Clear Sky Science · tr
Büyük veri yönetimi için bağlantılı veriler kullanarak veri göçü ve entegrasyon yaklaşımı
Karışık Verileri Dizginlemenin Neden Önemli Olduğu
Her arama, tıklama, sensör okuması ve çevrimiçi satın alma görünmez bir bilgi okyanusuna katkıda bulunur. Bu "büyük veri"nın çoğu dağınıktır: e-postalar ve web sayfaları, günlükler ve belgeler ve klasik veritabanları. Şirketler ve araştırmacılar bu bilgilerin değerli içgörüler barındırdığını bilir, ancak veriler farklı formatlarda dağılmıştır ve doğal olarak birlikte çalışmazlar. Bu makale, o karışık yığını bilgisayarların anlayabileceği ve daha akıllıca analiz edebileceği tek, iyi bağlantılı bir veri ağına dönüştürmenin bir yolunu sunar.
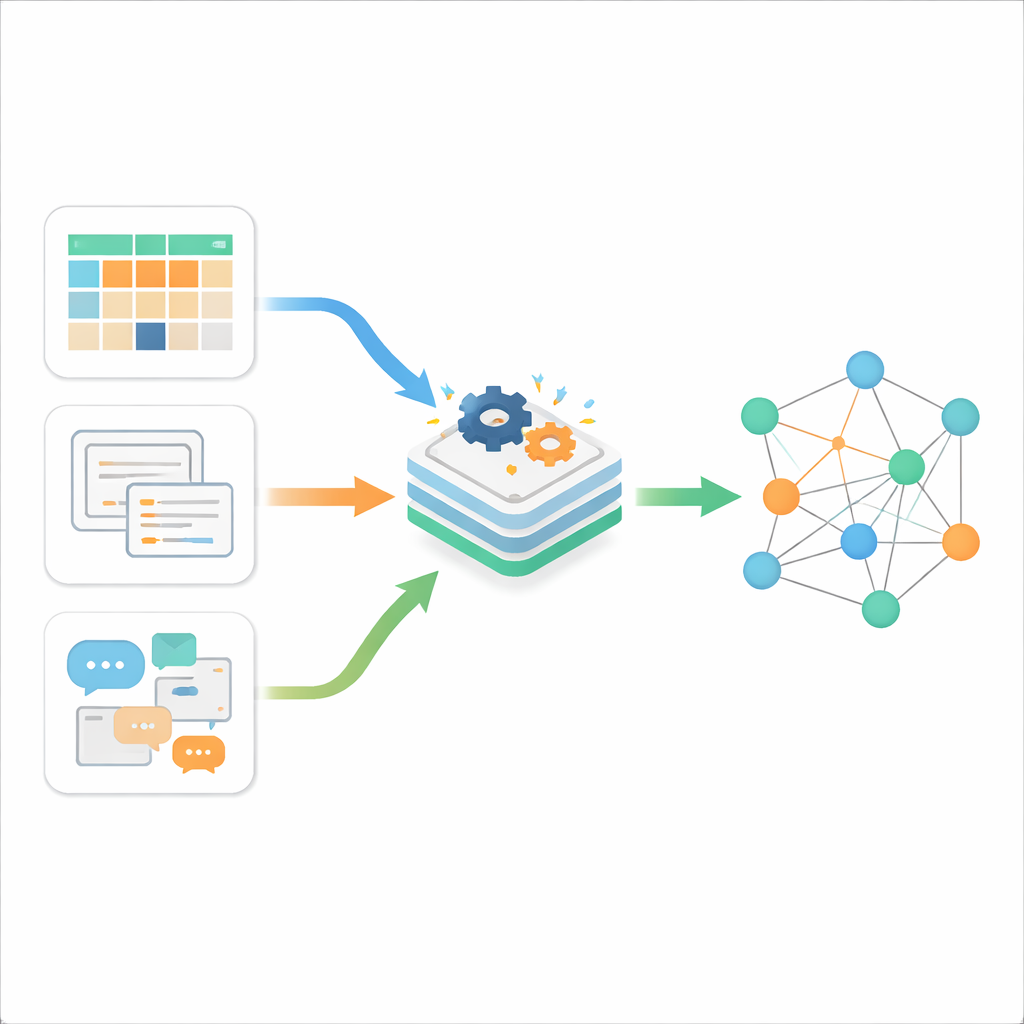
Üç Tür Dijital Dağınıklık
Yazarlar önce çevrimiçi bilgilerin tipik olarak üç formda geldiğini açıklar. Yapılandırılmış veri, satırlar ve sütunlar halinde düzenlenmiş, örneğin klasik işletme veritabanları gibi düzenli veridir. Yarı yapılandırılmış veri bir miktar organizasyona sahiptir ancak katı bir tablo düzeni yoktur; web sayfaları, XML, JSON dosyaları veya e-postalar buna örnektir. Yapılandırılmamış veri ise çoğunluğu oluşturur—serbest biçimli metin, belgeler ve sabit bir şablonu takip etmeyen diğer içerikler. Geleneksel araçlar bu türlerden birini nispeten iyi işlerken, günümüz gerçekliği web, akıllı telefonlar ve Nesnelerin İnterneti tarafından yüksek hızda üretilen bu üç türün kesintisiz akışıdır. Temel zorluk yalnızca bunları depalamak değil, aynı zamanda anlamlı şekilde birbirleriyle konuşmalarını sağlamaktır.
