Clear Sky Science · pl
Sieć dwubranchowa CNN-transformer z funkcją strat świadomą struktury do wykrywania krawędzi w wysokiej rozdzielczości
Dlaczego ostr e kontury mają znaczenie w obrazach cyfrowych
Niezależnie od tego, czy w scenie dla samochodu autonomicznego wykrywana jest sylwetka pojazdu, czy w skanie medycznym obrysowywany jest guz, a może fotografia przekształcana jest w schludny szkic — komputery polegają na odnajdywaniu wyraźnych krawędzi, czyli granic między obiektami. Nawet współczesne potężne systemy uczenia głębokiego często jednak rysują te kontury jako przerwane, rozmyte lub nieco przesunięte linie. W artykule przedstawiono nowy sposób nauczania sieci neuronowych, aby generowały czyściejsze, bardziej ciągłe krawędzie w obrazach o wysokiej rozdzielczości, co sprawia, że zadania wizji komputerowej działają bardziej niezawodnie i wyglądają przekonująco wizualnie.
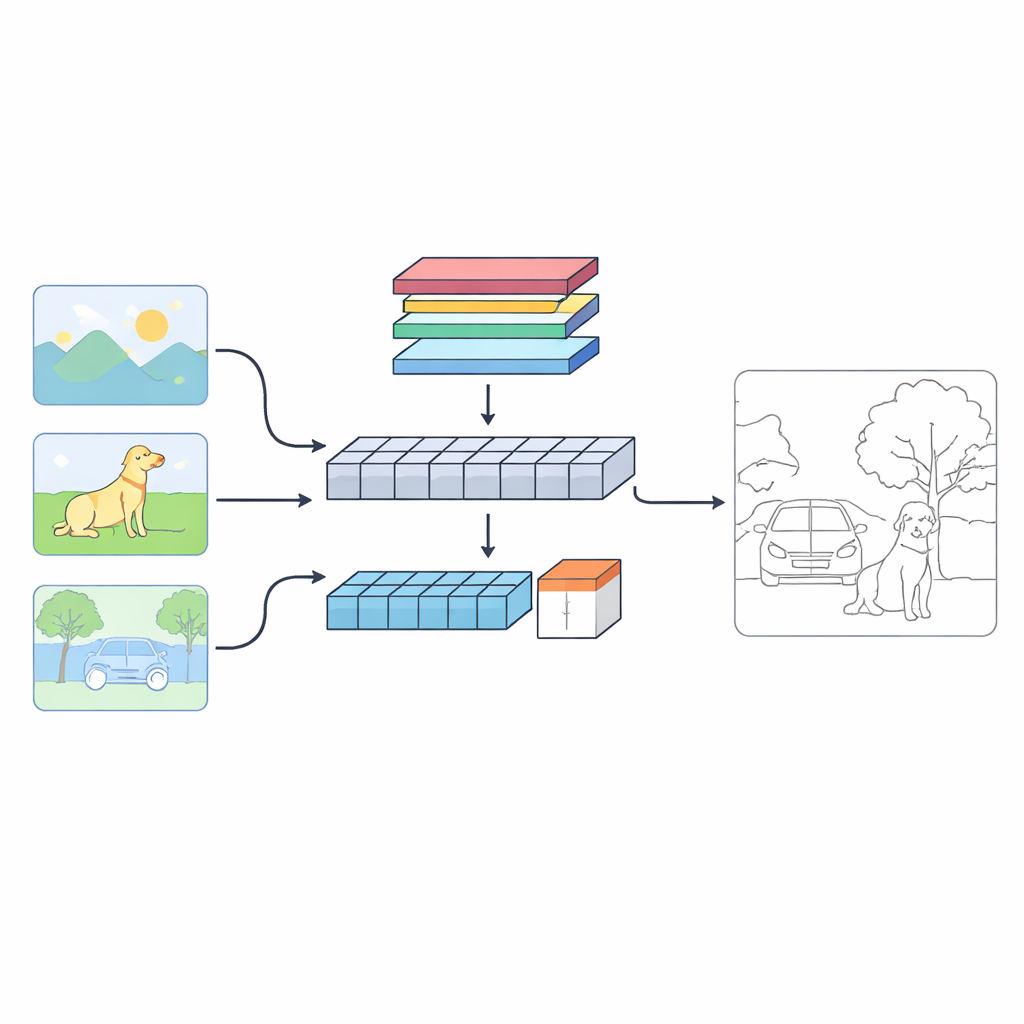
Nowe spojrzenie na to, jak maszyny znajdują granice
Wczesne narzędzia widzenia komputerowego, takie jak klasyczne detektory krawędzi z lat 80., analizowały niewielkie otoczenia pikseli i wyodrębniały miejsca, gdzie jasność zmieniała się gwałtownie. Były szybkie, lecz łatwo mylone przez tekstury, cienie czy szum. Nowoczesne sieci głębokie poprawiły sytuację, ucząc się na dużych zbiorach obrazów i łącząc wiele warstw, aby rozpoznawać krawędzie na różnych skalach. Jednak większość tych metod nadal traktuje każdy piksel jako izolowaną decyzję tak/nie: „krawędź” albo „nie krawędź”. Takie pikselowe podejście pomija fakt, że rzeczywiste granice to gładkie, połączone krzywe o spójnym kierunku, a nie losowe kropki. W efekcie sieci mogą osiągać dobre wyniki liczbowe, a jednocześnie generować obrysy, które wyglądają na przerwane lub rozmyte dla oka.
