Clear Sky Science · fr
Une approche de migration et d’intégration des données pour la gestion du big data utilisant les linked data
Pourquoi il est important de dompter les données désordonnées
Chaque recherche, clic, relevé de capteur et achat en ligne alimente un océan invisible d’informations. La plupart de ces « big data » sont désordonnées : e‑mails et pages web, journaux et documents, sans oublier les bases de données plus traditionnelles. Entreprises et chercheurs savent que ces informations recèlent des insights précieux, mais les données sont dispersées dans des formats différents qui ne s’articulent pas naturellement. Cet article propose une méthode pour transformer ce mélange désordonné en un web unique et bien connecté de données que les ordinateurs peuvent comprendre et analyser de façon plus intelligente.
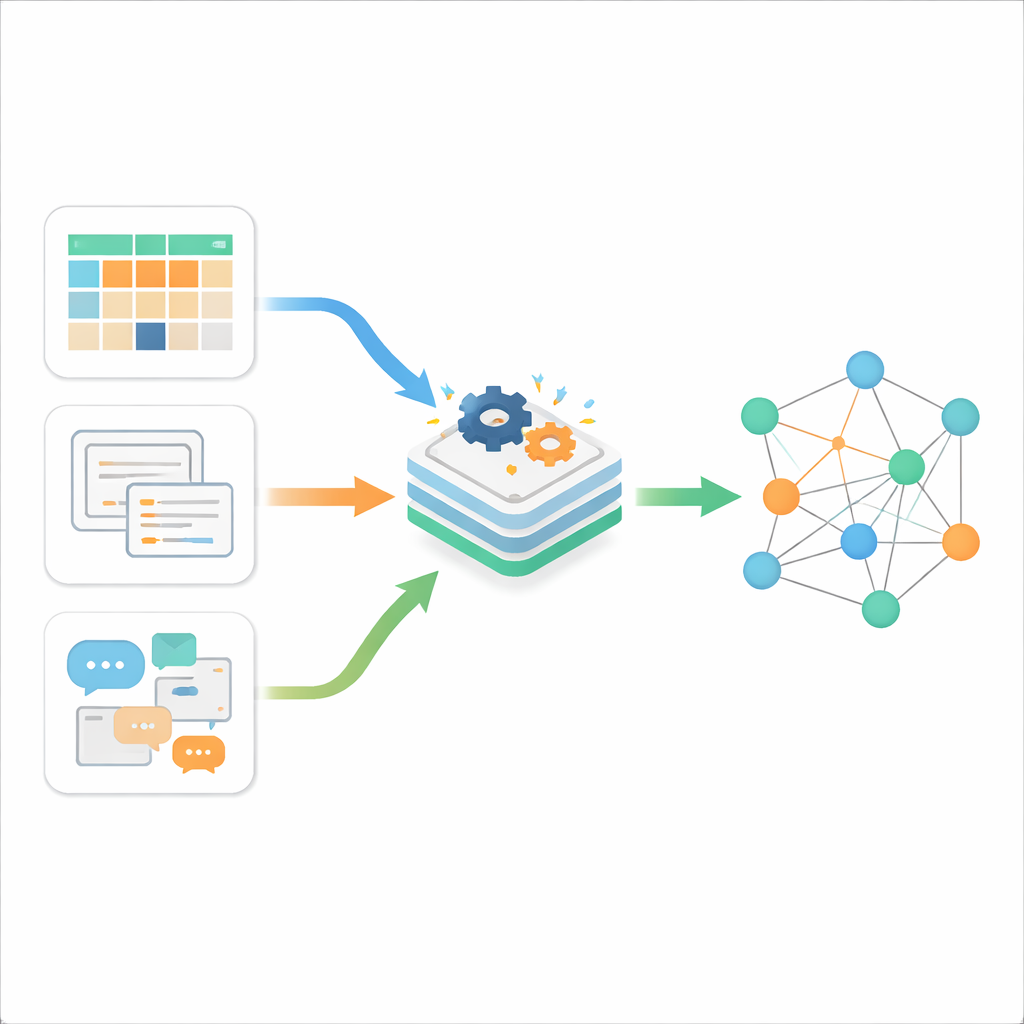
Trois types de désordre numérique
Les auteurs commencent par expliquer que l’information en ligne se présente généralement sous trois formes. Les données structurées sont propres et ordonnées, stockées dans des tableaux avec lignes et colonnes, comme les bases de données classiques. Les données semi‑structurées possèdent une certaine organisation sans adopter une mise en table rigide ; on pense par exemple aux pages web, fichiers XML, JSON ou aux e‑mails. Les données non structurées constituent la grande majorité : textes libres, documents et autres contenus qui ne suivent pas de modèle fixe. Alors que les outils traditionnels traitent bien l’un de ces types, la réalité actuelle est un flux continu des trois, produit à grande vitesse par le web, les smartphones et l’Internet des objets. Le défi central n’est pas seulement de les stocker, mais de leur permettre de communiquer entre elles de manière significative.