Veri Adacıklarından Bağlantılı Bir Ağa
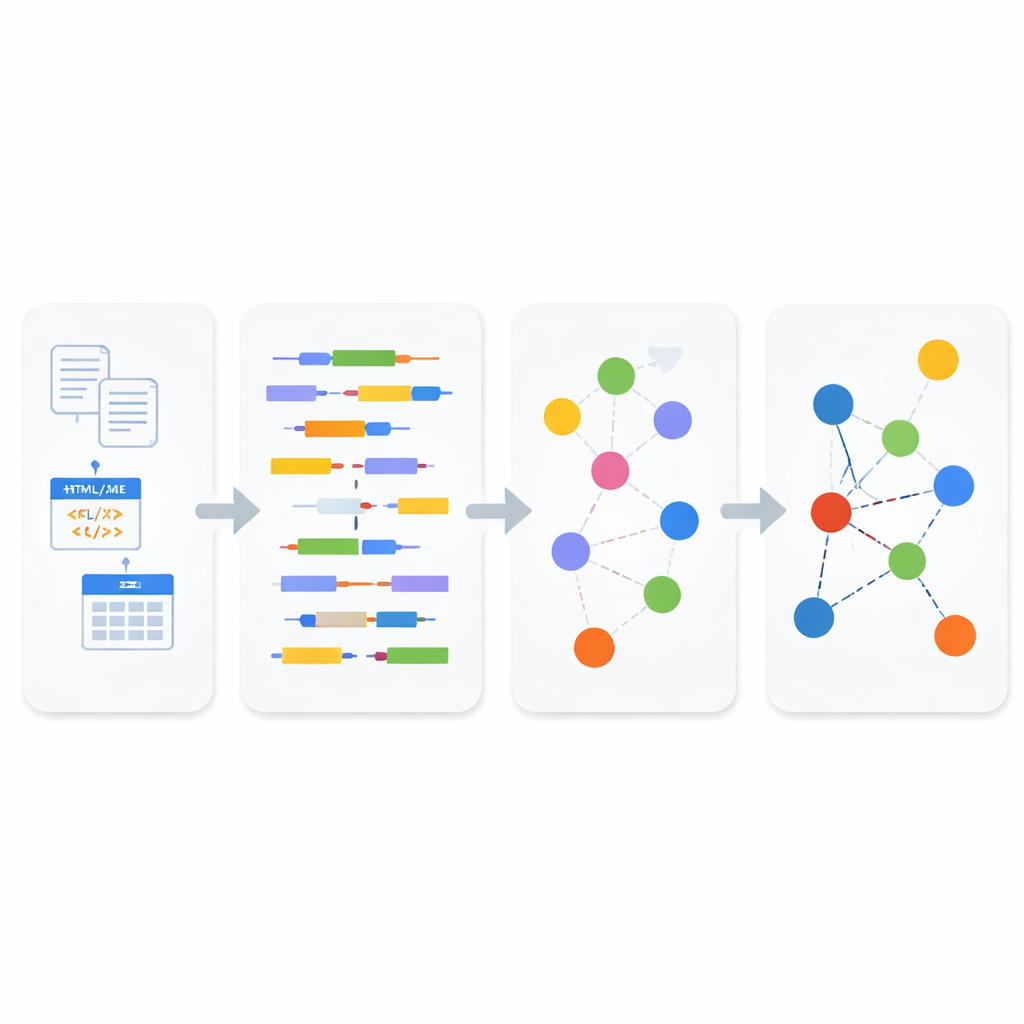
Bu adacıkları birbirine bağlamak için yazarlar, gerçeklerin kaynaklar arasında bağlanabilmesini sağlayan bir betimleme yöntemi olan Bağlantılı Veri (Linked Data) fikri üzerine inşa eder; bu, Wikipedia’nın bağlantı ağının makine tarafından okunabilir genişletilmiş bir versiyonuna benzer. Bağlantılı Veri, bilginin basit "üçlü"lere bölündüğü RDF adlı bir standarda dayanır; bu üçlüler bir nesnenin başka bir şeye nasıl bağlı olduğunu belirtir. Makale, yapılandırılmış tabloları, yarı yapılandırılmış dosyaları ve düz metni otomatik olarak bu bağlantılı formata dönüştüren birleşik bir çerçeve önerir. Her kaynak için ayrı dönüşüm araçları oluşturmaktansa, çerçeve her şeyi iki parçalı bir boru hattından geçirir: verinin türünü belirleyen bir analiz modülü ve o anlayışı birbirine bağlanmış RDF ifadelerine dönüştüren bir sentez modülü.
