Clear Sky Science · nl
Een CNN-transformer tweekamer netwerk met structuur-bewuste verliesfunctie voor randdetectie in hoge resolutie
Waarom scherpe omtrekken belangrijk zijn in digitale beelden
Of het nu gaat om het detecteren van een auto in een zelfrijdende scène, het omlijnen van een tumor in een medische scan, of het omzetten van een foto in een nette schets: computers vertrouwen op het vinden van duidelijke randen — de grenzen tussen objecten. Toch tekenen ook de krachtige diep-lerende systemen van vandaag deze omtrekken vaak als gebroken, vaag of lichtelijk verschoven lijnen. Dit artikel introduceert een nieuwe manier om neurale netwerken te leren nettere, meer continue randen te tekenen in afbeeldingen met hoge resolutie, waardoor vervolg taken in visie betrouwbaarder en visueel overtuigender worden.
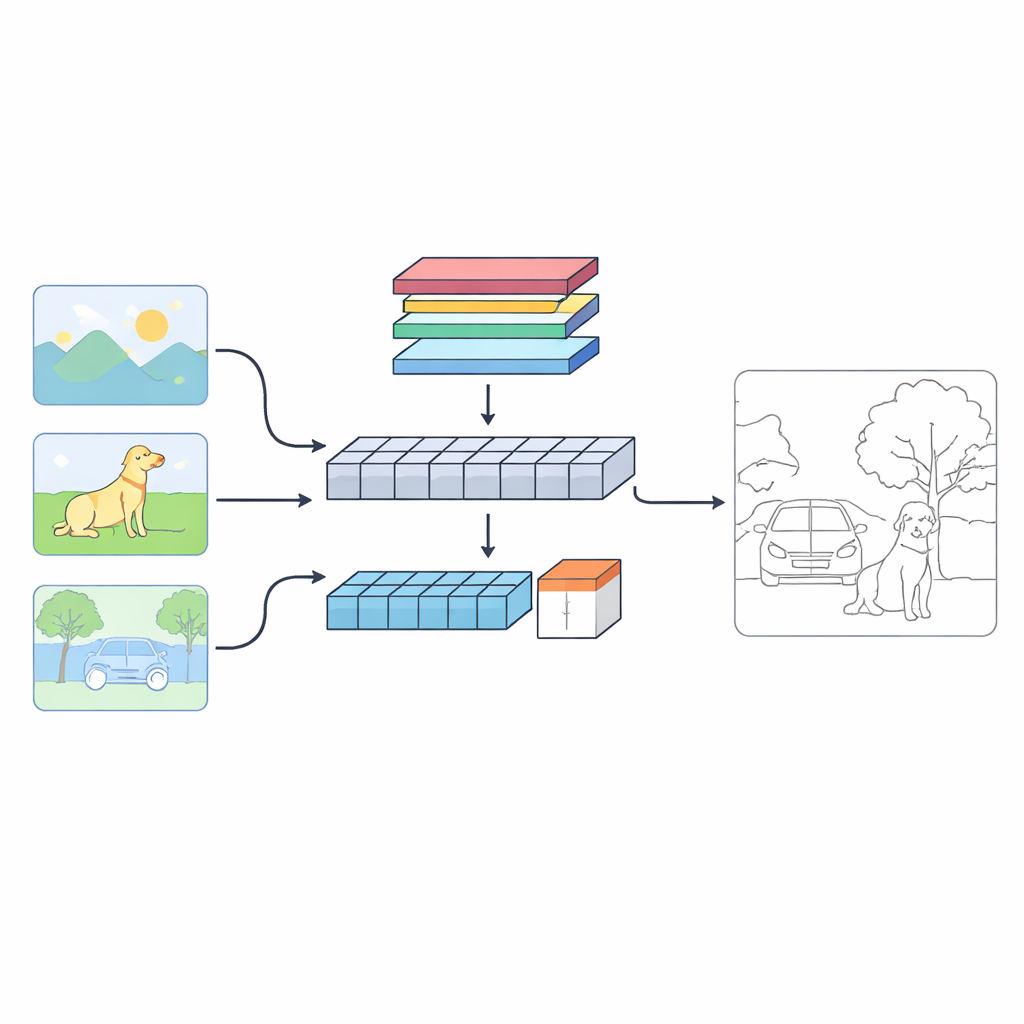
Een nieuwe kijk op hoe machines grenzen vinden
Vroege computer-visie instrumenten, zoals klassieke randdetectoren uit de jaren tachtig, keken naar kleine pixelbuurten en markeerden waar de helderheid abrupt veranderde. Ze waren snel, maar raakten gemakkelijk in de war door textuur, schaduwen of ruis. Moderne diepe netwerken verbeterden dit door te leren van grote beeldverzamelingen en door vele lagen te stapelen om randen op verschillende schalen te herkennen. Toch behandelen de meeste van deze methoden nog steeds elke pixel als een geïsoleerde ja-of-nee beslissing: "rand" of "geen rand." Deze pixel-voor-pixel benadering negeert dat grenzen in de echte wereld gladde, verbonden krommen met een consistente richting zijn, geen willekeurige vlekken. Daardoor kunnen netwerken goede numerieke scores behalen terwijl de omtrekken voor het oog toch gebroken of onscherp lijken.
