Clear Sky Science · es
Una red de doble rama CNN-transformer con pérdida consciente de la estructura para la detección de contornos en alta resolución
Por qué importan los contornos nítidos en las imágenes digitales
Ya se trate de detectar un coche en una escena de conducción autónoma, delinear un tumor en una exploración médica o convertir una foto en un boceto limpio, los sistemas informáticos dependen de encontrar bordes claros —las fronteras entre objetos—. Sin embargo, incluso los potentes sistemas de aprendizaje profundo actuales a menudo trazan estos contornos como líneas rotas, borrosas o ligeramente desplazadas. Este artículo presenta una nueva manera de enseñar a las redes neuronales a dibujar bordes más limpios y continuos en imágenes de alta resolución, haciendo que las tareas de visión posteriores sean más fiables y visualmente convincentes.
Una mirada renovada a cómo las máquinas encuentran fronteras
Las herramientas tempranas de visión por computador, como los detectores clásicos de bordes de los años 80, examinaban vecindarios pequeños de píxeles y resaltaban donde el brillo cambiaba bruscamente. Eran rápidas, pero se confundían con facilidad por texturas, sombras o ruido. Las redes profundas modernas mejoraron la situación al aprender de grandes colecciones de imágenes y apilar muchas capas para reconocer bordes a distintas escalas. Sin embargo, la mayoría de estos métodos siguen tratando cada píxel como una decisión aislada de sí o no: “borde” o “no borde”. Esta visión píxel a píxel ignora que las fronteras del mundo real son curvas suaves y conectadas con una dirección consistente, no manchas aleatorias. Como resultado, las redes pueden obtener buenas puntuaciones numéricas mientras producen contornos que, a la vista, parecen rotos o borrosos.
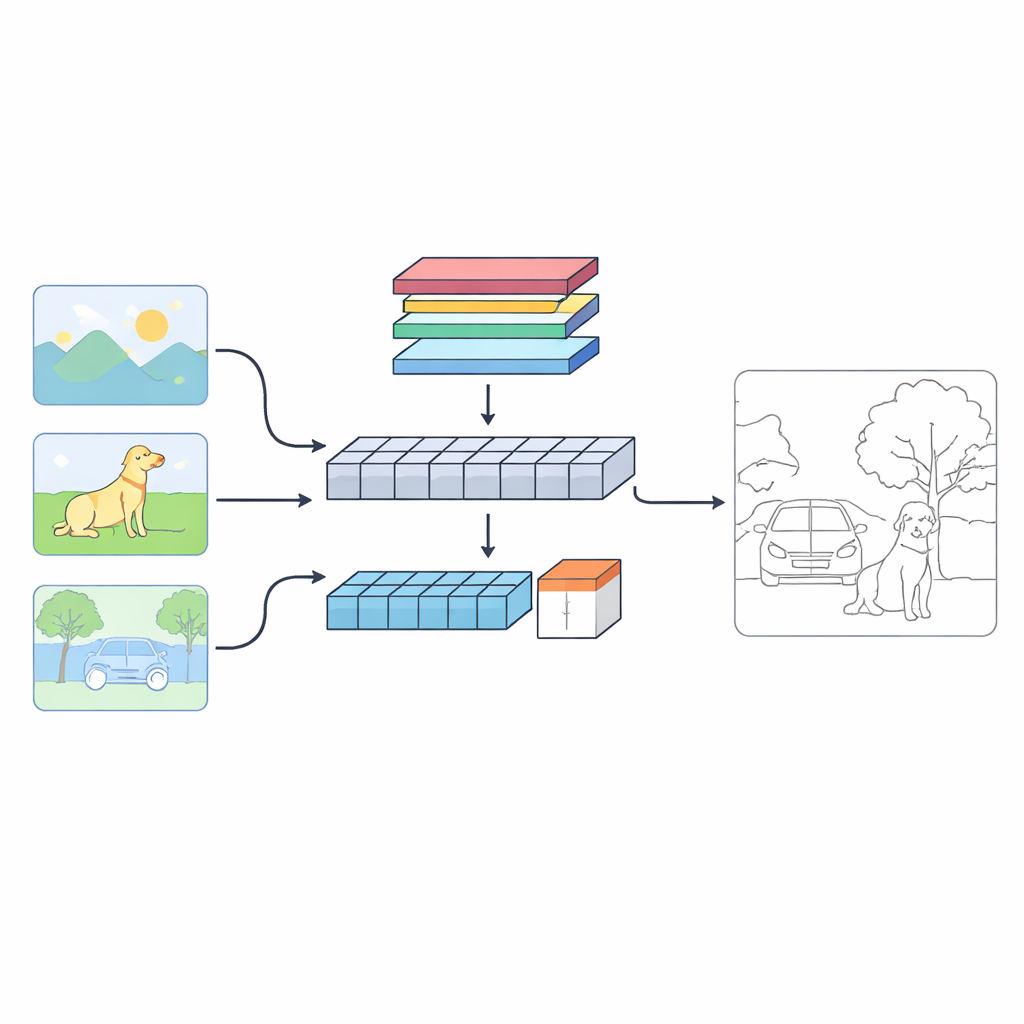
Una red con dos “ojos” sobre cada imagen
