Clear Sky Science · sv
En metod för datamigration och integration för storskalig datahantering med länkad data
Varför det spelar roll att tämja rörig data
Varje sökning, klick, sensormätning och köp online bidrar till ett osynligt hav av information. Det mesta av denna ”stordata” är rörig: e‑post och webbsidor, loggar och dokument, samt mer traditionella databaser. Företag och forskare vet att denna information döljer värdefulla insikter, men datan är spridd över olika format som inte naturligt samarbetar. Denna artikel presenterar ett sätt att omvandla den röriga blandningen till ett enda, välanslutet datanät som datorer kan förstå och analysera mer intelligent.
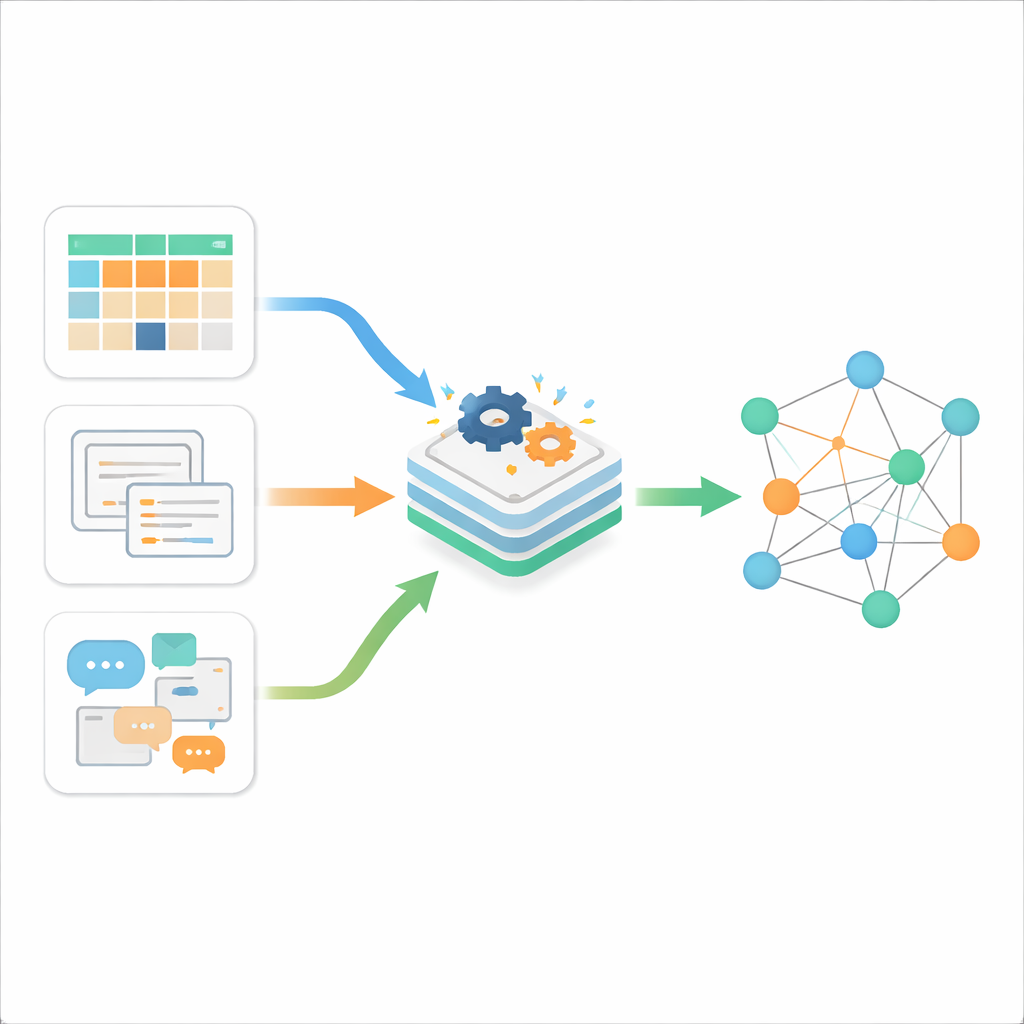
Tre typer av digitalt röra
Författarna börjar med att förklara att onlineinformation vanligtvis kommer i tre varianter. Strukturerad data är den prydliga sorten, lagrad i tabeller med rader och kolumner, såsom klassiska affärsdatabaser. Semi‑strukturerad data har viss ordning men ingen strikt tabellayout; exempel är webbsidor, XML‑ eller JSON‑filer, eller e‑post. Ostrukturerad data utgör den stora massan—friformstext, dokument och annat innehåll som inte följer en fast mall. Medan traditionella verktyg hanterar en av dessa typer hyfsat väl, är dagens verklighet en ständig ström av alla tre, producerade i hög hastighet av webben, smartphones och sakernas internet. Kärnproblemet är inte bara att lagra dem, utan att få dem att kommunicera med varandra på ett meningsfullt sätt.
