Clear Sky Science · it
Una rete a doppio ramo CNN-transformer con loss sensibile alla struttura per il rilevamento di bordi ad alta risoluzione
Perché i contorni nitidi sono importanti nelle immagini digitali
Sia che si tratti di rilevare un’auto in una scena per la guida autonoma, delimitare un tumore in una scansione medica o trasformare una foto in uno schizzo ordinato, i computer si affidano all’individuazione di contorni chiari — i confini tra gli oggetti. Eppure anche i potenti sistemi di deep learning di oggi spesso tracciano questi contorni come linee spezzate, sfocate o leggermente spostate. Questo articolo introduce un nuovo modo di insegnare alle reti neurali a tracciare bordi più puliti e continui nelle immagini ad alta risoluzione, rendendo i compiti di visione successivi più affidabili e visivamente convincenti.
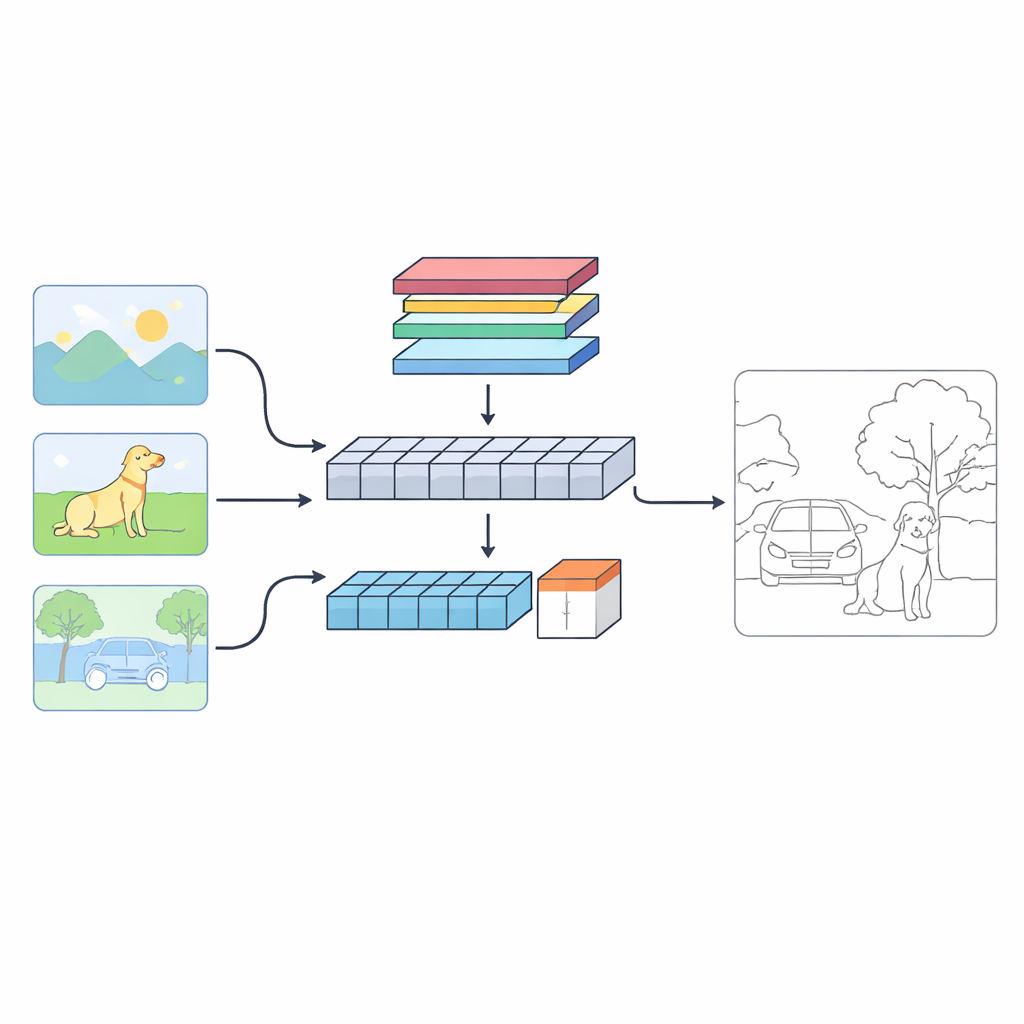
Uno sguardo nuovo a come le macchine trovano i confini
I primi strumenti di computer vision, come i classici rilevatori di bordi degli anni ’80, osservavano piccole vicinanze di pixel e segnalavano dove la luminosità cambiava bruscamente. Erano veloci ma facilmente confondibili da texture, ombre o rumore. Le moderne reti profonde hanno migliorato la situazione imparando da grandi raccolte di immagini, impilando molti strati per riconoscere bordi a scale diverse. Tuttavia, la maggior parte di questi metodi tratta ancora ogni pixel come una decisione isolata sì–o–no: “bordo” o “non bordo”. Questa visione pixel‑per‑pixel ignora il fatto che i confini del mondo reale sono curve lisce e connesse con una direzione coerente, non puntini casuali. Di conseguenza, le reti possono ottenere buoni punteggi numerici pur producendo contorni che all’occhio risultano spezzati o sfocati.