Los autores proponen un sistema de doble rama llamado C‑TDED que observa cada imagen de dos maneras complementarias. Una rama se basa en redes neuronales convolucionales y mantiene una resolución cercana a la original. Está especializada en capturar detalles finos como mechones de pelo, contornos de objetos y esquinas diminutas. La otra rama utiliza un diseño tipo transformer, que es efectivo captando relaciones a larga distancia y la disposición global de la escena —comprendiendo, por ejemplo, que el tronco de un árbol y sus ramas pertenecen al mismo objeto aunque estén separados en la imagen. Un módulo de fusión dedicado combina estas dos visiones, usando atención y operaciones que preservan los bordes para conservar los detalles delicados sin perder el contexto global. Juntas, las ramas actúan como una lupa y un objetivo gran angular trabajando en concierto.
Enseñar a la red qué es realmente un “buen” borde
La innovación central no es solo la arquitectura, sino la forma en que se entrena la red: su función de pérdida. En lugar de recompensar únicamente que la red coincida con los píxeles correctos, los autores diseñan una pérdida consciente de la estructura que codifica tres propiedades intuitivas de los buenos bordes. Primero, un término de gradiente fomenta transiciones fuertes y nítidas en las fronteras en lugar de rampas difusas. Segundo, un término de continuidad penaliza las brechas y rupturas abruptas a lo largo de un borde, empujando al modelo a dibujar líneas ininterrumpidas. Tercero, un término de dirección pide que los segmentos de borde vecinos apunten en direcciones consistentes, desalentando patrones dentados o en zigzag. Estos ingredientes se combinan con términos de pérdida estándar que manejan el desequilibrio de clases y la superposición de regiones, formando un objetivo unificado que refleja mejor lo que los humanos perciben como un contorno limpio.
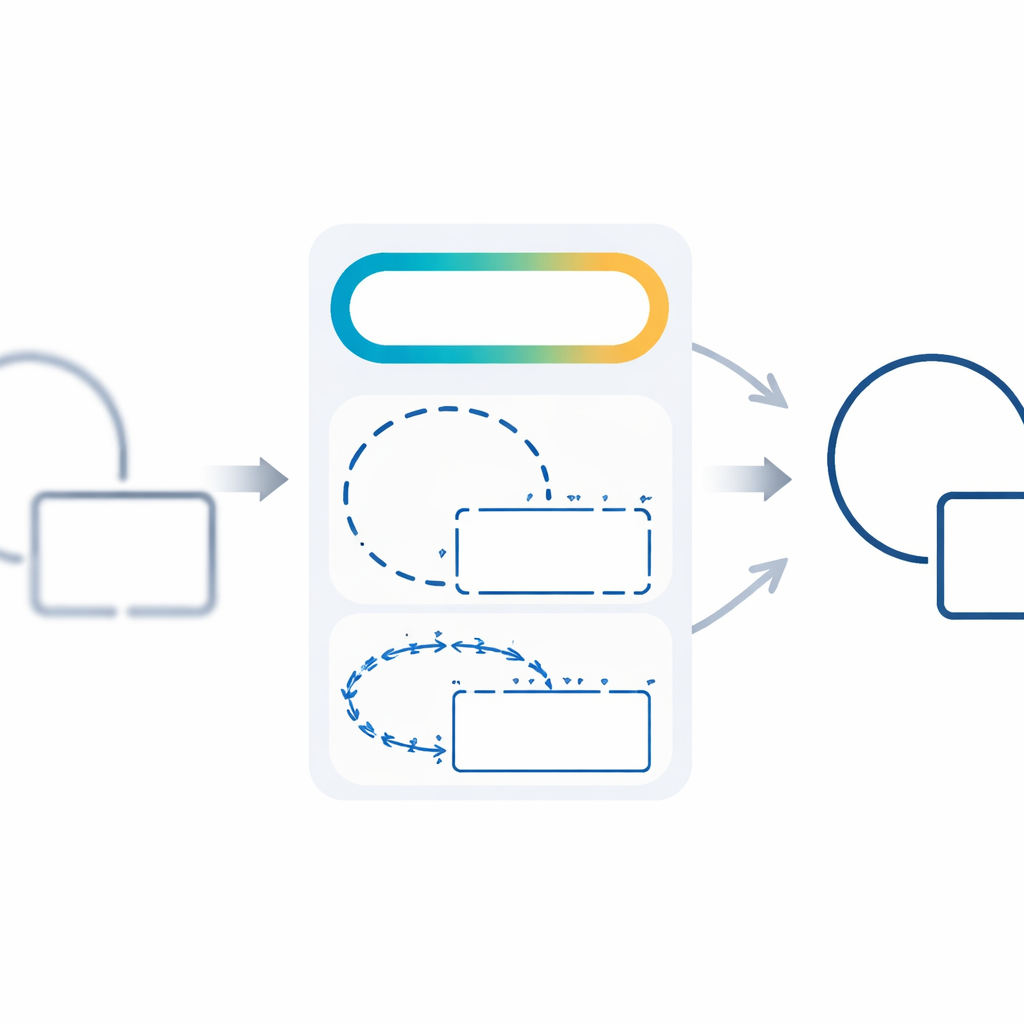
Aprender de forma gradual: de lo fácil a lo difícil