Des îles de données à un web connecté
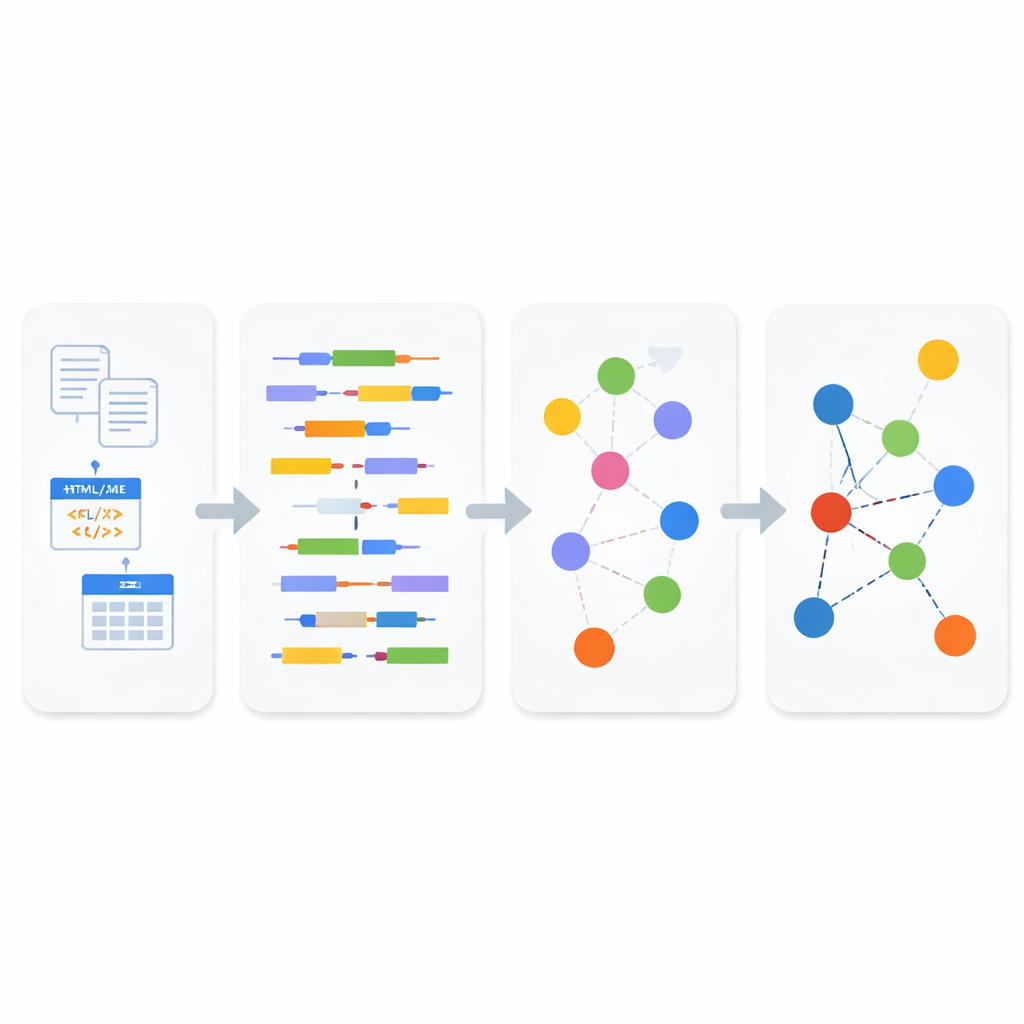
Pour relier ces îles, les auteurs s’appuient sur l’idée des Linked Data, une façon de décrire l’information afin que des faits puissent être connectés entre sources, un peu comme une version étendue et lisible par machine du réseau de liens de Wikipedia. Les Linked Data reposent sur une norme appelée RDF, où le savoir est fragmenté en « triplets » simples qui expriment comment une chose est liée à une autre. L’article propose un cadre unifié qui convertit automatiquement tableaux structurés, fichiers semi‑structurés et texte brut dans ce format lié. Plutôt que de créer des outils de conversion distincts pour chaque source, le cadre fait passer tout par une chaîne en deux parties : un module d’analyse qui identifie le type de données traité et un module de synthèse qui transforme cette compréhension en assertions RDF interconnectées.
