Clear Sky Science · ar
نهج ترحيل ودمج البيانات لإدارة البيانات الضخمة باستخدام البيانات المترابطة
لماذا ضبط الفوضى في البيانات مهم
كل بحث، ونقرة، وقراءة حساس، وشراء عبر الإنترنت يضيف إلى محيط غير مرئي من المعلومات. معظم هذه "البيانات الضخمة" فوضوية: رسائل البريد الإلكتروني وصفحات الويب وسجلات النظام والمستندات، بالإضافة إلى قواعد بيانات تقليدية. تعرف الشركات والباحثون أن هذه المعلومات تخفي رؤى قيّمة، لكن البيانات مبعثرة عبر صيغ مختلفة لا تتكامل بسهولة. تعرض هذه الورقة طريقة لتحويل هذا الخليط الفوضوي إلى شبكة موحدة ومتصلة من البيانات يمكن لأجهزة الكمبيوتر فهمها وتحليلها بذكاء أكبر.
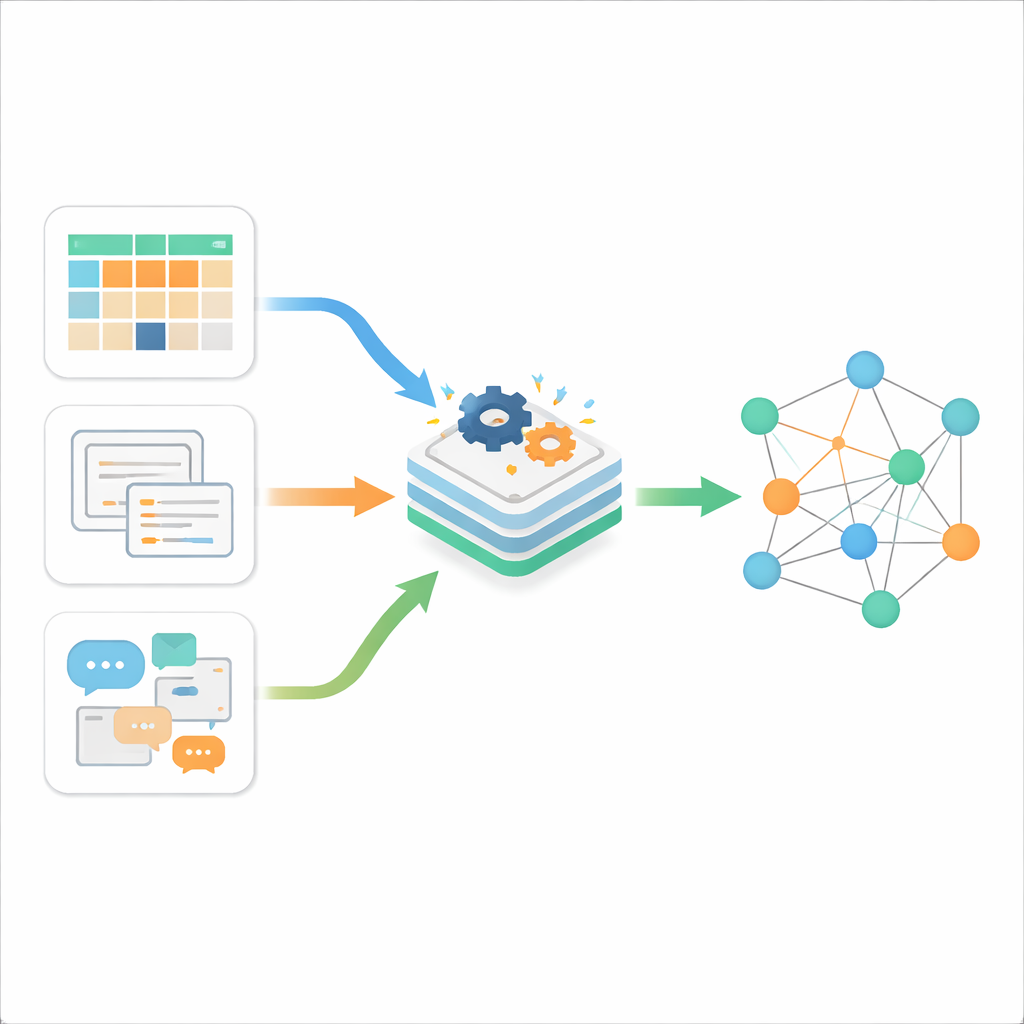
ثلاثة أنواع من الفوضى الرقمية
يبدأ المؤلفون بتوضيح أن المعلومات على الإنترنت تأتي عادة في ثلاثة أشكال. البيانات المهيكلة هي النوع المنظم والمرتب، المخزن في جداول ذات صفوف وأعمدة، مثل قواعد بيانات الأعمال التقليدية. البيانات شبه المهيكلة لها بعض التنظيم لكن ليس تخطيط جدول صارم؛ أمثلة على ذلك صفحات الويب وملفات XML وJSON أو رسائل البريد الإلكتروني. البيانات غير المهيكلة هي الغالبية العظمى—نصوص حرة، ومستندات، ومحتويات لا تتبع قالبًا ثابتًا. بينما تتعامل الأدوات التقليدية مع أحد هذه الأنواع جيدًا، فإن الواقع الحالي هو تدفق مستمر من الأنواع الثلاثة مع إنتاجه بسرعة عالية عبر الويب والهواتف الذكية وإنترنت الأشياء. التحدي الأساسي ليس مجرد تخزينها، بل جعلها تتواصل مع بعضها البعض بطريقة ذات مغزى.