Yeni Boru Hattı Nasıl Çalışıyor
Analiz modülünün içinde gelen veriler önce yapılandırılmış, yarı yapılandırılmış veya yapılandırılmamış olarak sınıflandırılır. Yapılandırılmamış metin ve yarı yapılandırılmış web içeriği için sistem, cümleleri özneler, yüklemler ve nesneler halinde ayırmak için doğal dil işleme uygular; ardından insanlar, nesneler, eylemler ve bunların özellikleri gibi kavramları tanımak için SBVR adlı iş odaklı anlamsal standart kullanılır. Bu kavramlar Bağlantılı Veri’nin yapı taşları olur. XML ve JSON gibi yarı yapılandırılmış formatlar için hafif bir ayrıştırıcı etiketlerin ve özniteliklerin hiyerarşisini dikkatle kaydeder, sonra bunları metne dönüştürür; böylece orijinal belgede daha derin ilişkiler kaybolmaz. Yapılandırılmış veritabanları için sistem modelden modele dönüşüm kuralları kullanır: önce tabloları XML temsilinde dönüştürür, ardından bu XML’i RDF üçlülerine sistematik olarak haritalandırır; anahtarları, satırları ve sütun anlamlarını korur.
Doğruluk, Ölçek ve Güvenilirlik Testleri
Araştırmacılar çerçeveyi farklı veri türleri üzerinde test ettiler: örnek metin paragrafları, URL’lerle erişilen web sayfaları ve bir ilişkisel veritabanı. Sistemin doğru yakaladığı ilgili kavram ve ilişkilerin oranını (recall) ve çıkarımlarının gerçekte ne kadarının doğru olduğunu (precision) ölçtüler. Deneyler genelinde precision genellikle yaklaşık %90 ile %97, recall yaklaşık %82 ile %94 arasında değişti; bu, boru hattının önemli bilgilerin çoğunu yakaladığı ve nispeten az hata yaptığı anlamına geliyor. Ayrıca ortaya çıkan Bağlantılı Veri üzerinde çalıştırılan sorguların orijinal veritabanlarından alınacak cevaplarla ne kadar örtüştüğünü kontrol ettiler ve yaklaşık %90–97 oranında uyum buldular. Artan veri kümeleriyle yapılan performans testleri, 160.000 kayıt kadar büyüyen setlerde işlem süresinin verinin boyutuyla yaklaşık orantılı arttığını ve bellek kullanımının kararlı kaldığını gösterdi; bu da yaklaşımın daha büyük gerçek dünya koleksiyonlarına ölçeklenebileceğini düşündürüyor.
Günlük Veri Kullanımı İçin Anlamı
Pratikte bu çalışma, tabloların, web sayfalarının ve belgelerin kaotik karışımını tek, bağlantılı bir bilgi katmanına dönüştürmenin bir yolunu sunuyor. Sadece düzenli veritabanı tablolarını işleyen mevcut araçlarla karşılaştırıldığında bu çerçeve üç ana veri türünü tek bir boru hattında destekliyor ve yapı ve anlamı daha iyi koruyor. Hâlâ boşluklar var—görüntü veya video gibi multimedya henüz dahil değil ve yarı yapılandırılmış veriyi basitleştirirken bazı ince yapısal ayrıntılar kaybolabiliyor—ancak yazarlar gelecekteki sürümlerin bu sınırlamaları nasıl ele alabileceğini özetliyor. Bir genel okuyucu için çıkarım net: çeşitli dijital içeriği paylaşılan, bağlantılanabilir bir formata çevirerek, bu yaklaşım bilgiyi entegre etmeyi, sistemler arasında taşımayı ve kalıplar için taramayı kolaylaştırır; bizi daha akıllı, aranabilir bir veri ağına yaklaştırır.
Atıf: Sattar, H., Al-Khasawneh, M.A., Shafi, U.F. et al. A data migration and integration approach for big data management using linked data. Sci Rep 16, 12210 (2026). https://doi.org/10.1038/s41598-026-43298-x
Anahtar kelimeler: büyük veri entegrasyonu, bağlantılı veriler, veri göçü, anlamsal web, RDF dönüşümü