Clear Sky Science · de
Ein CNN-Transformer-Dualzweig-Netzwerk mit strukturbewusstem Verlust für hochauflösende Kantenerkennung
Warum scharfe Konturen in digitalen Bildern wichtig sind
Ob in einer Szene für selbstfahrende Fahrzeuge ein Auto erkannt, in einer medizinischen Aufnahme ein Tumor umrandet oder ein Foto in eine saubere Skizze verwandelt werden soll: Computer sind darauf angewiesen, klare Kanten zu finden – die Grenzen zwischen Objekten. Dennoch zeichnen selbst heutige leistungsfähige Deep‑Learning‑Systeme diese Konturen oft als unterbrochene, verschwommene oder leicht fehlplatzierte Linien. Dieses Papier stellt eine neue Methode vor, Netzwerke so zu trainieren, dass sie in hochauflösenden Bildern sauberere, kontinuierlichere Kanten erzeugen, wodurch nachgelagerte Vision‑Aufgaben zuverlässiger und visueller überzeugender werden.
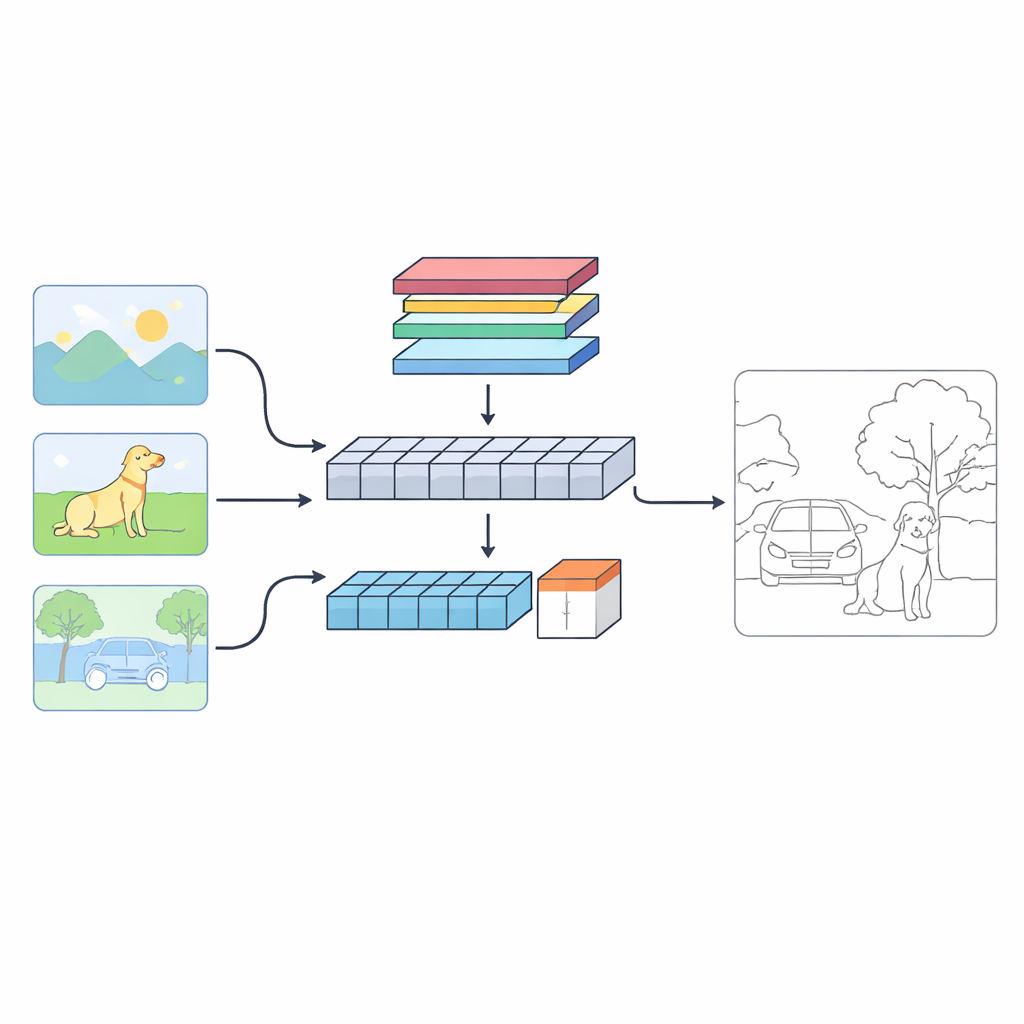
Ein neuer Blick darauf, wie Maschinen Grenzen finden
Frühe Computer‑Vision‑Werkzeuge, etwa klassische Kantendetektoren aus den 1980er‑Jahren, betrachteten kleine Pixelnachbarschaften und hoben Bereiche hervor, in denen die Helligkeit abrupt wechselte. Sie waren schnell, ließen sich aber leicht durch Textur, Schatten oder Rauschen verwirren. Moderne tiefe Netze verbesserten die Lage, indem sie aus großen Bildsammlungen lernten und viele Schichten stapelten, um Kanten auf verschiedenen Skalen zu erkennen. Dennoch behandeln die meisten dieser Methoden weiterhin jedes Pixel als isolierte Ja‑oder‑Nein‑Entscheidung: „Kante“ oder „keine Kante“. Diese Pixel‑für‑Pixel‑Betrachtung ignoriert, dass reale Grenzen glatte, zusammenhängende Kurven mit einer konsistenten Richtung sind, nicht zufällige Partikel. Infolgedessen können Netze gute numerische Werte erzielen und trotzdem Konturen produzieren, die dem Auge gebrochen oder unscharf erscheinen.