من جزر البيانات إلى شبكة متصلة
لرابط هذه الجزر، يبني المؤلفون على فكرة البيانات المترابطة، وهي طريقة لوصف المعلومات بحيث يمكن ربط الحقائق عبر المصادر، شبيهة بشبكة روابط ويكيبيديا لكن قابلة للقراءة الآلية. تعتمد البيانات المترابطة على معيار يُسمى RDF، حيث تُقسم المعرفة إلى "ثلاثيات" بسيطة تفيد كيف يرتبط شيء بآخر. تقترح الورقة إطارًا موحدًا يحول تلقائيًا الجداول المهيكلة والملفات شبه المهيكلة والنصوص العادية إلى هذا الشكل المترابط. بدلًا من بناء أدوات تحويل منفصلة لكل مصدر، يجري كل شيء عبر خط أنابيب مؤلف من جزئين: وحدة تحليل تحدد نوع البيانات المعنية ووحدة تركيب تحول هذا الفهم إلى عبارات RDF مترابطة.
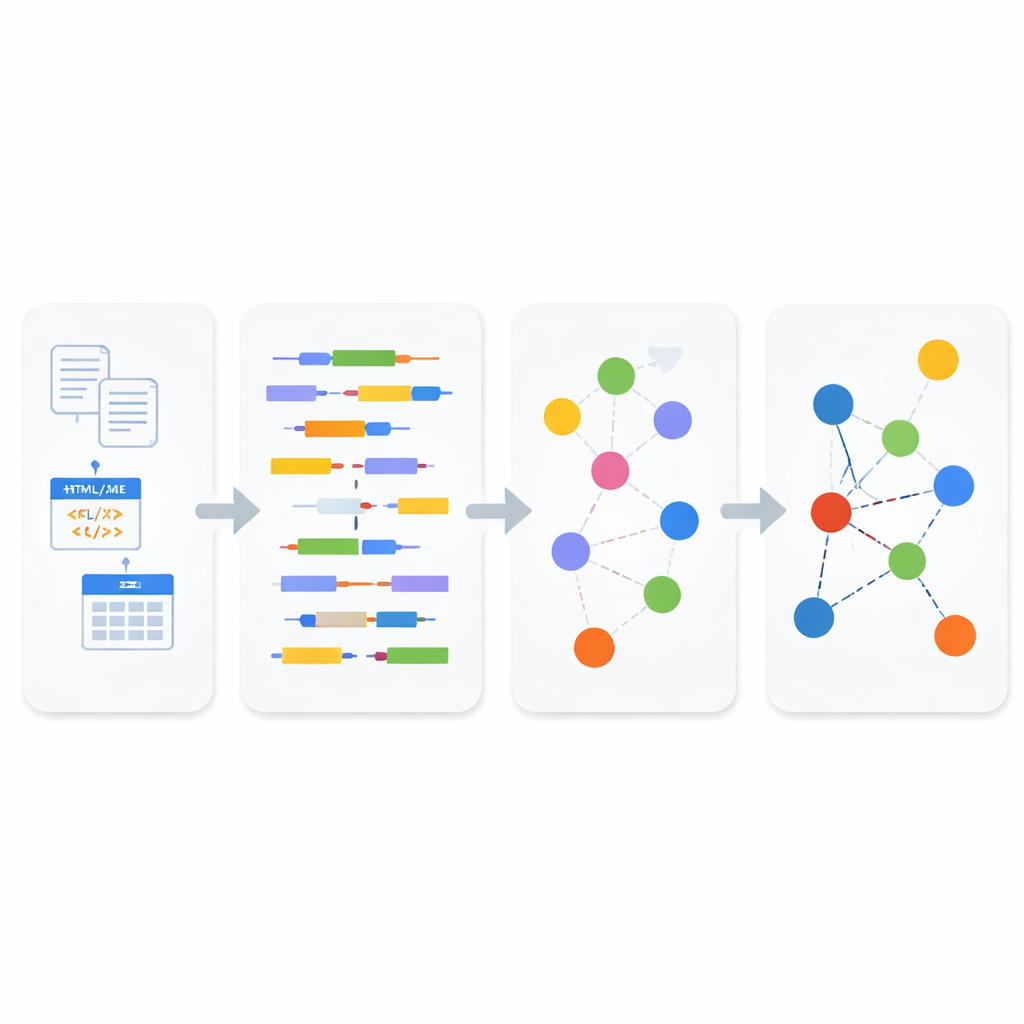
كيف يعمل خط الأنابيب الجديد
داخل وحدة التحليل، تُصنف البيانات الواردة أولًا على أنها مهيكلة أو شبه مهيكلة أو غير مهيكلة. للنصوص غير المهيكلة ومحتوى الويب شبه المهيكل، يطبق النظام معالجة لغة طبيعية لتفكيك الجمل إلى مواضيع وأفعال ومتممات، ثم يستخدم معيارًا دلاليًّا موجّهًا للأعمال يُدعى SBVR للتعرّف على مفاهيم مثل الأشخاص والأشياء والأفعال وخصائصها. تصبح هذه المفاهيم لبنات بناء البيانات المترابطة. بالنسبة للصيغ شبه المهيكلة مثل XML وJSON، يسجل محلل خفيف الوزن بعناية تدرّج الوسوم والسمات قبل تحويلها إلى نص، حتى لا تُفقد العلاقات العميقة في المستند الأصلي. بالنسبة لقواعد البيانات المهيكلة، يستخدم النظام قواعد تحويل من نموذج إلى نموذج: يحول الجداول أولًا إلى تمثيل XML، ثم يرسم هذا XML بشكل منهجي إلى ثلاثيات RDF، محافظًا على المفاتيح والصفوف ومعاني الأعمدة على طول المسار.
اختبار الدقة والحجم والموثوقية
