Clear Sky Science · ar
شبكة ثنائية المسار تعتمد على CNN وTransformer مع خسارة مدركة للهيكل لاكتشاف الحواف عالية الدقة
لماذا تهم الخطوط الواضحة في الصور الرقمية
سواءً كان الأمر يتعلق باكتشاف سيارة في مشهد لقيادة ذاتية، أو تحديد ورم في فحص طبي، أو تحويل صورة إلى رسم مرتب، تعتمد الحواسيب على العثور على حواف واضحة — الحدود بين الأشياء. ومع ذلك، فإن أنظمة التعلّم العميق القوية اليوم غالبًا ما ترسم هذه الخطوط بشكل متقطع أو ضبابي أو غير دقيق قليلًا. تقدم هذه الورقة طريقة جديدة لتعليم الشبكات العصبية رسم حواف أنظف وأكثر استمرارية في الصور عالية الدقة، مما يجعل المهام البصرية اللاحقة أكثر موثوقية وإقناعًا بصريًا.
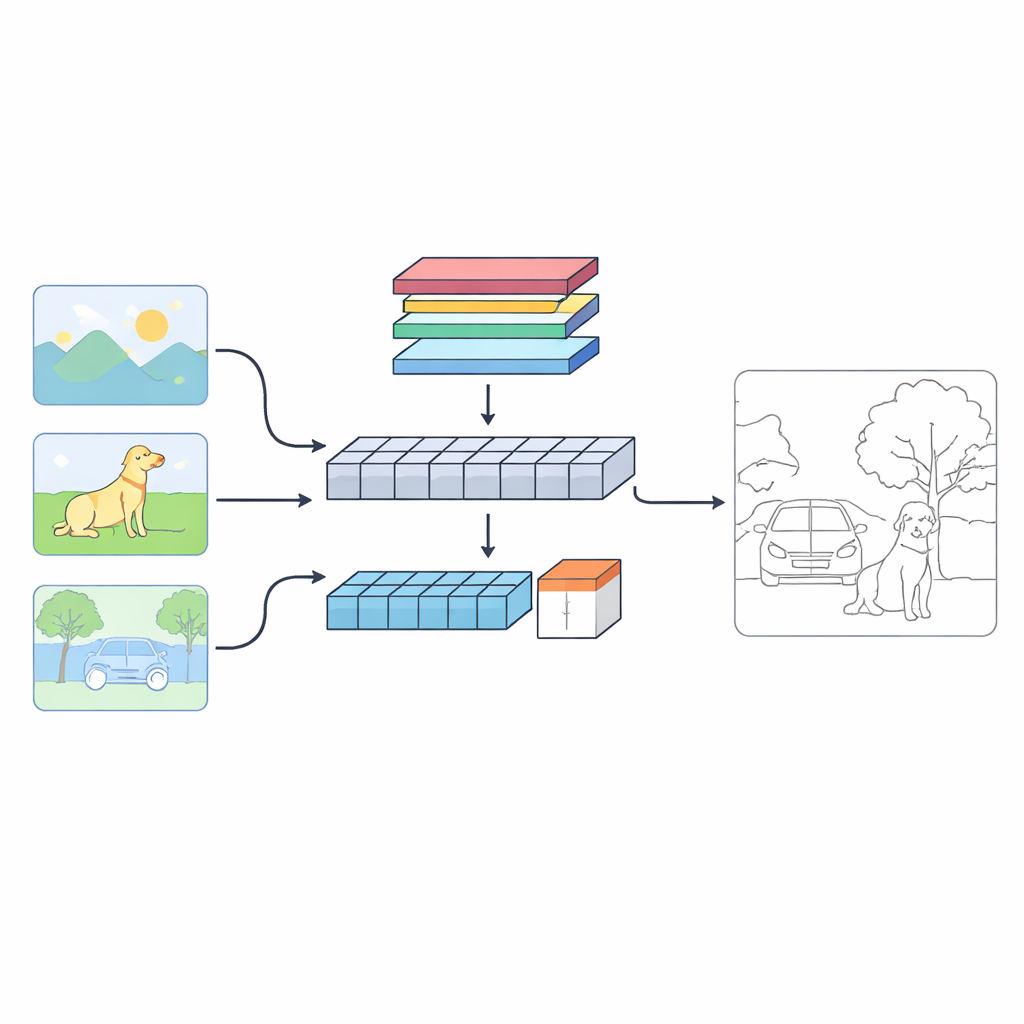
نظرة جديدة على كيفية إيجاد الآلات للحدود
كانت أدوات رؤية الحاسوب المبكرة، مثل مكشوفات الحواف التقليدية من ثمانينيات القرن الماضي، تنظر إلى مناطق صغيرة من البكسلات وتبرز الأماكن التي يتغير فيها السطوع فجأة. كانت سريعة لكنها تتشوش بسهولة بالنمط أو الظلال أو الضوضاء. حسنت الشبكات الحديثة الوضع بتعلّمها من مجموعات صور كبيرة وتكديس طبقات عديدة للتعرّف على الحواف بمقاييس مختلفة. ومع ذلك، لا تزال أغلب هذه الطرق تعامل كل بكسل كقرار منعزل بنعم أو لا: "حافة" أو "ليست حافة". هذه النظرة بكسل-ببكسل تتجاهل أن الحدود في العالم الحقيقي منحنيات سلسة ومترابطة ذات اتّجاه ثابت، وليست نقاطًا عشوائية. ونتيجة لذلك، قد تحقق الشبكات درجات رقمية جيدة بينما تنتج مخططات تبدو مكسورة أو ضبابية للعين.