Från datapölar till ett sammankopplat nät
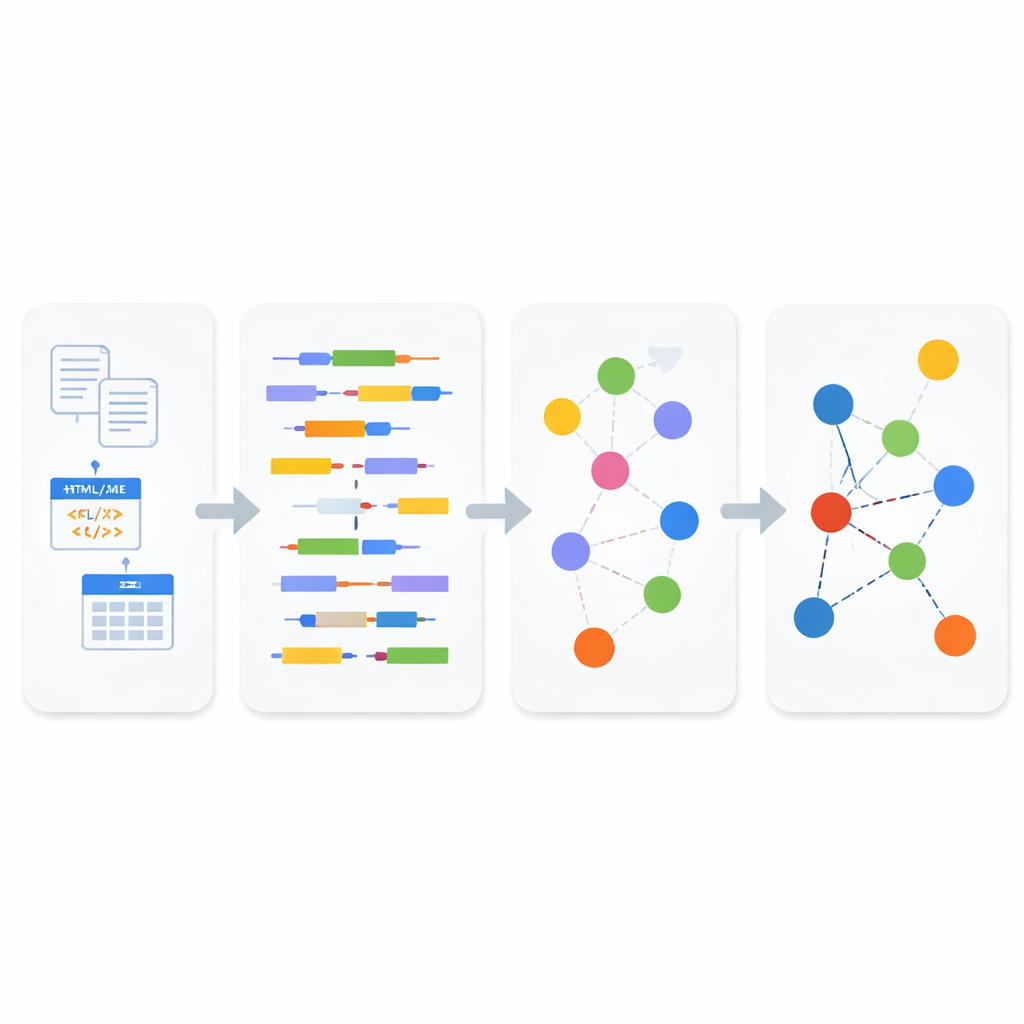
För att överbrygga dessa öar bygger författarna vidare på idén om länkad data, ett sätt att beskriva information så att fakta kan kopplas mellan källor, ungefär som en utökad, maskinläsbar version av Wikipedias länkade nätverk. Länkad data bygger på en standard som heter RDF, där kunskap bryts ner i enkla ”tripplar” som anger hur en sak är relaterad till en annan. Artikeln föreslår ett enhetligt ramverk som automatiskt konverterar strukturerade tabeller, semi‑strukturerade filer och ren text till detta länkade format. Istället för att bygga separata konverteringsverktyg för varje källa kör ramverket allting genom en tvådelad pipeline: en analysmodul som avgör vilken typ av data det handlar om och en syntesmodul som omvandlar den förståelsen till sammanlänkade RDF‑uttalanden.
