Clear Sky Science · sv
En CNN-transformer tvågrensnätverk med strukturmedveten förlust för högupplöst kantdetektion
Varför skarpa konturer är viktiga i digitala bilder
Oavsett om en bil ska detekteras i en självkörande scen, en tumör ska markeras i en medicinsk skanning eller ett foto omvandlas till en prydlig skiss, förlitar sig datorer på att hitta tydliga kanter—gränserna mellan objekt. Ändå återger även dagens kraftfulla djupinlärningssystem ofta dessa konturer som avbrutna, suddiga eller något förskjutna linjer. Denna artikel presenterar ett nytt sätt att lära neurala nätverk att rita renare, mer kontinuerliga kanter i högupplösta bilder, vilket gör efterföljande visionsuppgifter mer robusta och visuellt övertygande.
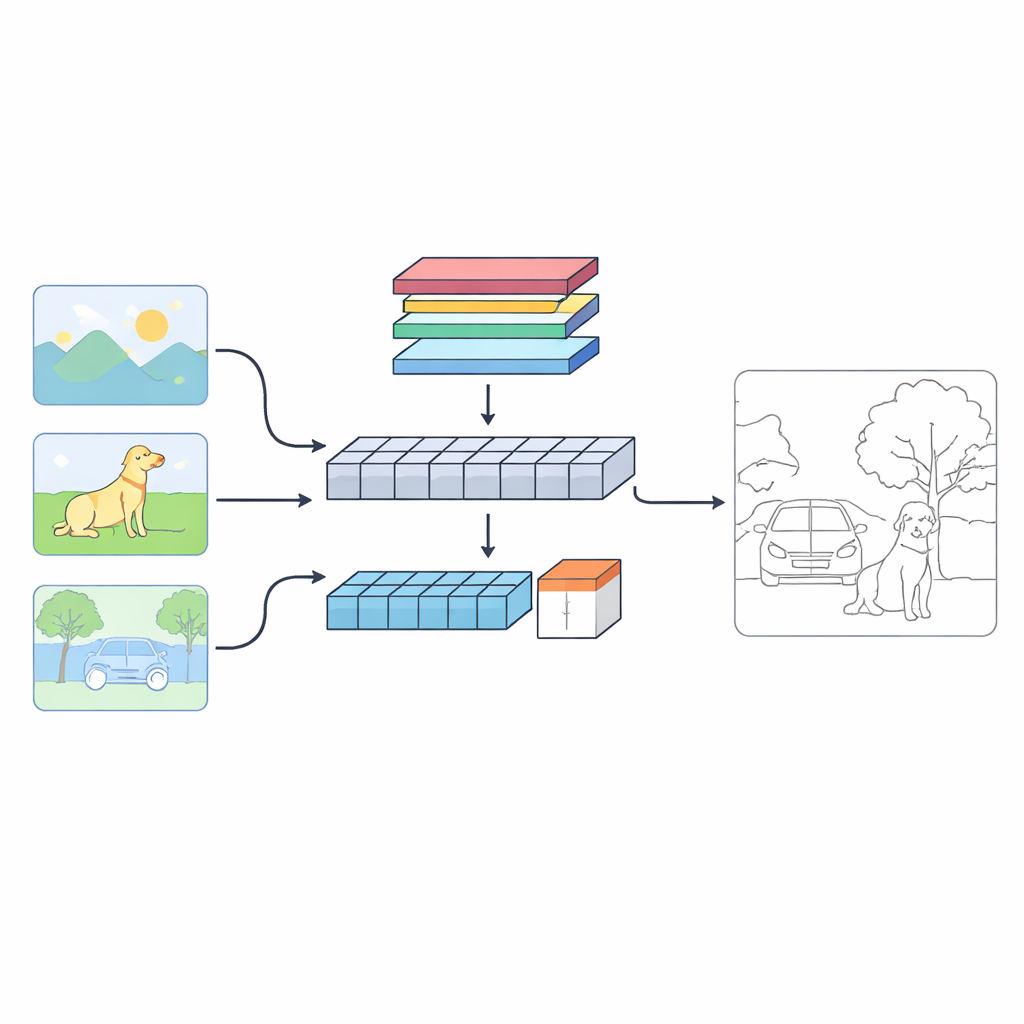
En ny syn på hur maskiner finner gränser
Tidiga datorseendeverktyg, som klassiska kantdetektorer från 1980‑talet, såg på små pixelnaboheter och markerade där ljusstyrkan förändrades abrupt. De var snabba men förväxlades lätt av textur, skuggor eller brus. Moderna djupa nätverk förbättrade saken genom att lära från stora bildsamlingar och stapla många lager för att känna igen kanter i olika skalor. De flesta av dessa metoder behandlar dock fortfarande varje pixel som ett isolerat ja–eller–nej‑beslut: ”kant” eller ”inte kant.” Denna pixel‑för‑pixel‑syn bortser från att verkliga gränser är jämna, sammanhängande kurvor med en konsekvent riktning, inte slumpmässiga prickar. Som ett resultat kan nätverk uppnå goda numeriska poäng samtidigt som de producerar konturer som ser avbrutna eller suddiga ut för ögat.