شبكة بعينين على كل صورة
يقترح المؤلفون نظامًا ثنائي المسار يُدعى C‑TDED ينظر إلى كل صورة بطريقتين متكاملتين. أحد المسارين مبني على الشبكات التلافيفية (CNN) ويحتفظ بدرجة وضوح قريبة من دقة الصورة الأصلية. هذا المسار متخصص في التقاط التفاصيل الدقيقة مثل خيوط الشعر، محيط الأشياء، والزوايا الصغيرة. المسار الآخر يستخدم تصميمًا على غرار الـ Transformer، وهو جيد في التقاط العلاقات بعيدة المدى وتخطيط المشهد العام — فهم، على سبيل المثال، أن جذع شجرة وفروعه ينتمون إلى نفس الكائن حتى لو تباعدا في الصورة. يدمج وحدة دمج مخصصة هذين العرضين، مستخدمة الانتباه وعمليات الحفاظ على الحافة للحفاظ على التفاصيل الرقيقة مع احترام السياق العام. معًا يعمل المساران مثل عدسة مكبّرة وعدسة واسعة الزاوية تعملان بشكل متكامل.
تعليم الشبكة ما هي "الحافة الجيدة" فعلاً
الابتكار الجوهري ليس في البنية وحدها بل في طريقة تدريب الشبكة — دالة الخسارة. بدلًا من مكافأة الشبكة فقط على مطابقة البكسلات الصحيحة، صمّم المؤلفون خسارة مدركة للهيكل تُشفّر ثلاث خصائص بديهية للحواف الجيدة. أولًا، مكوّن التدرّج يشجّع على انتقالات قوية وحادة عند الحدود بدلًا من التدرّجات الضبابية. ثانيًا، مكوّن الاستمرارية يعاقب الفجوات والانقطاعات المفاجئة على طول الحافة، دافعًا النموذج لرسم خطوط غير منقطعة. ثالثًا، مكوّن الاتجاه يطلب أن تشير مقاطع الحافة المجاورة في اتجاهات متسقة، مقللاً من النماط المسننة أو المتعرجة. تُدمج هذه المكونات مع مصطلحات خسارة معيارية تتعامل مع عدم التوازن بين الفئات وتداخل المناطق، مكونة هدفًا موحدًا يعكس بشكل أفضل ما يدركه البشر كخط خارجي نظيف.
التعلم تدريجيًا من السهل إلى الصعب
لجعل التدريب مستقرًا وكفءًا، يقدّم المؤلفون جدولًا ثلاثي المراحل يغيّر أهمية مكوّنات الخسارة المختلفة مع الزمن. في البداية، تركز الشبكة على الحصول على البكسلات الصحيحة ببساطة، مستخدمة مصطلحات تقليدية على مستوى البكسل لرسم مخطط تقريبي للحواف. في المرحلة الوسطى، يتحول التركيز نحو تشكيل مناطق كاملة ومحيطات متصلة. في المرحلة النهائية، تستحوذ المصطلحات الهيكلية المتعلقة بالحدة والاتجاه على التدريب، مصقولة الخطوط إلى أشكال واضحة ومتسقة هندسيًا. تساعد هذه المقاربة الشبيهة بالمنهج الدراسي النموذج على تفادي الوقوع في حلول ضعيفة وتحسّن تدريجيًا كلًا من الأداء الرقمي والجودة المرئية.
خطوط أوضح مع عبء حسابي أقل
اختُبرت الطريقة في عدة معايير قياسية، بما في ذلك الصور الفوتوغرافية الطبيعية والمشاهد الداخلية التي تحتوي على معلومات عمق، فحققت الطريقة الجديدة نتائج تعادل أو تتجاوز أبرز المتنافسين باستمرار. تحقق أعلى الدرجات في مقاييس الجودة الرئيسية بينما تستخدم عدد معالم (Parameters) أقل من العديد من الشبكات المنافسة، مما يجعلها جذابة للأنظمة العملية التي يجب أن تعمل بسرعة أو على أجهزة محدودة الموارد. للقراء غير المتخصصين، الخلاصة بسيطة: من خلال تزويد الشبكة بمفهوم واضح لما يجعل الحافة تبدو "صحيحة" — قوية، غير منقطعة، ومتجهة بسلاسة — تقرب هذه الدراسة رؤية الحاسوب خطوة إلى كيفية رؤية البشر لحدود الأشياء، مما يمكّن فهمًا أدق وأكثر موثوقية للصور.
الاستشهاد: Jiang, J., Guo, J. & Yang, Z. A CNN-transformer dual-branch network with structure-aware loss for high-resolution edge detection. Sci Rep 16, 14191 (2026). https://doi.org/10.1038/s41598-026-44362-2
الكلمات المفتاحية: كشف الحواف, رؤية الحاسوب, التعلّم العميق, تجزيء الصور, شبكات الـ Transformer