Clear Sky Science · de
Ein Ansatz zur Datenmigration und -integration für Big Data-Management unter Verwendung von Linked Data
Warum die Zähmung unordentlicher Daten wichtig ist
Jede Suche, jeder Klick, jede Sensorablesung und jeder Online-Kauf fügt einem unsichtbaren Ozean von Informationen hinzu. Ein Großteil dieser „Big Data“ ist unordentlich: E‑Mails und Webseiten, Protokolle und Dokumente sowie klassische Datenbanken. Unternehmen und Forscher wissen, dass in diesen Daten wertvolle Erkenntnisse stecken, aber die Informationen sind in unterschiedlichen Formaten verstreut, die nicht von Natur aus zusammenarbeiten. Dieses Paper stellt einen Weg vor, diese chaotische Mischung in ein einheitliches, gut vernetztes Datengewebe zu verwandeln, das Computer verstehen und intelligenter analysieren können.
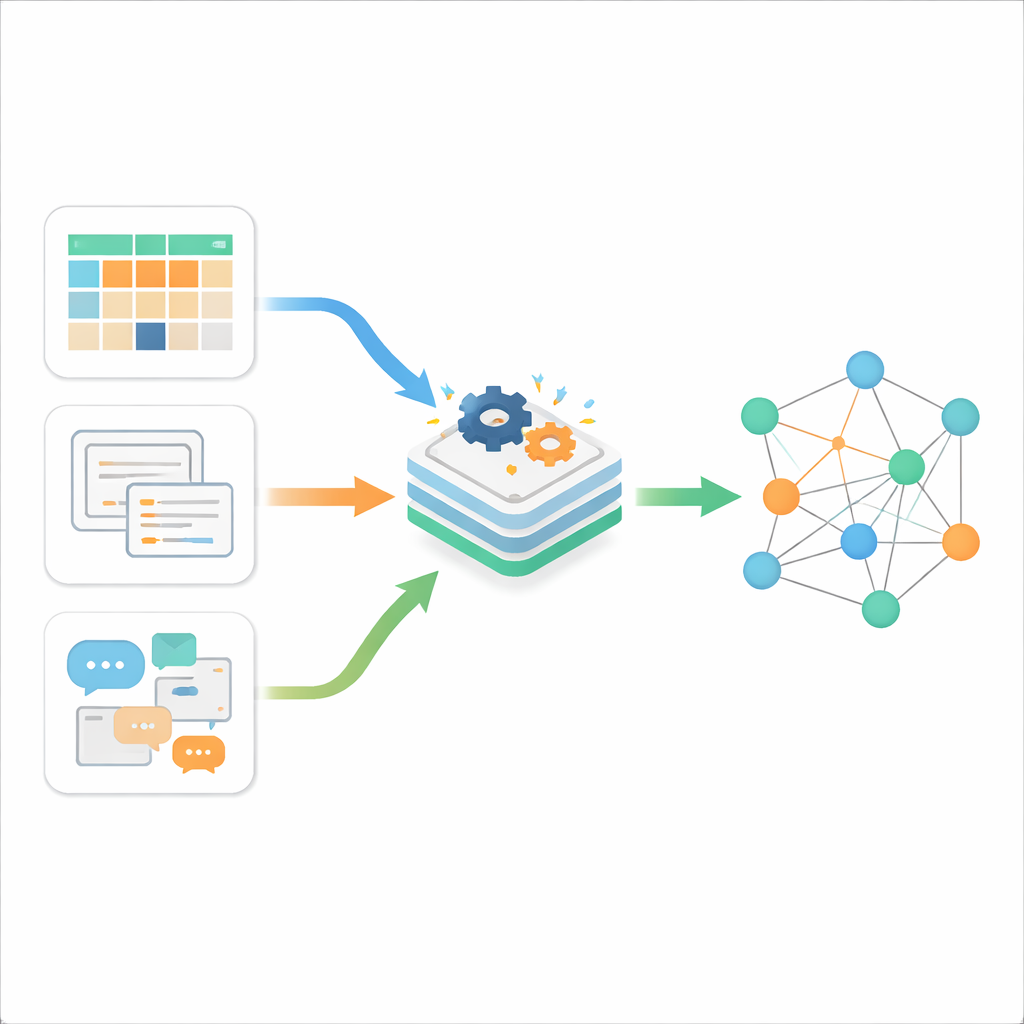
Drei Arten digitalen Durcheinanders
Die Autoren erklären zu Beginn, dass Online‑Informationen typischerweise in drei Formen auftreten. Strukturierte Daten sind die ordentliche Sorte, in Tabellen mit Zeilen und Spalten gespeichert, etwa klassische Geschäftsdatenbanken. Semi‑strukturierte Daten besitzen eine gewisse Ordnung, folgen aber keinem starren Tabellenlayout; Beispiele sind Webseiten, XML‑ oder JSON‑Dateien oder E‑Mails. Unstrukturierte Daten machen die überwiegende Mehrheit aus—Freitext, Dokumente und andere Inhalte ohne festes Template. Während traditionelle Werkzeuge jeweils eine dieser Typen recht gut verarbeiten, ist die heutige Realität ein kontinuierlicher Strom aller drei Typen, erzeugt mit hoher Geschwindigkeit durch das Web, Smartphones und das Internet der Dinge. Die zentrale Herausforderung besteht nicht nur im Speichern, sondern darin, sie sinnvoll miteinander kommunizieren zu lassen.