Hur den nya pipelinen fungerar
I analysmodulen klassificeras inkommande data först som strukturerad, semi‑strukturerad eller ostrukturerad. För ostrukturerad text och semi‑strukturerat webbinnehåll tillämpar systemet naturlig språkbehandling för att bryta ner meningar i subjekt, verb och objekt, och använder sedan en affärsinriktad semantisk standard kallad SBVR för att känna igen begrepp som personer, ting, handlingar och deras egenskaper. Dessa begrepp blir byggstenarna i länkad data. För semi‑strukturerade format som XML och JSON använder en lättviktsparser för att noggrant registrera hierarkin av taggar och attribut innan de omvandlas till text, så att djupare relationer i originaldokumentet inte går förlorade. För strukturerade databaser använder systemet modell‑till‑modell‑transformationsregler: det konverterar först tabeller till en XML‑representation och kartlägger sedan systematiskt den XML:n till RDF‑tripplar, och bevarar nycklar, rader och kolumnbetydelser längs vägen.
Test av noggrannhet, skala och tillförlitlighet
Forskarna utsatte sitt ramverk för test med olika typer av data: exempelstycken med text, webbsidor åtkomna via URL:er och en relationsdatabas. De mätte hur många av de relevanta begreppen och relationerna systemet korrekt fångade (återkallning) och hur många av extraktionerna som faktiskt var riktiga (precision). I experimenten låg precisionen vanligtvis mellan cirka 90 % och 97 %, och återkallningen mellan ungefär 82 % och 94 %, vilket visar att pipelinen fångar det mesta av den viktiga informationen samtidigt som den gör relativt få misstag. De kontrollerade också hur väl frågor mot den resulterande länkade datan stämde överens med svaren från de ursprungliga databaserna och fann överensstämmelsegrader runt 90–97 %. Prestandatester med ökande datamängder, upp till 160 000 registreringar, visade att bearbetningstiden ökade ungefär i takt med datastorleken och att minnesanvändningen förblev stabil, vilket tyder på att metoden skalar till större verkliga samlingar.
Vad detta betyder för vardaglig dataanvändning
I praktiska termer erbjuder arbetet ett sätt att omvandla en kaotisk blandning av tabeller, webbsidor och dokument till ett enhetligt, sammankopplat kunskapslager. Jämfört med befintliga verktyg som endast hanterar prydliga databas-tabeller stöder detta ramverk alla tre stora datatyper i en pipeline, samtidigt som struktur och betydelse bevaras bättre. Det finns fortfarande luckor—multimedia som bilder eller video ingår ännu inte, och viss fin strukturell detalj kan gå förlorad när semi‑strukturerad data förenklas—men författarna skisserar hur framtida versioner kan adressera dessa begränsningar. För en lekmannaläsare är slutsatsen tydlig: genom att översätta olika digitalt innehåll till ett gemensamt, länkbart format blir det enklare att integrera information, flytta den mellan system och utvinna mönster, vilket för oss närmare ett mer intelligent, sökbart datanät.
Citering: Sattar, H., Al-Khasawneh, M.A., Shafi, U.F. et al. A data migration and integration approach for big data management using linked data. Sci Rep 16, 12210 (2026). https://doi.org/10.1038/s41598-026-43298-x
Nyckelord: integration av stordata, länkad data, datamigrering, semantiska webben, RDF-konvertering