Comment fonctionne la nouvelle chaîne
Dans le module d’analyse, les données entrantes sont d’abord classées comme structurées, semi‑structurées ou non structurées. Pour le texte non structuré et le contenu web semi‑structuré, le système applique le traitement du langage naturel pour décomposer les phrases en sujets, verbes et objets, puis utilise une norme sémantique orientée métier appelée SBVR pour reconnaître des concepts tels que personnes, objets, actions et leurs propriétés. Ces concepts deviennent les blocs de construction des Linked Data. Pour les formats semi‑structurés comme XML et JSON, un parseur léger enregistre soigneusement la hiérarchie des balises et des attributs avant de les transformer en texte, de sorte que les relations profondes du document original ne se perdent pas. Pour les bases de données structurées, le système utilise des règles de transformation modèle‑à‑modèle : il convertit d’abord les tables en une représentation XML, puis cartographie systématiquement ce XML en triplets RDF, en préservant les clés, les lignes et le sens des colonnes.
Tester la précision, l’échelle et la fiabilité
Les chercheurs ont évalué leur cadre sur différents types de données : paragraphes d’exemple, pages web accessibles par URL et une base de données relationnelle. Ils ont mesuré la part des concepts et relations pertinents que le système capture correctement (rappel) et la proportion d’extractions réellement correctes (précision). Dans les expériences, la précision se situait généralement entre environ 90 % et 97 %, et le rappel entre environ 82 % et 94 %, indiquant que la chaîne capture la plupart des informations importantes tout en commettant relativement peu d’erreurs. Ils ont également vérifié dans quelle mesure les requêtes sur les Linked Data résultants correspondaient aux réponses issues des bases de données d’origine, en trouvant des taux d’accord autour de 90–97 %. Des tests de performance sur des jeux de données croissants, jusqu’à 160 000 enregistrements, ont montré que le temps de traitement augmentait à peu près en proportion de la taille des données et que l’usage mémoire restait stable, ce qui suggère que l’approche est extensible à de plus grandes collections réelles.
Ce que cela signifie pour l’usage quotidien des données
Concrètement, ce travail propose une manière de transformer un mélange chaotique de tableaux, pages web et documents en une couche de connaissance unique et connectée. Comparé aux outils existants qui ne gèrent que des tableaux de bases de données bien ordonnés, ce cadre prend en charge les trois principaux types de données dans une seule chaîne, tout en mieux préservant structure et sens. Des lacunes subsistent : les multimédias comme images ou vidéos ne sont pas encore inclus, et certains détails structurels fins peuvent se perdre lors de la simplification des données semi‑structurées — mais les auteurs décrivent comment les versions futures pourraient combler ces limites. Pour le lecteur non spécialiste, l’idée est simple : en traduisant des contenus numériques divers dans un format partagé et liant, cette approche facilite l’intégration des informations, leur transfert entre systèmes et leur exploitation pour déceler des motifs, nous rapprochant d’un web de données plus intelligent et interrogeable.
Citation: Sattar, H., Al-Khasawneh, M.A., Shafi, U.F. et al. A data migration and integration approach for big data management using linked data. Sci Rep 16, 12210 (2026). https://doi.org/10.1038/s41598-026-43298-x
Mots-clés: intégration du big data, linked data, migration de données, web sémantique, conversion RDF