Clear Sky Science · en
A CNN-transformer dual-branch network with structure-aware loss for high-resolution edge detection
Why sharp outlines matter in digital images
Whether a car is being detected in a self-driving scene, a tumor is being outlined in a medical scan, or a photo is being turned into a neat sketch, computers rely on finding clear edges—the boundaries between objects. Yet even today’s powerful deep-learning systems often draw these outlines as broken, fuzzy, or slightly misplaced lines. This paper introduces a new way to teach neural networks to draw cleaner, more continuous edges in high‑resolution images, making downstream vision tasks more reliable and visually convincing.
A fresh look at how machines find boundaries
Early computer-vision tools, such as classic edge detectors from the 1980s, looked at tiny neighborhoods of pixels and highlighted where brightness changed abruptly. They were fast but easily confused by texture, shadows, or noise. Modern deep networks improved matters by learning from large image collections, stacking many layers to recognize edges at different scales. However, most of these methods still treat every pixel as an isolated yes–or–no decision: “edge” or “not edge.” This pixel-by-pixel view ignores the fact that real-world boundaries are smooth, connected curves with a consistent direction, not random specks. As a result, networks can achieve good numerical scores while still producing outlines that look broken or blurry to the eye.
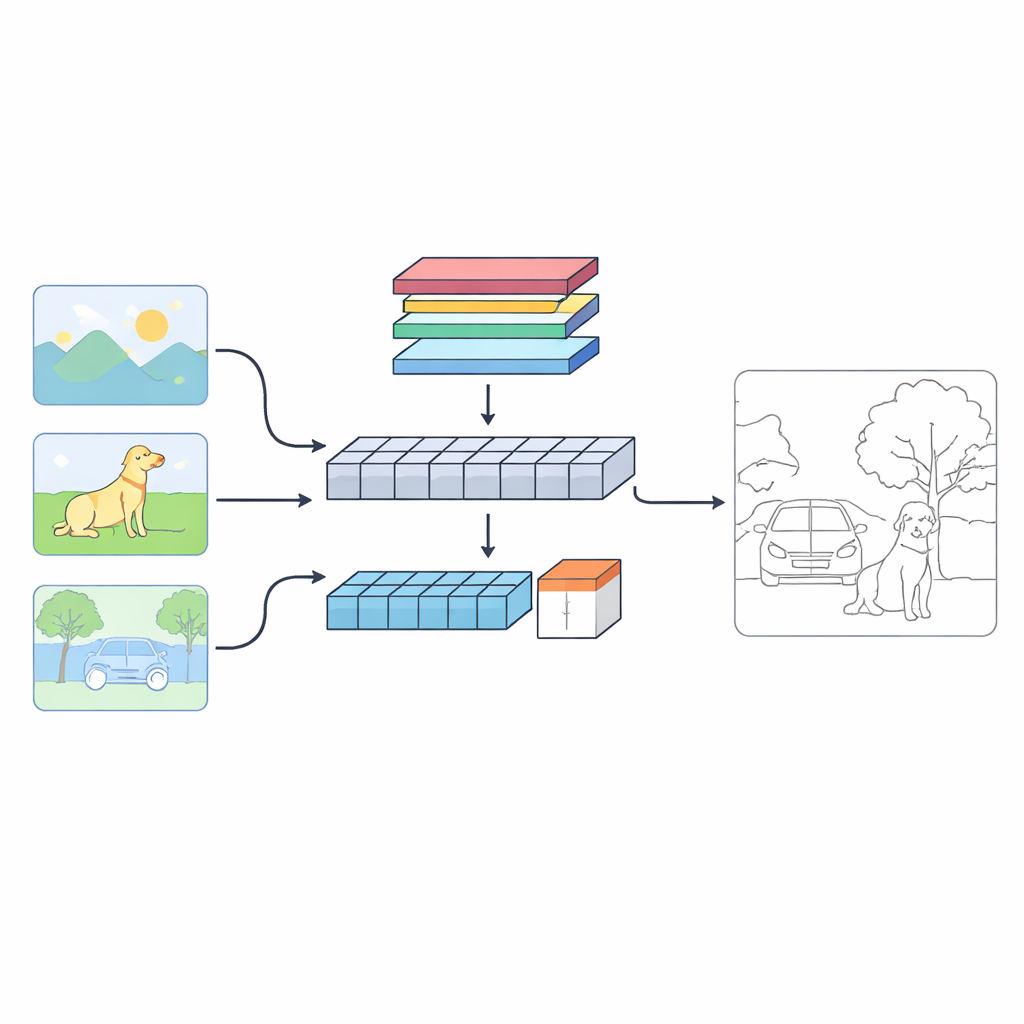
A network with two “eyes” on each image
The authors propose a dual-branch system called C‑TDED that looks at each image in two complementary ways. One branch is based on convolutional neural networks and stays close to the original resolution of the image. It is specialized for capturing fine details such as hairlines, object contours, and tiny corners. The other branch uses a transformer-style design, which is good at capturing long-range relationships and overall scene layout—understanding, for example, that a tree trunk and its branches belong to the same object even if they are far apart in the image. A dedicated fusion module then combines these two views, using attention and edge-preserving operations to keep delicate details while still respecting the global context. Together, the branches act like a magnifying glass and a wide-angle lens working in concert.
