Clear Sky Science · fr
Un réseau à double branche CNN-transformer avec une perte consciente de la structure pour la détection de contours en haute résolution
Pourquoi des contours nets sont importants dans les images numériques
Qu’il s’agisse de détecter une voiture dans une scène pour la conduite autonome, de délimiter une tumeur dans un examen médical ou de transformer une photo en un croquis soigné, les ordinateurs s’appuient sur la détection de contours clairs — les frontières entre les objets. Pourtant, même les systèmes d’apprentissage profond performants d’aujourd’hui dessinent souvent ces contours sous forme de lignes brisées, floues ou légèrement décalées. Cet article introduit une nouvelle façon d’apprendre aux réseaux neuronaux à produire des contours plus propres et plus continus dans des images haute résolution, rendant les tâches de vision en aval à la fois plus fiables et plus convaincantes visuellement.
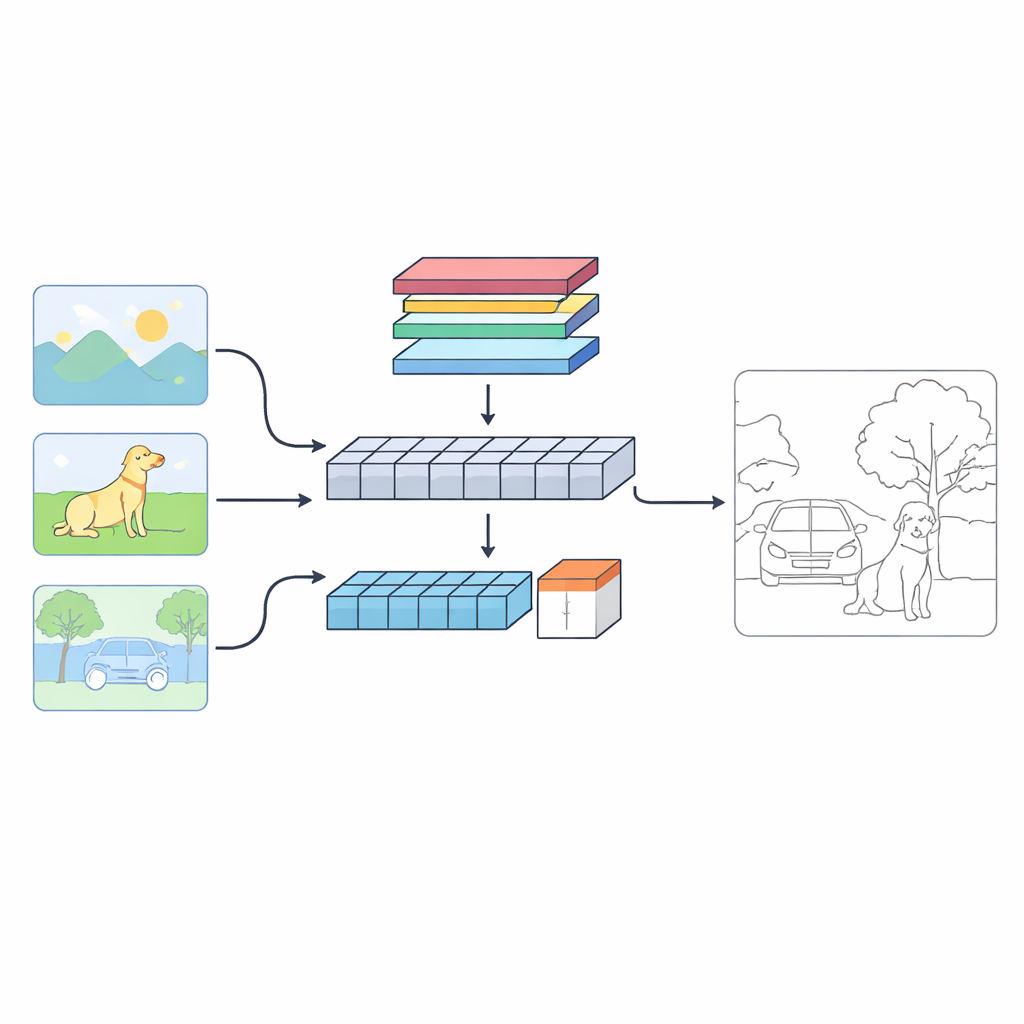
Une nouvelle perspective sur la façon dont les machines trouvent les frontières
Les premiers outils de vision par ordinateur, comme les détecteurs de contours classiques des années 1980, examinaient de petits voisinages de pixels et mettaient en évidence où la luminosité changeait brusquement. Ils étaient rapides mais facilement trompés par la texture, les ombres ou le bruit. Les réseaux profonds modernes ont amélioré la situation en apprenant à partir de larges collections d’images, empilant de nombreuses couches pour reconnaître les contours à différentes échelles. Cependant, la plupart de ces méthodes traitent encore chaque pixel comme une décision isolée : « contour » ou « pas contour ». Cette vision pixel par pixel ignore le fait que les frontières réelles sont des courbes lisses et connectées avec une direction cohérente, et non des taches aléatoires. Par conséquent, les réseaux peuvent obtenir de bons scores numériques tout en produisant des contours qui paraissent brisés ou flous à l’œil humain.