Von Dateninseln zu einem vernetzten Web
Um diese Inseln zu verbinden, bauen die Autoren auf der Idee der Linked Data auf, einer Methode, Informationen so zu beschreiben, dass Fakten über Quellen hinweg verbunden werden können—ähnlich einer erweiterten, maschinenlesbaren Version des Netzwerks von Links in Wikipedia. Linked Data beruht auf einem Standard namens RDF, bei dem Wissen in einfache „Tripel“ zerlegt wird, die aussagen, wie ein Ding mit einem anderen in Beziehung steht. Das Paper schlägt einen einheitlichen Rahmen vor, der strukturierte Tabellen, semi‑strukturierte Dateien und reinen Text automatisch in dieses verknüpfte Format überführt. Statt für jede Quelle separate Konverter zu bauen, führt das Framework alles durch eine zweiteilige Pipeline: ein Analysemodul, das ermittelt, um welche Art von Daten es sich handelt, und ein Synthesemodul, das dieses Verständnis in miteinander verbundene RDF‑Aussagen überführt.
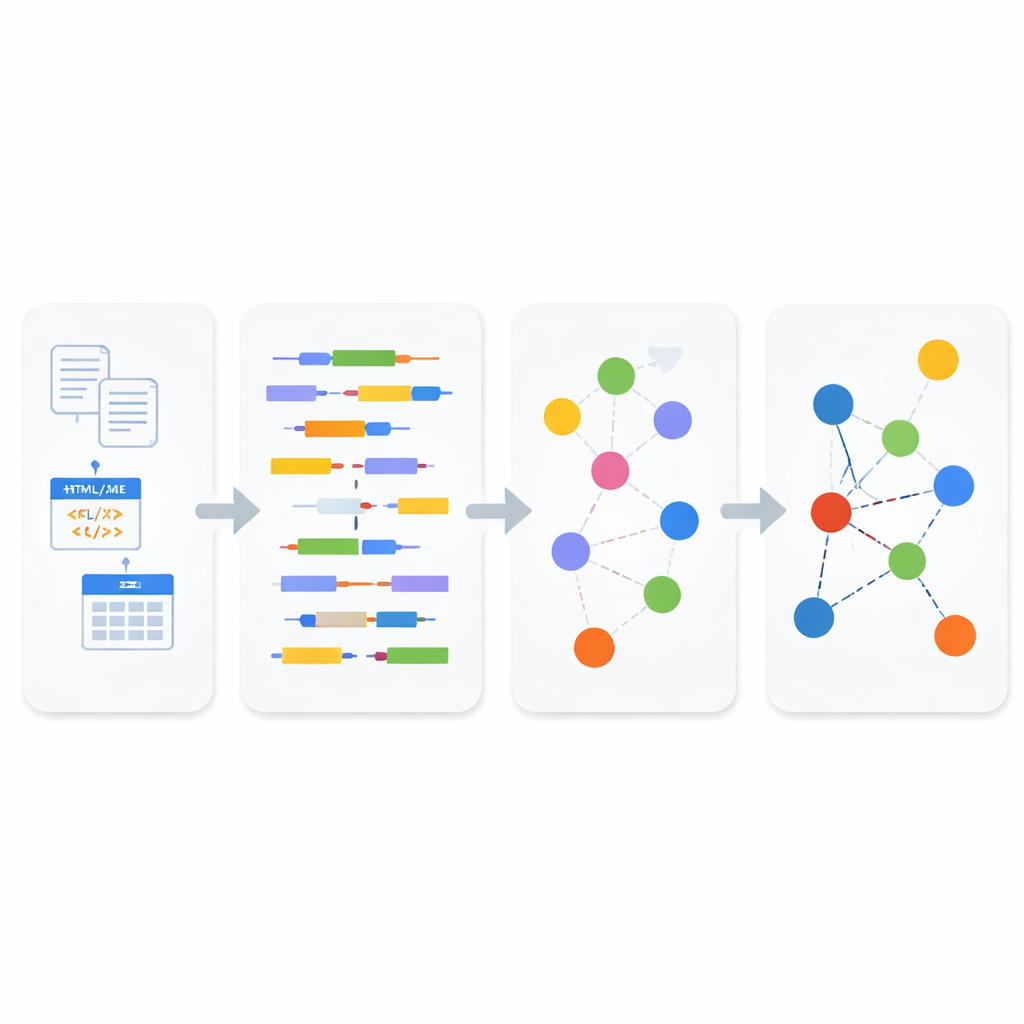
Wie die neue Pipeline funktioniert
Im Analysemodul wird eingehende Information zunächst als strukturiert, semi‑strukturiert oder unstrukturiert klassifiziert. Bei unstrukturiertem Text und semi‑strukturiertem Web‑Content wendet das System Natural Language Processing an, um Sätze in Subjekte, Prädikate und Objekte zu zerlegen, und nutzt dann einen geschäftsorientierten semantischen Standard namens SBVR, um Konzepte wie Personen, Dinge, Handlungen und deren Eigenschaften zu erkennen. Diese Konzepte werden zu den Bausteinen der Linked Data. Für semi‑strukturierte Formate wie XML und JSON erfasst ein leichtgewichtiger Parser sorgfältig die Hierarchie von Tags und Attributen, bevor er sie in Text umwandelt, sodass tiefere Beziehungen im Originaldokument nicht verloren gehen. Für strukturierte Datenbanken verwendet das System Modell‑zu‑Modell‑Transformationsregeln: Zuerst werden Tabellen in eine XML‑Darstellung überführt, dann wird dieses XML systematisch in RDF‑Tripel gemappt, wobei Schlüssel, Zeilen und Spaltenbedeutungen erhalten bleiben.
Test von Genauigkeit, Skalierbarkeit und Zuverlässigkeit
