Clear Sky Science · zh
使用关联数据进行大数据管理的数据迁移与集成方法
为何整理混乱数据至关重要
每一次搜索、点击、传感器读数和在线购买都在增加一片看不见的信息海洋。这些“大数据”大多是混乱的:电子邮件与网页、日志与文档,以及更传统的数据库。公司和研究者都知道这些信息中蕴含着有价值的见解,但数据分散在不同的格式中,彼此之间并不天然互通。本文提出了一种方法,将这种混杂的数据转化为一个单一且良好互联的数据网络,使计算机能够更智能地理解和分析这些信息。
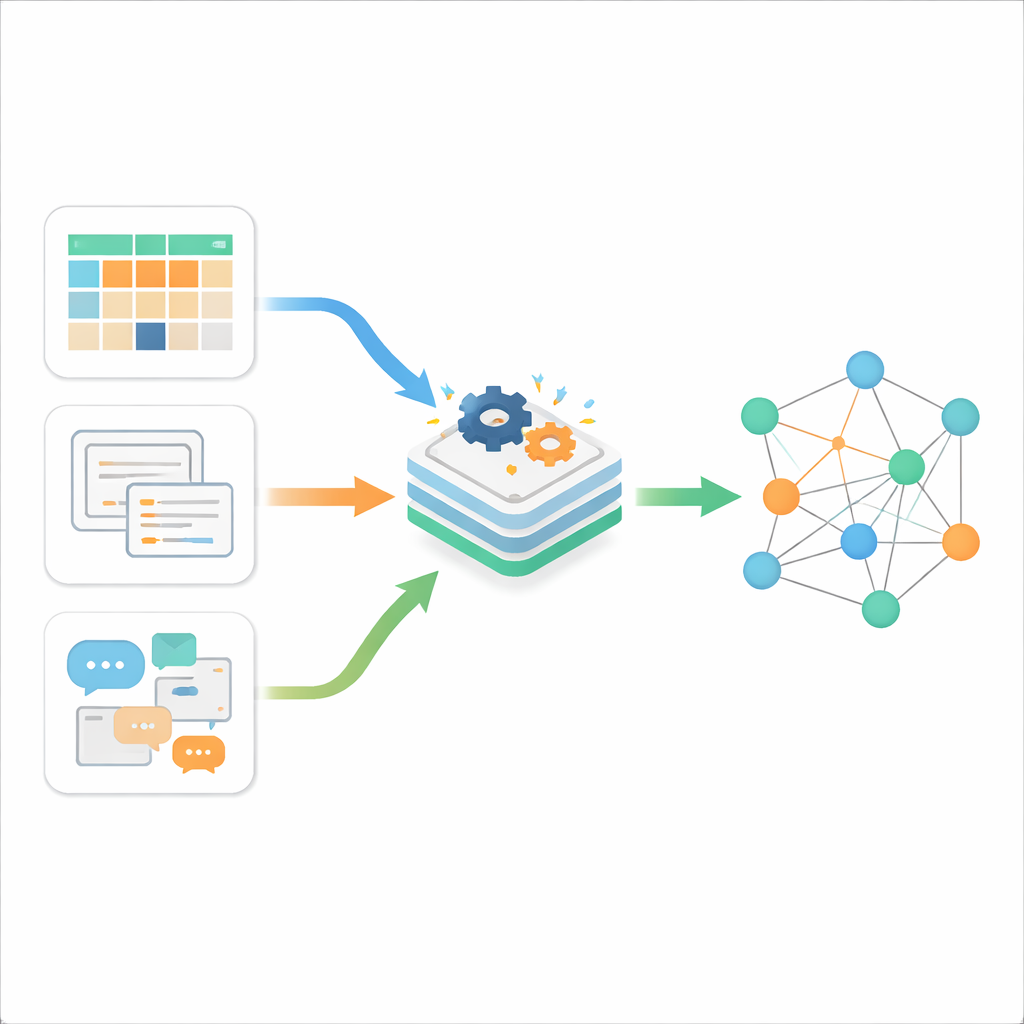
三类数字杂乱
作者首先解释了在线信息通常有三种形式。结构化数据是整齐有序的,存储在具有行列的表格中,例如传统的业务数据库。半结构化数据有一定组织但不遵循严格的表格布局;例如网页、XML、JSON 文件或电子邮件。非结构化数据占大多数——自由文本、文档和不遵循固定模板的其他内容。传统工具可以较好地处理其中一种类型,但当今的现实是三种类型同时、高速地产生,来自网络、智能手机和物联网。核心挑战不仅在于存储这些数据,还在于以有意义的方式让它们相互通信。
从数据孤岛到互联网络
为弥合这些孤岛,作者基于关联数据(Linked Data)的思想,这是一种描述信息的方式,使得事实可以跨来源连接,有点类似于机器可读版本并扩展了维基百科的链接网络。关联数据依赖一种名为 RDF 的标准,将知识分解为简单的“三元组”,表明一件事物如何与另一件事物相关。论文提出了一个统一框架,自动将结构化表格、半结构化文件和纯文本转换为这种关联格式。与其为每种来源构建单独的转换工具,框架将所有输入通过一个两部分的管道处理:分析模块负责判断正在处理的数据类型,合成模块则将该理解转化为互联的 RDF 声明。
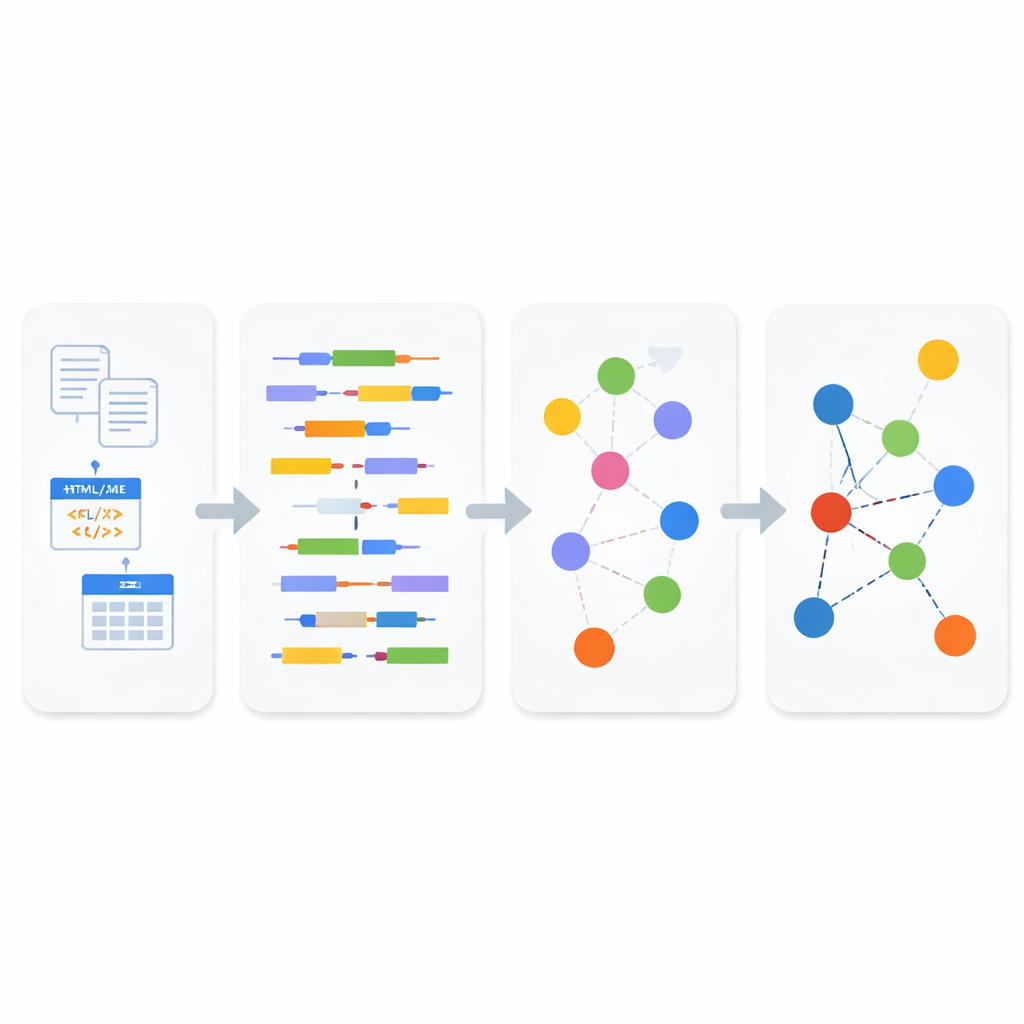
新管道如何工作
在分析模块内部,传入数据首先被分类为结构化、半结构化或非结构化。对于非结构化文本和半结构化的网页内容,系统应用自然语言处理将句子拆分为主语、谓语和宾语,然后使用面向业务的语义标准 SBVR 来识别诸如人物、事物、动作及其属性等概念。这些概念成为关联数据的构件。对于像 XML 和 JSON 这样的半结构化格式,轻量级解析器会在将其转换为文本之前,谨慎记录标签和属性的层级结构,以免丢失原始文档中的深层关系。对于结构化数据库,系统使用模型到模型的转换规则:它先将表格转换为 XML 表示,然后系统性地将该 XML 映射为 RDF 三元组,在此过程中保留键、行和列的含义。