Teaching the network what a “good” edge really is
The core innovation is not just the architecture but the way the network is trained—its loss function. Instead of only rewarding the network for matching the correct pixels, the authors design a structure-aware loss that encodes three intuitive properties of good edges. First, a gradient term encourages strong, sharp transitions at boundaries rather than fuzzy ramps. Second, a continuity term penalizes gaps and abrupt breaks along an edge, pushing the model to draw unbroken lines. Third, a direction term asks neighboring edge segments to point in consistent directions, discouraging jagged or zigzag patterns. These ingredients are combined with standard loss terms that handle class imbalance and region overlap, forming a unified objective that better reflects what humans perceive as a clean outline.
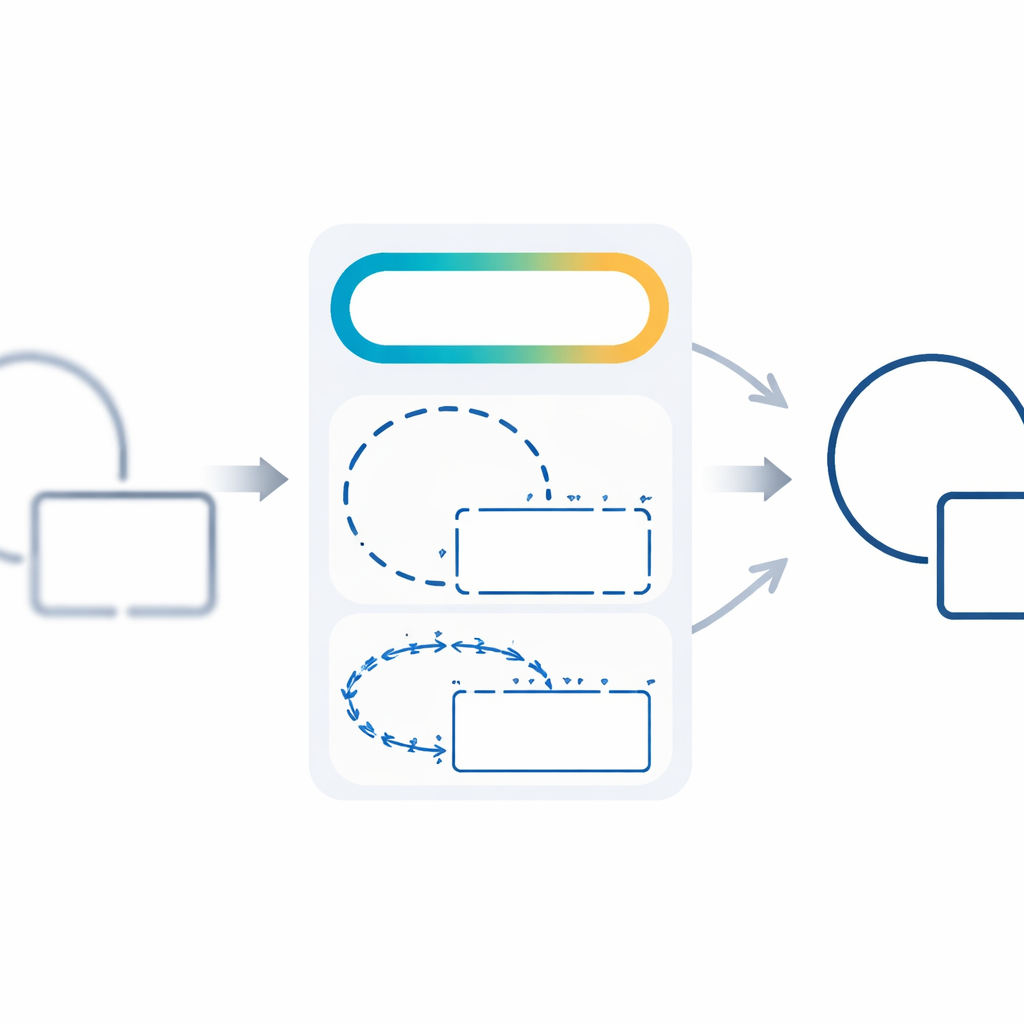
Learning gradually from easy to hard
To make training stable and efficient, the authors introduce a three-stage schedule that changes the importance of different loss components over time. At the beginning, the network concentrates on simply getting the right pixels, using traditional pixel-level terms to find a rough sketch of the edges. In the middle stage, the emphasis shifts toward forming complete regions and continuous contours. In the final stage, structural terms related to sharpness and direction take over, polishing the outlines into crisp, geometrically coherent shapes. This curriculum-like approach helps the model avoid getting stuck in poor solutions and steadily improves both numerical performance and visual quality.
Sharper outlines with less computational baggage
Tested on several standard benchmarks, including natural photographs and indoor scenes with depth information, the new method consistently matches or surpasses leading competitors. It achieves top scores on key quality measures while using fewer parameters than many rival networks, making it attractive for real-world systems that must run quickly or on limited hardware. For non-experts, the takeaway is simple: by giving the network a clear notion of what makes an edge look “right”—strong, unbroken, and smoothly oriented—this work moves computer vision a step closer to how humans intuitively see object boundaries, enabling more accurate and reliable image understanding.
Citation: Jiang, J., Guo, J. & Yang, Z. A CNN-transformer dual-branch network with structure-aware loss for high-resolution edge detection. Sci Rep 16, 14191 (2026). https://doi.org/10.1038/s41598-026-44362-2
Keywords: edge detection, computer vision, deep learning, image segmentation, transformer networks