Clear Sky Science · pt
Uma rede dupla CNN-transformer com perda sensível à estrutura para detecção de bordas em alta resolução
Por que contornos nítidos importam em imagens digitais
Seja para detectar um carro em uma cena de direção autônoma, delinear um tumor em um exame médico ou transformar uma foto em um esboço limpo, os computadores dependem de encontrar bordas claras — os limites entre objetos. Ainda assim, mesmo os sistemas de aprendizado profundo mais potentes frequentemente traçam esses contornos como linhas quebradas, borradas ou levemente deslocadas. Este artigo apresenta uma nova maneira de ensinar redes neurais a produzir bordas mais limpas e contínuas em imagens de alta resolução, tornando tarefas de visão a jusante mais confiáveis e visualmente convincentes.
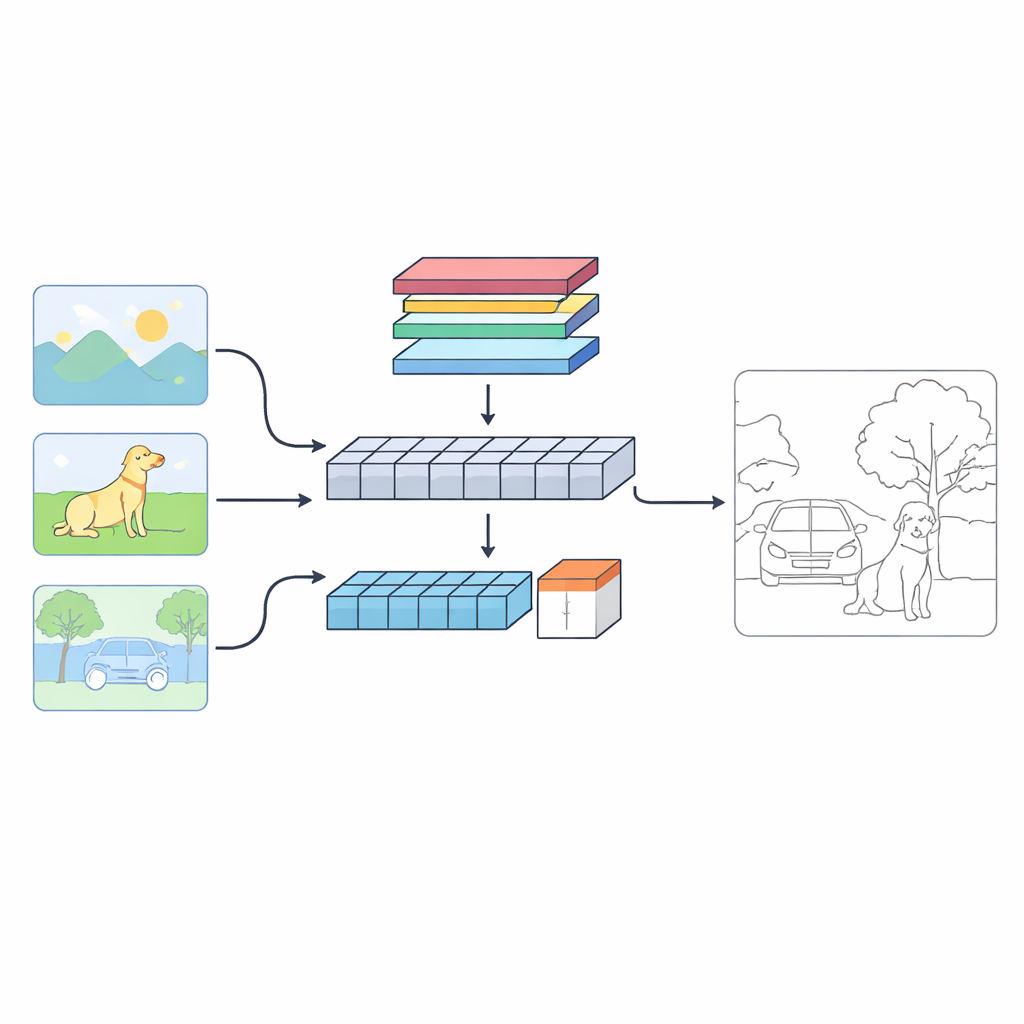
Uma nova visão sobre como as máquinas encontram limites
As primeiras ferramentas de visão computacional, como detectores de borda clássicos da década de 1980, analisavam pequenas vizinhanças de pixels e destacavam onde o brilho mudava abruptamente. Eram rápidas, mas facilmente confundidas por texturas, sombras ou ruído. Redes profundas modernas melhoraram a situação ao aprender com grandes coleções de imagens, empilhando muitas camadas para reconhecer bordas em diferentes escalas. No entanto, a maioria desses métodos ainda trata cada pixel como uma decisão isolada de sim ou não: “borda” ou “não borda”. Essa visão pixel a pixel ignora o fato de que limites do mundo real são curvas suaves e conectadas com direção consistente, não manchas aleatórias. Como resultado, as redes podem obter boas pontuações numéricas e ainda assim produzir contornos que parecem quebrados ou desfocados ao olho humano.