Ein Netzwerk mit zwei „Augen“ pro Bild
Die Autorinnen und Autoren schlagen ein Dualzweig‑System namens C‑TDED vor, das jedes Bild auf zwei komplementäre Arten betrachtet. Ein Zweig basiert auf Faltungsnetzwerken (CNN) und bleibt nahe an der ursprünglichen Auflösung des Bildes. Er ist spezialisiert auf das Erfassen feiner Details wie Haarlinien, Objektkonturen und winziger Ecken. Der andere Zweig nutzt ein Transformer‑ähnliches Design, das gut darin ist, langreichweitige Beziehungen und die Gesamtanordnung der Szene zu erfassen – etwa zu erkennen, dass ein Baumstamm und seine Äste zum gleichen Objekt gehören, auch wenn sie weit auseinanderliegen. Ein spezielles Fusionsmodul kombiniert dann diese beiden Sichtweisen und verwendet Attention‑ und kantenerhaltende Operationen, um zarte Details zu bewahren und gleichzeitig den globalen Kontext zu respektieren. Zusammen wirken die Zweige wie eine Lupe und ein Weitwinkelobjektiv, die im Zusammenspiel arbeiten.
Dem Netzwerk beibringen, was eine „gute“ Kante wirklich ist
Die Kerninnovation liegt nicht nur in der Architektur, sondern in der Art des Trainings – der Verlustfunktion. Anstatt das Netzwerk nur dafür zu belohnen, die richtigen Pixel zu treffen, entwerfen die Autorinnen und Autoren einen strukturbewussten Verlust, der drei intuitive Eigenschaften guter Kanten kodiert. Erstens fördert ein Gradiententerm starke, scharfe Übergänge an Grenzen statt verschwommener Rampen. Zweitens bestraft ein Kontinuitätsterm Lücken und abrupte Unterbrechungen entlang einer Kante und zwingt das Modell dazu, durchgehende Linien zu zeichnen. Drittens fordert ein Richtungsterm benachbarte Kantensegmente auf, in konsistenten Richtungen zu zeigen, um gezackte oder gezitterte Muster zu vermeiden. Diese Bestandteile werden mit Standardverlusten zur Behandlung von Klassenungleichgewicht und Flächenüberlappung kombiniert und bilden ein einheitliches Ziel, das besser widerspiegelt, was Menschen als saubere Kontur wahrnehmen.