Un réseau avec deux « yeux » sur chaque image
Les auteurs proposent un système à double branche appelé C‑TDED qui analyse chaque image de deux manières complémentaires. Une branche repose sur des réseaux de neurones convolutionnels et conserve une résolution proche de l’originale. Elle est spécialisée dans la capture des détails fins comme les mèches de cheveux, les contours d’objets et les petits coins. L’autre branche utilise une architecture de type transformer, efficace pour saisir les relations à longue portée et la disposition générale de la scène — comprenant, par exemple, qu’un tronc d’arbre et ses branches appartiennent au même objet même s’ils sont éloignés dans l’image. Un module de fusion dédié combine ensuite ces deux vues, en utilisant l’attention et des opérations de préservation des bords pour conserver les détails délicats tout en respectant le contexte global. Ensemble, les branches fonctionnent comme une loupe et un objectif grand angle agissant de concert.
Apprendre au réseau ce qu’est vraiment un « bon » contour
L’innovation centrale ne réside pas seulement dans l’architecture mais aussi dans la manière dont le réseau est entraîné — sa fonction de perte. Plutôt que de récompenser uniquement le réseau pour le fait de correspondre aux pixels corrects, les auteurs conçoivent une perte consciente de la structure qui encode trois propriétés intuitives des bons contours. D’abord, un terme de gradient encourage des transitions fortes et nettes aux frontières plutôt que des rampes floues. Ensuite, un terme de continuité pénalise les lacunes et les ruptures brusques le long d’un contour, poussant le modèle à dessiner des lignes ininterrompues. Enfin, un terme de direction incite les segments de contour voisins à pointer dans des directions cohérentes, décourageant les motifs en dents de scie ou zigzagants. Ces ingrédients sont combinés avec des termes de perte classiques qui gèrent le déséquilibre des classes et le recouvrement des régions, formant un objectif unifié qui reflète mieux ce que les humains perçoivent comme un contour propre.
Apprendre progressivement du facile au difficile
Pour rendre l’entraînement stable et efficace, les auteurs introduisent un calendrier en trois étapes qui modifie l’importance des différents composants de la perte au fil du temps. Au début, le réseau se concentre sur l’obtention des bons pixels, en utilisant des termes traditionnels au niveau du pixel pour trouver une esquisse grossière des contours. À l’étape intermédiaire, l’accent bascule vers la formation de régions complètes et de contours continus. Dans la phase finale, les termes structurels liés à la netteté et à la direction prennent le relais, polissant les contours pour obtenir des formes nettes et cohérentes sur le plan géométrique. Cette approche de type curriculum aide le modèle à éviter de rester bloqué dans de mauvaises solutions et améliore progressivement à la fois les performances numériques et la qualité visuelle.
Des contours plus nets avec moins de charges computationnelles
Testée sur plusieurs benchmarks standard, y compris des photographies naturelles et des scènes intérieures avec information de profondeur, la nouvelle méthode égalise ou dépasse constamment les meilleurs concurrents. Elle atteint des scores de pointe sur des mesures de qualité clés tout en utilisant moins de paramètres que de nombreux réseaux rivaux, ce qui la rend attrayante pour des systèmes réels qui doivent fonctionner rapidement ou sur du matériel limité. Pour les non-experts, la conclusion est simple : en donnant au réseau une notion claire de ce qui rend un contour « correct » — fort, ininterrompu et orienté de façon lisse — ce travail rapproche la vision par ordinateur de la manière dont les humains perçoivent intuitivement les frontières d’objet, permettant une compréhension d’image plus précise et plus fiable.
Citation: Jiang, J., Guo, J. & Yang, Z. A CNN-transformer dual-branch network with structure-aware loss for high-resolution edge detection. Sci Rep 16, 14191 (2026). https://doi.org/10.1038/s41598-026-44362-2
Mots-clés: détection de contours, vision par ordinateur, apprentissage profond, segmentation d'image, réseaux transformer