对准确性、规模与可靠性的测试
研究人员在不同类型的数据上测试了他们的框架:样本文本段落、通过 URL 访问的网页和关系型数据库。他们衡量系统正确捕获的相关概念和关系的比例(召回率),以及系统提取结果中有多少是真正正确的(精确率)。在各项实验中,精确率通常在约 90% 到 97% 之间,召回率约为 82% 到 94%,表明该管道在捕获大部分重要信息的同时犯错较少。他们还检查了对生成的关联数据执行查询时的答案与原始数据库间的一致性,发现匹配率约为 90–97%。针对增长数据集(最多 160,000 条记录)的性能测试显示,处理时间大致随数据量增长而增加,内存使用保持稳定,这表明该方法可扩展到更大的真实世界数据集合。
对日常数据使用的意义
在实践层面,这项工作提供了一种方法,将表格、网页和文档的混杂集合转为单一、互联的知识层。与仅处理整齐数据库表的现有工具相比,这一框架在同一管道中支持三种主要数据类型,同时更好地保留结构与含义。仍存在空白——如图像或视频等多媒体尚未包含在内,且在简化半结构化数据时有时会丢失一些精细结构细节——但作者概述了未来版本可以如何解决这些限制。对非专业读者而言,结论很明确:通过将多样的数字内容转换为共享且可链接的格式,这种方法使得整合信息、在系统间迁移数据并挖掘模式变得更容易,推动我们更接近一个更智能、可搜索的数据网络。
引用: Sattar, H., Al-Khasawneh, M.A., Shafi, U.F. et al. A data migration and integration approach for big data management using linked data. Sci Rep 16, 12210 (2026). https://doi.org/10.1038/s41598-026-43298-x
关键词: 大数据集成, 关联数据, 数据迁移, 语义网, RDF 转换