Ett nätverk med två ”ögon” per bild
Författarna föreslår ett tvågrenssystem kallat C‑TDED som betraktar varje bild på två kompletterande sätt. Den ena grenen baseras på konvolutionella neurala nätverk och behåller nära originalupplösningen. Den är specialiserad på att fånga fina detaljer som hårstrån, objektskonturer och små hörn. Den andra grenen använder en transformer‑liknande design, vilket är bra för att fånga långdistansrelationer och den övergripande scenlayouten—att förstå till exempel att en trädstam och dess grenar tillhör samma objekt även om de är långt ifrån varandra i bilden. En dedikerad fusionsmodul kombinerar sedan dessa två vyer, med uppmärksamhetsmekanismer och kantbevarande operationer för att behålla ömtåliga detaljer samtidigt som den respekterar global kontext. Tillsammans fungerar grenarna som ett förstoringsglas och en vidvinkelobjektiv i samspel.
Att lära nätverket vad en "bra" kant egentligen är
Den centrala nyheten är inte bara arkitekturen utan hur nätverket tränas—dess förlustfunktion. Istället för att bara belöna nätverket för att matcha rätt pixlar utformar författarna en strukturmedveten förlust som kodar tre intuitiva egenskaper hos bra kanter. För det första uppmuntrar ett gradientvillkor starka, skarpa övergångar vid gränser istället för suddiga lutningar. För det andra straffar ett kontinuitetsvillkor luckor och plötsliga brott längs en kant, vilket driver modellen att rita obrutna linjer. För det tredje uppmanar ett riktningsvillkor intilliggande kantsegment att peka i konsekventa riktningar, vilket motverkar taggiga eller zickzackmönster. Dessa ingredienser kombineras med standardförlusttermer som hanterar klassobalans och regionsöverlagring, och bildar ett enhetligt mål som bättre reflekterar vad människor uppfattar som en ren kontur.
Att lära sig successivt från lätt till svårt
För att göra träningen stabil och effektiv introducerar författarna ett trestegs‑schema som förändrar vikten av olika förlustkomponenter över tid. I början koncentrerar sig nätverket på att helt enkelt få rätt pixlar, med traditionella pixelnivåtermer för att hitta en grov skiss av kanterna. I mellanstadiet skiftar fokus mot att bilda kompletta regioner och kontinuerliga konturer. I det sista steget tar strukturella termer relaterade till skärpa och riktning över och polerar konturerna till klara, geometriskt koherenta former. Detta läroplansliknande tillvägagångssätt hjälper modellen att undvika att fastna i dåliga lösningar och förbättrar stadigt både numerisk prestation och visuell kvalitet.
Skarpare konturer med mindre beräkningsbörd
Testat på flera standardbenchmarks, inklusive naturliga fotografier och inomhusscener med djupinformation, matchar eller överträffar den nya metoden konsekvent ledande konkurrenter. Den uppnår toppresultat på viktiga kvalitetsmått samtidigt som den använder färre parametrar än många rivaliserande nätverk, vilket gör den attraktiv för system i verkliga tillämpningar som måste köras snabbt eller på begränsad hårdvara. För icke‑experter är slutsatsen enkel: genom att ge nätverket en tydlig uppfattning om vad som får en kant att se ”rätt” ut—stark, obruten och mjukt orienterad—förflyttar detta arbete datorseendet ett steg närmare hur människor intuitivt uppfattar objektsgränser, vilket möjliggör mer exakt och pålitlig bildförståelse.
Citering: Jiang, J., Guo, J. & Yang, Z. A CNN-transformer dual-branch network with structure-aware loss for high-resolution edge detection. Sci Rep 16, 14191 (2026). https://doi.org/10.1038/s41598-026-44362-2
Nyckelord: kantdetektion, datorseende, djupinlärning, bildsegmentering, transformernätverk