Una rete con due “occhi” sull’immagine
Gli autori propongono un sistema a doppio ramo chiamato C‑TDED che osserva ogni immagine in due modi complementari. Un ramo è basato su reti neurali convoluzionali e rimane vicino alla risoluzione originale dell’immagine. È specializzato nel catturare dettagli fini come capelli, contorni degli oggetti e angoli minuti. L’altro ramo utilizza un design in stile transformer, adatto a cogliere relazioni a lungo raggio e la disposizione globale della scena — comprendendo, ad esempio, che il tronco di un albero e i suoi rami appartengono allo stesso oggetto anche se distanti nell’immagine. Un modulo di fusione dedicato combina poi queste due viste, usando attenzione e operazioni che preservano il bordo per mantenere i dettagli delicati rispettando al contempo il contesto globale. Insieme, i rami funzionano come una lente di ingrandimento e un grandangolo che lavorano in concerto.
Insegnare alla rete cosa sia davvero un “buon” bordo
L’innovazione centrale non è solo l’architettura ma il modo in cui la rete viene addestrata — la sua funzione di perdita. Invece di premiare la rete solo per la corrispondenza dei pixel corretti, gli autori progettano una loss sensibile alla struttura che codifica tre proprietà intuitive dei buoni bordi. Primo, un termine di gradiente incoraggia transizioni forti e nette ai confini piuttosto che ramppe sfocate. Secondo, un termine di continuità penalizza gap e rotture brusche lungo un bordo, spingendo il modello a tracciare linee ininterrotte. Terzo, un termine di direzione richiede che segmenti di bordo vicini puntino in direzioni coerenti, scoraggiando pattern frastagliati o a zigzag. Questi ingredienti sono combinati con termini di perdita standard che gestiscono lo sbilanciamento delle classi e la sovrapposizione delle regioni, formando un obiettivo unificato che riflette meglio ciò che l’essere umano percepisce come un contorno pulito.
Apprendere gradualmente dall’essenziale al complesso
Per rendere l’addestramento stabile ed efficiente, gli autori introducono un programma in tre fasi che modifica nel tempo l’importanza dei diversi componenti di perdita. All’inizio, la rete si concentra semplicemente sull’individuare i pixel corretti, usando termini tradizionali a livello di pixel per trovare uno schizzo grossolano dei bordi. Nella fase centrale, l’enfasi si sposta verso la formazione di regioni complete e contorni continui. Nella fase finale, i termini strutturali relativi a nitidezza e direzione prevalgono, rifinando i contorni in forme nette e coerenti geometricamente. Questo approccio simile a un curriculum aiuta il modello a evitare di restare bloccato in soluzioni scadenti e migliora in modo costante sia le prestazioni numeriche sia la qualità visiva.
Contorni più nitidi con meno peso computazionale
Testato su diversi benchmark standard, incluse fotografie naturali e scene interne con informazioni di profondità, il nuovo metodo eguaglia o supera costantemente i principali concorrenti. Ottiene punteggi di punta su misure chiave di qualità pur usando meno parametri rispetto a molte reti rivali, rendendolo attraente per sistemi reali che devono funzionare rapidamente o su hardware limitato. Per i non esperti, la conclusione è semplice: dando alla rete una nozione chiara di cosa rende un bordo “giusto” — forte, ininterrotto e orientato con coerenza — questo lavoro avvicina la visione artificiale a come gli esseri umani percepiscono intuitivamente i confini degli oggetti, permettendo una comprensione delle immagini più accurata e affidabile.
Citazione: Jiang, J., Guo, J. & Yang, Z. A CNN-transformer dual-branch network with structure-aware loss for high-resolution edge detection. Sci Rep 16, 14191 (2026). https://doi.org/10.1038/s41598-026-44362-2
Parole chiave: rilevamento dei bordi, computer vision, deep learning, segmentazione delle immagini, reti transformer