Para que el entrenamiento sea estable y eficiente, los autores introducen un calendario en tres fases que cambia la importancia de los diferentes componentes de la pérdida a lo largo del tiempo. Al principio, la red se concentra en acertar los píxeles adecuados, usando términos tradicionales a nivel de píxel para obtener un boceto aproximado de los bordes. En la fase intermedia, el énfasis se desplaza hacia la formación de regiones completas y contornos continuos. En la etapa final, los términos estructurales relacionados con la nitidez y la dirección toman el relevo, puliendo los contornos hasta obtener formas nítidas y coherentes geométricamente. Este enfoque tipo currículo ayuda al modelo a evitar quedarse atrapado en soluciones pobres y mejora de forma sostenida tanto el rendimiento numérico como la calidad visual.
Contornos más nítidos con menos carga computacional
Probado en varios benchmarks estándar, incluidas fotografías naturales y escenas interiores con información de profundidad, el nuevo método iguala o supera de forma consistente a los competidores líderes. Logra las mejores puntuaciones en medidas clave de calidad mientras emplea menos parámetros que muchas redes rivales, lo que lo hace atractivo para sistemas reales que deben funcionar rápido o en hardware limitado. Para quienes no son expertos, la conclusión es simple: al darle a la red una noción clara de qué hace que un borde parezca “correcto” —fuerte, continuo y orientado de forma suave—, este trabajo acerca la visión por computador a la forma en que los humanos perciben intuitivamente las fronteras de los objetos, posibilitando una comprensión de la imagen más precisa y fiable.
Cita: Jiang, J., Guo, J. & Yang, Z. A CNN-transformer dual-branch network with structure-aware loss for high-resolution edge detection. Sci Rep 16, 14191 (2026). https://doi.org/10.1038/s41598-026-44362-2
Palabras clave: detección de bordes, visión por computador, aprendizaje profundo, segmentación de imágenes, redes transformer