Clear Sky Science · it
Un approccio di migrazione e integrazione dei dati per la gestione del big data usando linked data
Perché domare i dati disordinati è importante
Ogni ricerca, clic, lettura di sensori e acquisto online si sommano a un oceano invisibile di informazioni. La maggior parte di questi “big data” è disordinata: e‑mail e pagine web, log e documenti, oltre ai database tradizionali. Aziende e ricercatori sanno che in queste informazioni si nascondono intuizioni preziose, ma i dati sono sparsi in formati diversi che non interagiscono naturalmente fra loro. Questo articolo presenta un modo per trasformare quel mix confuso in un unico, ben collegato web di dati che i computer possono comprendere e analizzare in modo più intelligente.
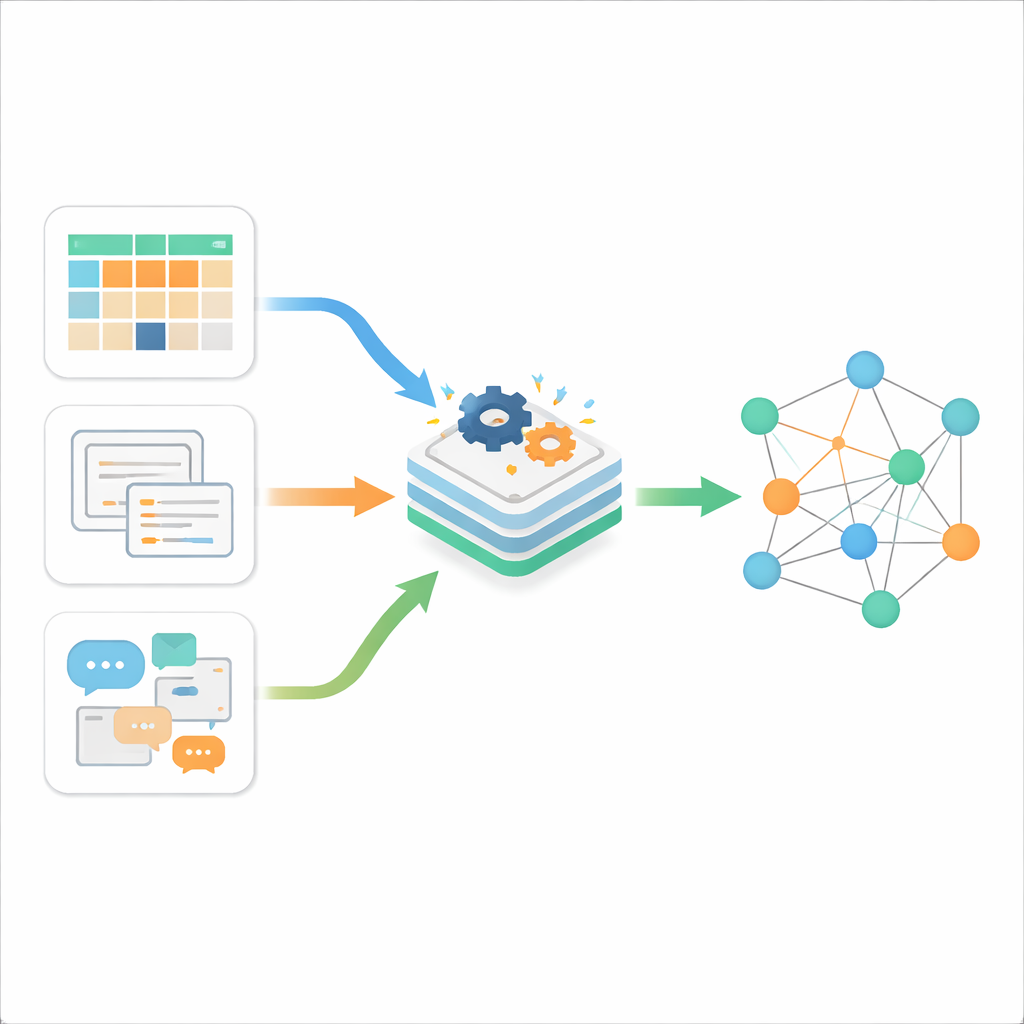
Tre tipi di ingombro digitale
Gli autori iniziano spiegando che le informazioni online tipicamente si presentano in tre varianti. I dati strutturati sono quelli ordinati, conservati in tabelle con righe e colonne, come i classici database aziendali. I dati semi‑strutturati hanno una certa organizzazione ma non una rigida disposizione tabellare; esempi sono pagine web, file XML o JSON, oppure e‑mail. I dati non strutturati sono la larga maggioranza: testo libero, documenti e altri contenuti che non seguono un template fisso. Mentre gli strumenti tradizionali trattano abbastanza bene uno di questi tipi, la realtà odierna è un flusso costante di tutti e tre, prodotto ad alta velocità dal web, dagli smartphone e dall’Internet of Things. La sfida principale non è solo immagazzinarli, ma farli comunicare tra loro in modo significativo.