Die Forschenden prüften ihr Framework an verschiedenen Datenarten: Musterabsätzen, über URLs abgerufenen Webseiten und einer relationalen Datenbank. Sie maßen, wie viele der relevanten Konzepte und Beziehungen das System korrekt erfasste (Recall) und wie viele der extrahierten Angaben tatsächlich richtig waren (Precision). In den Experimenten lag die Präzision typischerweise zwischen etwa 90 % und 97 %, und der Recall zwischen ungefähr 82 % und 94 %, was darauf hindeutet, dass die Pipeline die wichtigsten Informationen erfasst und dabei relativ wenige Fehler macht. Sie überprüften außerdem, wie gut Abfragen auf den resultierenden Linked Data mit den Antworten aus den Originaldatenbanken übereinstimmen, und fanden Übereinstimmungsraten von rund 90–97 %. Leistungstests mit wachsenden Datensätzen bis zu 160.000 Datensätzen zeigten, dass die Verarbeitungszeit ungefähr mit der Datenmenge zunahm und der Speicherverbrauch stabil blieb, was darauf hindeutet, dass der Ansatz auf größere reale Sammlungen skalierbar ist.
Was das für den täglichen Umgang mit Daten bedeutet
Praktisch bietet die Arbeit einen Weg, eine chaotische Mischung aus Tabellen, Webseiten und Dokumenten in eine einzige, vernetzte Wissensschicht zu überführen. Im Vergleich zu vorhandenen Werkzeugen, die nur ordentliche Datenbanktabellen handhaben, unterstützt dieses Framework alle drei Hauptdatentypen in einer Pipeline und bewahrt Struktur und Bedeutung besser. Es gibt noch Lücken—Multimedia wie Bilder oder Videos sind noch nicht einbezogen, und einige feine Strukturdetails können beim Vereinfachen semi‑strukturierter Daten verloren gehen—aber die Autoren skizzieren, wie künftige Versionen diese Einschränkungen angehen könnten. Für eine interessierte Leserschaft ist die Quintessenz klar: Indem vielfältige digitale Inhalte in ein gemeinsames, verlinkbares Format übersetzt werden, erleichtert dieser Ansatz die Integration von Informationen, deren Übertragung zwischen Systemen und das Auffinden von Mustern und rückt uns näher an ein intelligenteres, durchsuchbares Daten‑Web.
Zitation: Sattar, H., Al-Khasawneh, M.A., Shafi, U.F. et al. A data migration and integration approach for big data management using linked data. Sci Rep 16, 12210 (2026). https://doi.org/10.1038/s41598-026-43298-x
Schlüsselwörter: Big-Data-Integration, Linked Data, Datenmigration, Semantic Web, RDF-Konvertierung