اختبر الباحثون إطارهم على أنواع مختلفة من البيانات: فقرات نصية نموذجية، وصفحات ويب تم الوصول إليها عبر عناوين URL، وقاعدة بيانات علائقية. قاسوا كم من المفاهيم والعلاقات ذات الصلة التقطها النظام بشكل صحيح (الاستدعاء) وكم من الاستخراجات كانت صحيحة فعلًا (الدقة). عبر التجارب، تراوحت الدقة عادة بين حوالي 90% و97%، والاستدعاء بين نحو 82% و94%، مشيرة إلى أن خط الأنابيب يلتقط معظم المعلومات المهمة مع ارتكاب أخطاء نسبية قليلة. كما فحصوا مدى تطابق الاستعلامات على البيانات المترابطة الناتجة مع الإجابات التي تحصل عليها من قواعد البيانات الأصلية، ووجدوا معدلات توافق تقارب 90–97%. أظهرت اختبارات الأداء مع مجموعات بيانات متزايدة، تصل إلى 160,000 سجل، أن زمن المعالجة زاد تقريبًا بما يتناسب مع حجم البيانات وبقي استخدام الذاكرة مستقرًا، مما يشير إلى أن النهج قابل للتوسع لمجموعات العالم الحقيقي الأكبر.
ماذا يعني هذا لاستخدام البيانات اليومي
من الناحية العملية، يقدم هذا العمل طريقة لتحويل مزيج فوضوي من الجداول وصفحات الويب والمستندات إلى طبقة معرفة واحدة ومتصلة. بالمقارنة مع الأدوات الحالية التي تتعامل فقط مع جداول قواعد البيانات المنظمة، يدعم هذا الإطار الأنواع الثلاثة الرئيسية من البيانات في خط أنابيب واحد، مع الحفاظ بشكل أفضل على البنية والمعنى. لا تزال هناك ثغرات—المحتوى متعدد الوسائط مثل الصور أو الفيديو غير مدرج بعد، وقد تُفقد بعض التفاصيل البنيوية الدقيقة عند تبسيط البيانات شبه المهيكلة—لكن المؤلفين يوضحون كيف يمكن للإصدارات المستقبلية معالجة هذه القيود. للقارئ العام، الخلاصة واضحة: بترجمة محتويات رقمية متنوعة إلى صيغة مشتركة قابلة للربط، يسهل هذا النهج دمج المعلومات ونقلها بين الأنظمة واستخراج الأنماط منها، مما يقربنا من شبكة بيانات أكثر ذكاءً وقابلية للبحث.
الاستشهاد: Sattar, H., Al-Khasawneh, M.A., Shafi, U.F. et al. A data migration and integration approach for big data management using linked data. Sci Rep 16, 12210 (2026). https://doi.org/10.1038/s41598-026-43298-x
الكلمات المفتاحية: تكامل البيانات الضخمة, البيانات المترابطة, ترحيل البيانات, الويب الدلالي, تحويل RDF