Dalle isole di dati a un web connesso
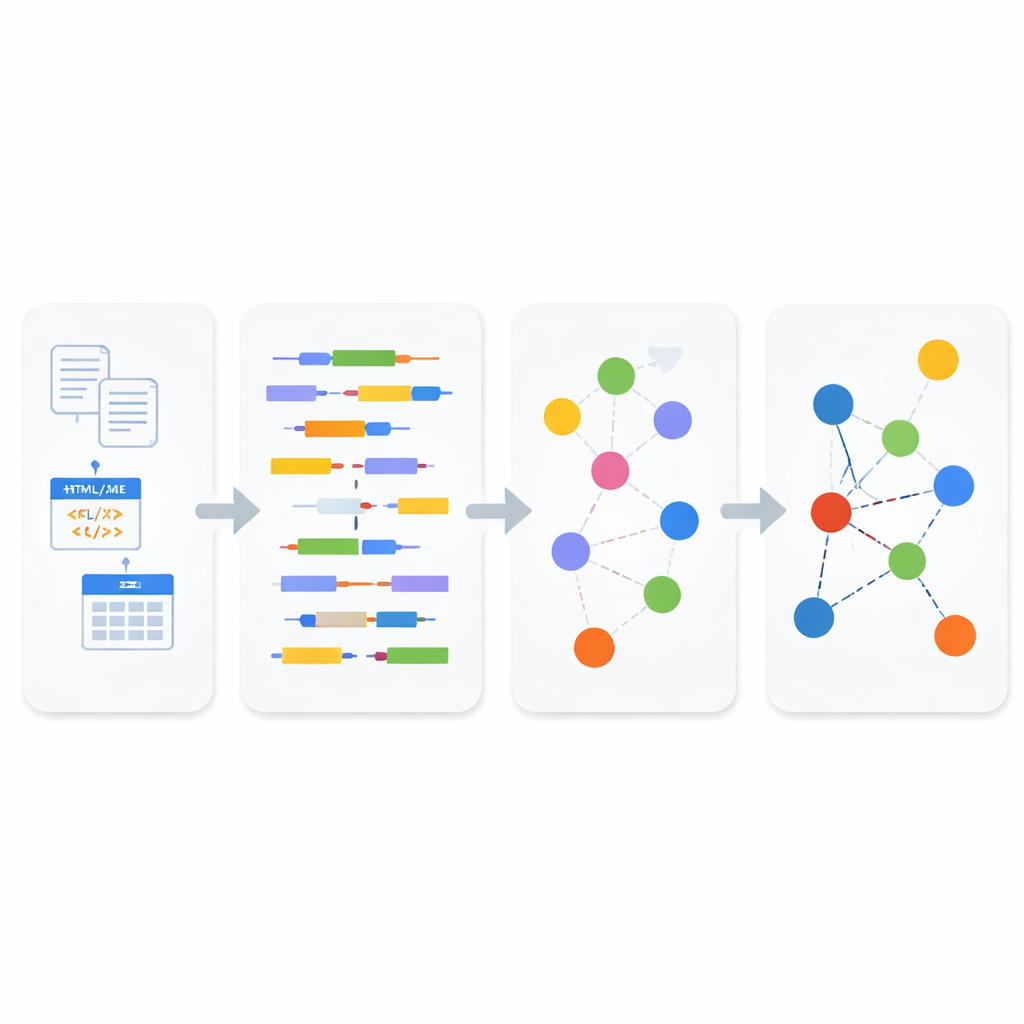
Per collegare queste isole, gli autori si basano sull’idea dei Linked Data, un modo di descrivere le informazioni affinché i fatti possano essere collegati fra le fonti, un po’ come una versione estesa e leggibile dalle macchine della rete di link di Wikipedia. I Linked Data si fondano su uno standard chiamato RDF, dove la conoscenza è scomposta in semplici “triple” che dichiarano come una cosa è relazionata a un’altra. L’articolo propone un quadro unificato che converte automaticamente tabelle strutturate, file semi‑strutturati e testo in chiaro in questo formato collegato. Invece di costruire strumenti di conversione separati per ogni sorgente, il framework fa passare tutto attraverso una pipeline in due parti: un modulo di analisi che determina che tipo di dati sta trattando e un modulo di sintesi che trasforma quella comprensione in enunciati RDF interconnessi.