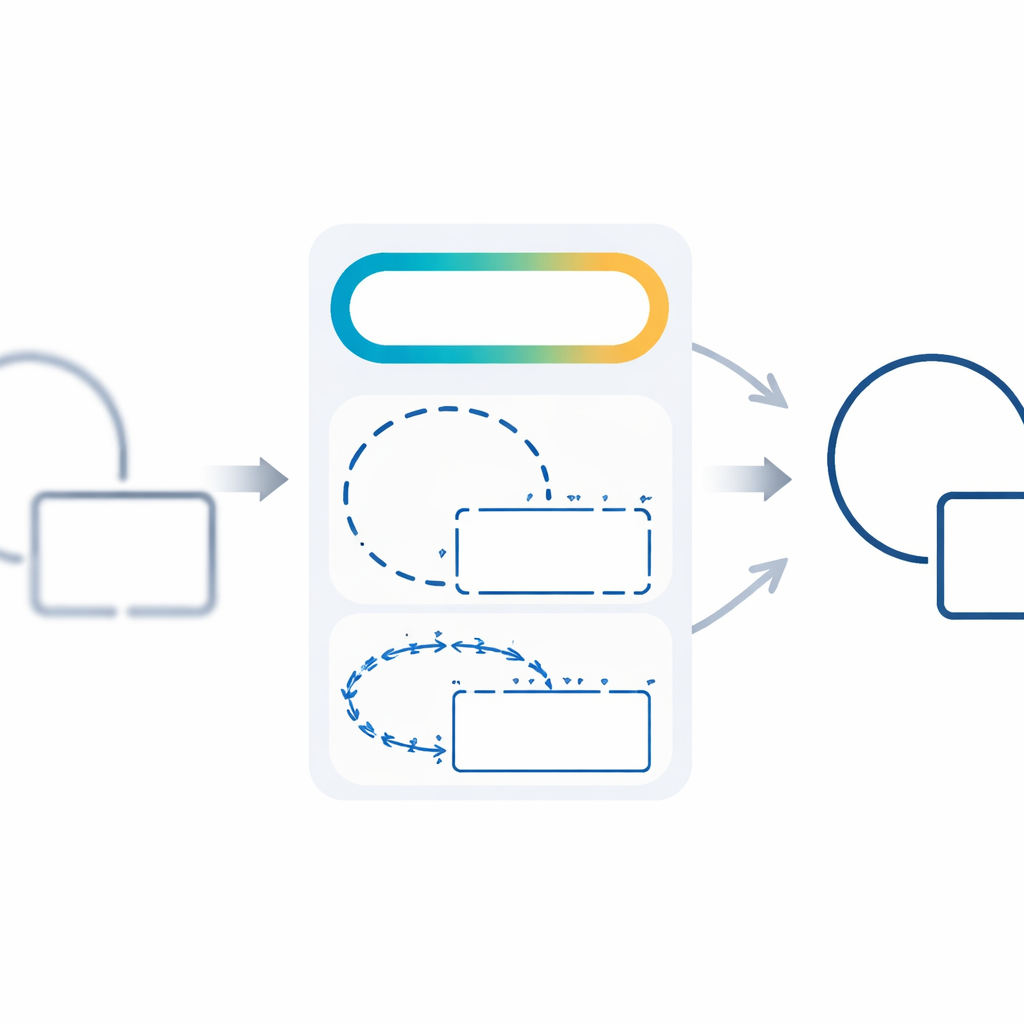
Schrittweises Lernen von einfach zu schwer
Um das Training stabil und effizient zu machen, führen die Autorinnen und Autoren einen dreistufigen Zeitplan ein, der die Bedeutung verschiedener Verlustkomponenten im Verlauf verändert. Zu Beginn konzentriert sich das Netzwerk darauf, einfach die richtigen Pixel zu finden, und verwendet traditionelle pixelbasierte Terme, um eine grobe Skizze der Kanten zu erhalten. In der mittleren Phase verlagert sich der Fokus darauf, vollständige Regionen und zusammenhängende Konturen zu formen. In der letzten Phase übernehmen strukturelle Terme zu Schärfe und Richtung das Ruder und polieren die Konturen zu klaren, geometrisch kohärenten Formen. Dieser lehrplanähnliche Ansatz hilft dem Modell, nicht in schlechten Lösungen stecken zu bleiben, und verbessert sowohl die numerische Leistung als auch die visuelle Qualität stetig.
Scharfere Konturen mit weniger Rechenaufwand
Getestet auf mehreren Standard‑Benchmarks, einschließlich Naturfotografien und Innenraumszenen mit Tiefeninformationen, erreicht die neue Methode durchgehend gleichwertige oder bessere Ergebnisse als führende Konkurrenz. Sie erzielt Spitzenwerte bei wichtigen Qualitätsmaßen und verwendet dabei weniger Parameter als viele rivalisierende Netzwerke, was sie attraktiv für reale Systeme macht, die schnell laufen oder auf begrenzter Hardware eingesetzt werden müssen. Für Nicht‑Expertinnen und Nicht‑Experten lautet die Erkenntnis einfach: Indem dem Netzwerk ein klares Verständnis dafür gegeben wird, was eine Kante „richtig“ aussehen lässt – stark, ungebrochen und gleichmäßig ausgerichtet – rückt diese Arbeit die Computer Vision einen Schritt näher an die intuitive Wahrnehmung von Objektgrenzen durch Menschen und ermöglicht eine genauere und zuverlässigere Bildinterpretation.
Zitation: Jiang, J., Guo, J. & Yang, Z. A CNN-transformer dual-branch network with structure-aware loss for high-resolution edge detection. Sci Rep 16, 14191 (2026). https://doi.org/10.1038/s41598-026-44362-2
Schlüsselwörter: Kantenerkennung, Computer Vision, Tiefes Lernen, Bildsegmentierung, Transformer-Netzwerke