Een netwerk met twee “ogen” per afbeelding
De auteurs stellen een tweekoppig systeem voor, C‑TDED, dat elke afbeelding op twee aanvullende manieren bekijkt. De ene tak is gebaseerd op convolutionele neurale netwerken en blijft dicht bij de oorspronkelijke resolutie van de afbeelding. Deze tak is gespecialiseerd in het vastleggen van fijne details zoals haartjes, objectcontouren en kleine hoeken. De andere tak gebruikt een transformer-achtige opzet, die goed is in het vastleggen van langeafstandsrelaties en de algemene lay-out van de scène — en begrijpt bijvoorbeeld dat een boomstam en zijn takken bij hetzelfde object horen, ook als ze ver uit elkaar staan in het beeld. Een speciaal fusie‑module combineert vervolgens deze twee gezichtspunten, met aandacht en rand‑behoudende bewerkingen om delicate details te behouden terwijl de globale context gerespecteerd blijft. Samen werken de takken als een vergrootglas en een groothoeklens die in harmonie samenwerken.
Het netwerk leren wat een “goede” rand werkelijk is
De kerninnovatie is niet alleen de architectuur, maar ook de manier waarop het netwerk wordt getraind — de verliesfunctie. In plaats van het netwerk alleen te belonen voor het matchen van de juiste pixels, ontwerpen de auteurs een structuur-bewuste loss die drie intuïtieve eigenschappen van goede randen vastlegt. Ten eerste moedigt een gradiëntterm sterke, scherpe overgangen aan bij grenzen in plaats van vage hellingen. Ten tweede bestraft een continuïteitsterm gaps en abrupte onderbrekingen langs een rand, waardoor het model wordt aangespoord ononderbroken lijnen te tekenen. Ten derde vraagt een richtingsterm dat aangrenzende randsegmenten in consistente richtingen wijzen, waardoor gekartelde of zigzagpatronen worden ontmoedigd. Deze ingrediënten worden gecombineerd met standaard verlies-termen die klasse-ongelijkheid en regio-overlap afhandelen, en vormen zo een verenigd doel dat beter weerspiegelt wat mensen waarnemen als een nette omtrek.
Geleidelijk leren van makkelijk naar moeilijk
Om de training stabiel en efficiënt te maken, introduceren de auteurs een driedelige schema die het belang van verschillende verliescomponenten in de tijd verandert. In het begin concentreert het netwerk zich op het simpelweg vinden van de juiste pixels, met traditionele pixelniveau-termen om een ruwe schets van de randen te vinden. In de middenfase verschuift de nadruk naar het vormen van complete regio’s en continue contouren. In de laatste fase nemen structurele termen gerelateerd aan scherpte en richting het over en polijsten de omtrekken tot scherpe, geometrisch coherente vormen. Deze curriculumachtige aanpak helpt het model te voorkomen dat het vastloopt in slechte oplossingen en verbetert gestaag zowel numerieke prestaties als visuele kwaliteit.
Scherpere omtrekken met minder rekenkundige ballast
Getest op meerdere standaard benchmarks, waaronder natuurfoto’s en binnenscènes met diepte-informatie, evenaart of overtreft de nieuwe methode consequent toonaangevende concurrenten. Het behaalt topposities op belangrijke kwaliteitsmaten terwijl het minder parameters gebruikt dan veel rivaliserende netwerken, wat het aantrekkelijk maakt voor systemen in de praktijk die snel moeten draaien of op beperkte hardware. Voor niet-experts is de conclusie eenvoudig: door het netwerk een duidelijke notie te geven van wat een rand "juist" doet lijken — sterk, ononderbroken en soepel georiënteerd — brengt dit werk computergezichtsvermogen een stap dichter bij hoe mensen intuïtief objectgrenzen waarnemen, wat zorgt voor accuratere en betrouwbaardere beeldinterpretatie.
Bronvermelding: Jiang, J., Guo, J. & Yang, Z. A CNN-transformer dual-branch network with structure-aware loss for high-resolution edge detection. Sci Rep 16, 14191 (2026). https://doi.org/10.1038/s41598-026-44362-2
Trefwoorden: randdetectie, computer visie, diep leren, beeldsegmentatie, transformer netwerken