Come funziona la nuova pipeline
All’interno del modulo di analisi, i dati in ingresso sono prima classificati come strutturati, semi‑strutturati o non strutturati. Per il testo non strutturato e i contenuti web semi‑strutturati, il sistema applica tecniche di elaborazione del linguaggio naturale per scomporre le frasi in soggetti, verbi e oggetti, quindi usa uno standard semantico orientato al business chiamato SBVR per riconoscere concetti come persone, cose, azioni e le loro proprietà. Questi concetti diventano i mattoni dei Linked Data. Per formati semi‑strutturati come XML e JSON, un parser leggero registra con cura la gerarchia di tag e attributi prima di trasformarli in testo, in modo che le relazioni più profonde nel documento originale non vadano perdute. Per i database strutturati, il sistema usa regole di trasformazione modello‑a‑modello: converte prima le tabelle in una rappresentazione XML, poi mappa sistematicamente quell’XML in triple RDF, preservando chiavi, righe e significato delle colonne lungo il processo.
Validazione di accuratezza, scala e affidabilità
I ricercatori hanno messo alla prova il loro framework su diversi tipi di dati: paragrafi di testo campione, pagine web accessibili via URL e un database relazionale. Hanno misurato quante delle idee e relazioni rilevanti il sistema catturava correttamente (recall) e quante delle estrazioni erano effettivamente corrette (precision). Negli esperimenti, la precision tipica è oscillata circa tra il 90% e il 97%, e il recall fra circa l’82% e il 94%, indicando che la pipeline cattura la maggior parte delle informazioni importanti pur commettendo relativamente pochi errori. Hanno anche verificato quanto le interrogazioni sui Linked Data risultanti coincidenti con le risposte ottenute dai database originali, trovando tassi di accordo intorno al 90–97%. I test di performance con dataset in crescita, fino a 160.000 record, hanno mostrato che il tempo di elaborazione aumentava grosso modo in linea con la dimensione dei dati e l’uso di memoria rimaneva stabile, suggerendo che l’approccio è scalabile verso raccolte reali più grandi.
Cosa significa per l’uso quotidiano dei dati
In termini pratici, il lavoro offre un modo per trasformare un miscuglio caotico di tabelle, pagine web e documenti in un unico strato di conoscenza connesso. Rispetto agli strumenti esistenti che gestiscono solo tabelle ordinate di database, questo framework supporta tutti e tre i principali tipi di dati in un’unica pipeline, preservando meglio struttura e significato. Restano lacune: i contenuti multimediali come immagini o video non sono ancora inclusi, e alcuni dettagli strutturali fini possono andare persi quando si semplificano i dati semi‑strutturati — ma gli autori descrivono come versioni future potrebbero affrontare questi limiti. Per un lettore non specialista, la conclusione è chiara: traducendo contenuti digitali diversi in un formato condiviso e collegabile, questo approccio facilita l’integrazione delle informazioni, il loro trasferimento tra sistemi e l’estrazione di schemi, avvicinandoci a un web dei dati più intelligente e ricercabile.
Citazione: Sattar, H., Al-Khasawneh, M.A., Shafi, U.F. et al. A data migration and integration approach for big data management using linked data. Sci Rep 16, 12210 (2026). https://doi.org/10.1038/s41598-026-43298-x
Parole chiave: integrazione dei big data, linked data, migrazione dei dati, web semantico, conversione in RDF