Uma rede com dois “olhos” para cada imagem
Os autores propõem um sistema de dois ramos chamado C‑TDED que analisa cada imagem de duas maneiras complementares. Um ramo baseia-se em redes neurais convolucionais e mantém-se próximo à resolução original da imagem. Ele é especializado em capturar detalhes finos, como fios de cabelo, contornos de objetos e cantos minúsculos. O outro ramo usa um design no estilo transformer, que é bom em capturar relações de longo alcance e a disposição geral da cena — entendendo, por exemplo, que o tronco de uma árvore e seus galhos pertencem ao mesmo objeto mesmo que estejam distantes na imagem. Um módulo de fusão dedicado então combina essas duas visões, usando atenção e operações que preservam bordas para manter detalhes delicados enquanto respeita o contexto global. Juntos, os ramos funcionam como uma lupa e uma lente grande-angular trabalhando em conjunto.
Ensinando a rede o que é uma “boa” borda
A inovação central não é apenas a arquitetura, mas a forma como a rede é treinada — sua função de perda. Em vez de apenas recompensar a rede por corresponder aos pixels corretos, os autores projetam uma perda sensível à estrutura que codifica três propriedades intuitivas de boas bordas. Primeiro, um termo de gradiente incentiva transições fortes e nítidas nas fronteiras em vez de rampas borradas. Segundo, um termo de continuidade penaliza lacunas e quebras abruptas ao longo de uma borda, pressionando o modelo a desenhar linhas ininterruptas. Terceiro, um termo de direção pede que segmentos de borda vizinhos apontem em direções consistentes, desencorajando padrões serrilhados ou em ziguezague. Esses ingredientes são combinados com termos de perda padrão que lidam com desequilíbrio de classes e sobreposição de regiões, formando um objetivo unificado que reflete melhor o que os humanos percebem como um contorno limpo.
Aprendizado gradual do fácil ao difícil
Para tornar o treinamento estável e eficiente, os autores introduzem uma agenda em três estágios que altera a importância de diferentes componentes da perda ao longo do tempo. No início, a rede se concentra em simplesmente acertar os pixels corretos, usando termos tradicionais ao nível do pixel para encontrar um esboço inicial das bordas. No estágio intermediário, a ênfase desloca-se para formar regiões completas e contornos contínuos. No estágio final, termos estruturais relacionados à nitidez e à direção assumem o protagonismo, polindo os contornos em formas nítidas e geometricamente coerentes. Essa abordagem semelhante a um currículo ajuda o modelo a evitar ficar preso em soluções ruins e melhora de forma constante tanto o desempenho numérico quanto a qualidade visual.
Contornos mais nítidos com menos sobrecarga computacional
Testado em vários benchmarks padrão, incluindo fotografias naturais e cenas internas com informação de profundidade, o novo método consistentemente iguala ou supera concorrentes de ponta. Ele alcança as melhores pontuações em medidas-chave de qualidade enquanto usa menos parâmetros do que muitas redes rivais, tornando-o atraente para sistemas do mundo real que precisam rodar rapidamente ou em hardware limitado. Para não especialistas, a conclusão é simples: ao dar à rede uma noção clara do que faz uma borda parecer “certa” — forte, ininterrupta e suavemente orientada — este trabalho aproxima a visão computacional de como os humanos intuem limites de objetos, possibilitando um entendimento de imagens mais preciso e confiável.
Citação: Jiang, J., Guo, J. & Yang, Z. A CNN-transformer dual-branch network with structure-aware loss for high-resolution edge detection. Sci Rep 16, 14191 (2026). https://doi.org/10.1038/s41598-026-44362-2
Palavras-chave: detecção de bordas, visão computacional, aprendizado profundo, segmentação de imagem, redes transformer