Sieć z dwoma „oczami” na obraz
Autorzy proponują system dwugalążowy o nazwie C‑TDED, który ogląda każdy obraz na dwa komplementarne sposoby. Jeden nurt opiera się na konwolucyjnych sieciach neuronowych i pozostaje blisko oryginalnej rozdzielczości obrazu. Specjalizuje się w wychwytywaniu drobnych detali, takich jak pojedyncze włoski, kontury obiektów czy małe narożniki. Drugi nurt wykorzystuje architekturę w stylu transformera, która dobrze oddaje długozasięgowe relacje i ogólny układ sceny — rozumie, na przykład, że pień drzewa i jego gałęzie należą do tego samego obiektu, nawet jeśli są od siebie daleko na obrazie. Dedykowany moduł fuzji łączy następnie te dwa spojrzenia, używając mechanizmów uwagi i operacji zachowujących krawędzie, aby utrzymać delikatne szczegóły przy jednoczesnym poszanowaniu globalnego kontekstu. Razem gałęzie działają jak lupa i obiektyw szerokokątny pracujące wspólnie.
Nauczanie sieci, czym jest „dobra” krawędź
Główną innowacją nie jest tylko architektura, lecz sposób trenowania sieci — funkcja strat. Zamiast nagradzania jedynie zgodności pikselowej, autorzy projektują stratę świadomą struktury, która koduje trzy intuicyjne właściwości dobrych krawędzi. Po pierwsze, składnik gradientowy zachęca do silnych, ostrych przejść na granicach zamiast rozmytych stopni. Po drugie, składnik ciągłości karze przerwy i nagłe załamania wzdłuż krawędzi, popychając model do rysowania nieprzerwanych linii. Po trzecie, składnik kierunku wymaga, aby sąsiednie segmenty krawędzi wskazywały spójne kierunki, zniechęcając do ząbkowanych lub zygzakowatych wzorców. Te elementy są łączone ze standardowymi terminami straty, które radzą sobie z niezrównoważeniem klas i nakładaniem się regionów, tworząc zunifikowany cel lepiej odzwierciedlający to, co ludzie postrzegają jako czysty obrys.
Nauka stopniowa od łatwych do trudnych przykładów
Aby trening był stabilny i wydajny, autorzy wprowadzają trzyetapowy harmonogram, który zmienia znaczenie poszczególnych składników straty w czasie. Na początku sieć koncentruje się na po prostu trafianiu w odpowiednie piksele, używając tradycyjnych terminów na poziomie pikseli, aby znaleźć wstępny szkic krawędzi. W środkowym etapie akcent przesuwa się w stronę tworzenia pełnych regionów i ciągłych konturów. W końcowym etapie dominują terminy strukturalne związane z ostrością i kierunkiem, które dopracowują obrysy do postaci ostrych, geometrycznie spójnych kształtów. Takie podejście przypominające program nauczania pomaga modelowi unikać utknięcia w słabych rozwiązaniach i stopniowo poprawia zarówno wyniki liczbowe, jak i jakość wizualną.
Bardziej ostre kontury przy mniejszym obciążeniu obliczeniowym
Testowana na kilku standardowych zestawach, w tym fotografiach naturalnych i scenach wewnętrznych z informacją o głębi, nowa metoda konsekwentnie dorównuje lub przewyższa czołowych konkurentów. Osiąga najwyższe wyniki w kluczowych miarach jakości, jednocześnie wykorzystując mniej parametrów niż wiele rywalizujących sieci, co czyni ją atrakcyjną dla systemów rzeczywistych, które muszą działać szybko lub na ograniczonym sprzęcie. Dla osób niebędących ekspertami wniosek jest prosty: nadając sieci jasne kryterium tego, co sprawia, że krawędź wygląda „poprawnie” — silna, nieprzerwana i gładko zorientowana — praca ta przybliża widzenie komputerowe do sposobu, w jaki ludzie intuicyjnie widzą granice obiektów, umożliwiając dokładniejsze i bardziej niezawodne rozumienie obrazu.
Cytowanie: Jiang, J., Guo, J. & Yang, Z. A CNN-transformer dual-branch network with structure-aware loss for high-resolution edge detection. Sci Rep 16, 14191 (2026). https://doi.org/10.1038/s41598-026-44362-2
Słowa kluczowe: wykrywanie krawędzi, widzenie komputerowe, uczenie głębokie, segmentacja obrazu, sieć transformer