улучшили ситуацию, обучаясь на больших коллекциях изображений и складывая множество слоёв для распознавания краёв на разных масштабах. Однако большинство методов по‑прежнему рассматривают каждый пиксель как изолированное бинарное решение: «край» или «не край». Такой покомпонентный подход игнорирует факт, что реальные границы — это гладкие, связанные кривые с согласованным направлением, а не случайные точки. В результате сети могут показывать хорошие численные показатели, но при этом генерировать контуры, которые глазу кажутся разорванными или размытыми.
Сеть с двумя «глазами» на одно изображение
Авторы предлагают двухветвевую систему под названием C‑TDED, которая рассматривает каждое изображение двумя взаимодополняющими способами. Одна ветвь основана на сверточных нейронных сетях и работает близко к исходному разрешению — она специализирована на захвате тонких деталей, таких как волоски, контуры объектов и мелкие углы. Другая ветвь использует архитектуру в стиле трансформера, хорошо улавливающую дальние связи и общую структуру сцены — например, понимание того, что ствол дерева и его ветви принадлежат одному объекту, даже если они удалены друг от друга на изображении. Выделенный модуль слияния затем объединяет эти два представления, применяя механизмы внимания и операции сохранения краёв, чтобы удержать тонкие детали, одновременно учитывая глобальный контекст. Ветви работают вместе, как лупа и широкоугольный объектив, действующие в тандеме.
Обучение сети, что такое «хороший» край
Ключевая инновация заключается не только в архитектуре, но и в способе обучения — в функции потерь. Вместо того чтобы вознаграждать сеть лишь за совпадение отдельных пикселей, авторы проектируют структурно‑осознанную функцию потерь, кодирующую три интуитивные свойства хороших краёв. Во‑первый, градиентный член поощряет сильные, резкие переходы на границах вместо плавных размытых переходов. Во‑вторых, член непрерывности штрафует за разрывы и внезапные прерывания вдоль края, подталкивая модель рисовать цельные линии. В‑третьих, член направления заставляет соседние сегменты края иметь согласованные ориентации, предотвращая зубчатые или зигзагообразные паттерны. Эти составляющие объединены со стандартными членами потерь, учитывающими несбалансированность классов и перекрытие регионов, формируя единый критерий, который лучше отражает то, что человек воспринимает как чистый контур.
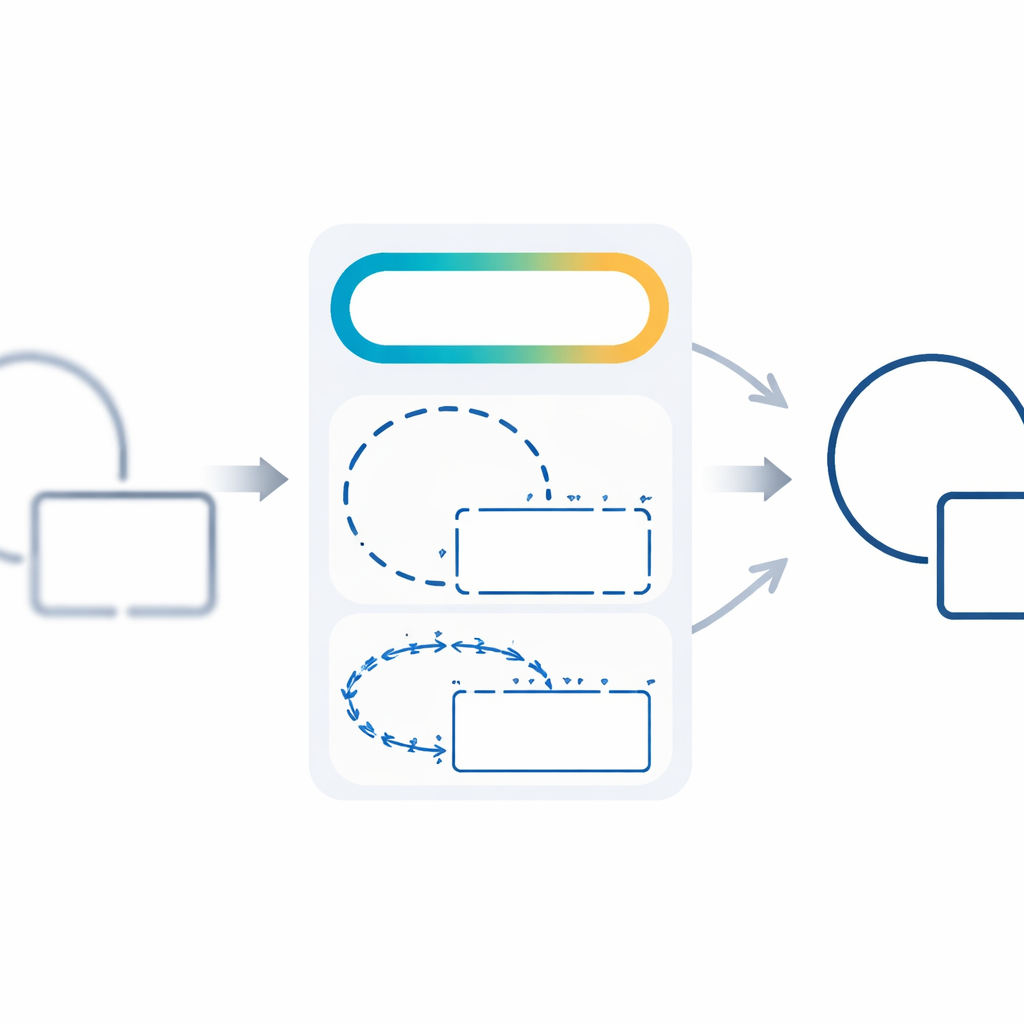
Постепенное обучение от простого к сложному
Чтобы сделать обучение стабильным и эффективным, авторы вводят триэтапное расписание, которое изменяет значимость различных компонентов функции потерь со временем. На начальном этапе сеть сосредоточена на простом угадывании правильных пикселей, используя традиционные пиксельные термы, чтобы найти грубый набросок краёв. На среднем этапе акцент смещается в сторону формирования целостных областей и непрерывных контуров. На финальном этапе структурные термы, связанные с резкостью и направлением, берут верх, доводя контуры до чёткого, геометрически согласованного состояния. Такой учебный план помогает модели избегать застревания в плохих решениях и постепенно улучшать как численные показатели, так и визуальное качество.
Более чёткие контуры с меньшими вычислительными затратами
При тестировании на нескольких стандартных бенчмарках, включая природные фотографии и сцены в помещении с информацией о глубине, новый метод последовательно сопоставим или превосходит ведущие аналоги. Он достигает высоких результатов по ключевым метрикам качества, при этом использует меньше параметров, чем многие конкурирующие сети, что делает его привлекательным для реальных систем, которым требуется быстрая работа или ограниченные ресурсы. Для неспециалистов вывод прост: задав сети понятное представление о том, что делает край «правильным» — сильным, непрерывным и плавно ориентированным — эта работа приближает компьютерное зрение к тому, как люди интуитивно видят границы объектов, обеспечивая более точное и надёжное понимание изображений.
Цитирование: Jiang, J., Guo, J. & Yang, Z. A CNN-transformer dual-branch network with structure-aware loss for high-resolution edge detection. Sci Rep 16, 14191 (2026). https://doi.org/10.1038/s41598-026-44362-2
Ключевые слова: детекция краёв, компьютерное зрение, глубокое обучение, сегментация изображений, сети‑трансформеры