Clear Sky Science · es
Un enfoque de migración e integración de datos para la gestión de big data usando datos enlazados
Por qué importa domar los datos desordenados
Cada búsqueda, clic, lectura de sensor y compra en línea suma a un océano invisible de información. La mayor parte de estos “big data” es desordenada: correos y páginas web, registros y documentos, además de bases de datos más tradicionales. Empresas e investigadores saben que esta información oculta ideas valiosas, pero los datos están dispersos en distintos formatos que no funcionan de forma nativa entre sí. Este artículo presenta una forma de convertir esa mezcla caótica en una única red de datos bien conectada que los ordenadores puedan entender y analizar de manera más inteligente.
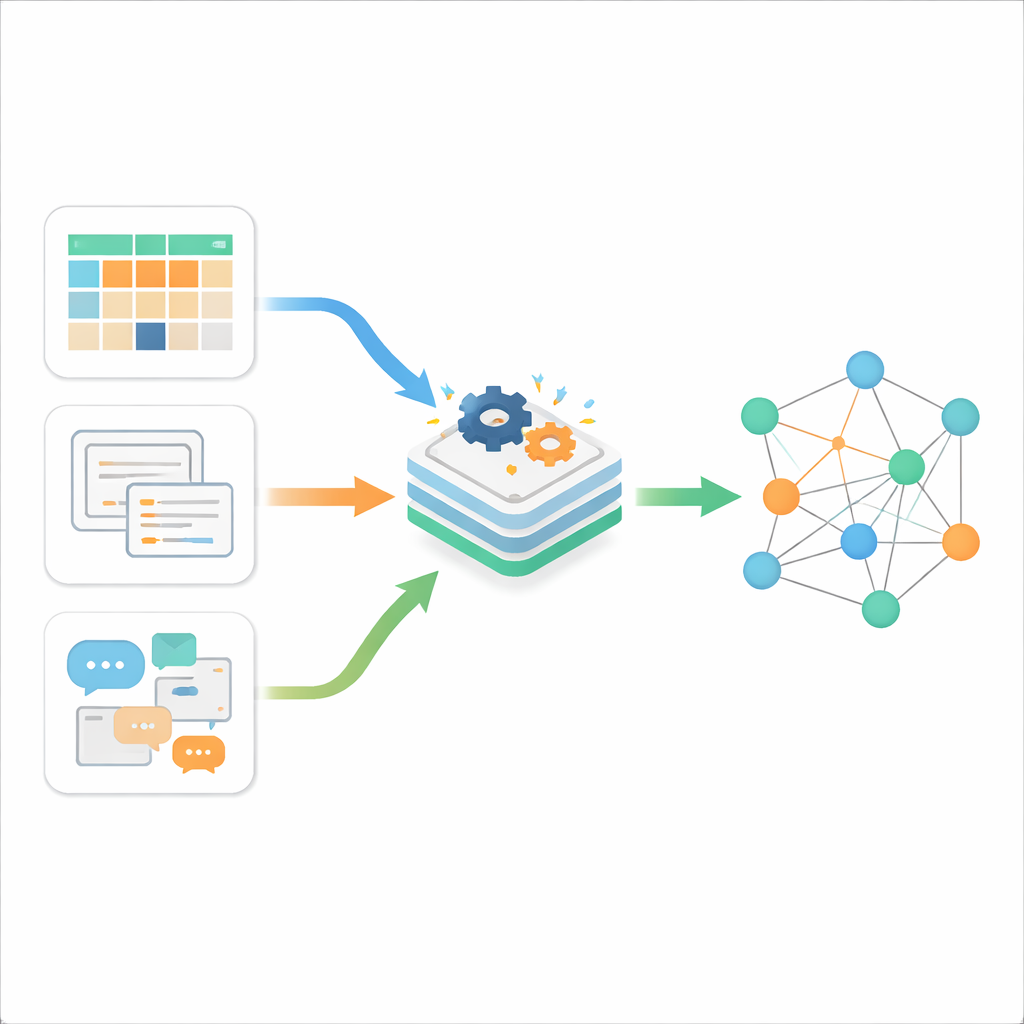
Tres tipos de desorden digital
Los autores comienzan explicando que la información en línea suele presentarse en tres variantes. Los datos estructurados son los ordenados y limpios, almacenados en tablas con filas y columnas, como las bases de datos empresariales clásicas. Los datos semiestructurados tienen cierta organización pero no un esquema tabular rígido; ejemplos son páginas web, archivos XML o JSON, o correos electrónicos. Los datos no estructurados son la gran mayoría: texto libre, documentos y otro contenido que no sigue una plantilla fija. Mientras que las herramientas tradicionales manejan razonablemente bien uno de estos tipos, la realidad actual es una corriente continua de los tres, producida a gran velocidad por la web, los teléfonos inteligentes y el Internet de las Cosas. El reto central no es solo almacenarlos, sino lograr que se comuniquen entre sí de manera significativa.
De islas de datos a una web conectada
Para unir esas islas, los autores se basan en la idea de Datos Enlazados (Linked Data), una manera de describir la información para que los hechos puedan conectarse entre fuentes, algo parecido a una versión ampliada y legible por máquina de la red de enlaces de Wikipedia. Los Datos Enlazados se apoyan en un estándar llamado RDF, donde el conocimiento se descompone en simples “tripletas” que indican cómo una cosa se relaciona con otra. El artículo propone un marco unificado que convierte automáticamente tablas estructuradas, archivos semiestructurados y texto plano a este formato enlazado. En vez de construir herramientas de conversión separadas para cada origen, el marco hace pasar todo por una canalización de dos partes: un módulo de análisis que determina qué tipo de dato se está manejando y un módulo de síntesis que transforma ese entendimiento en enunciados RDF interconectados.
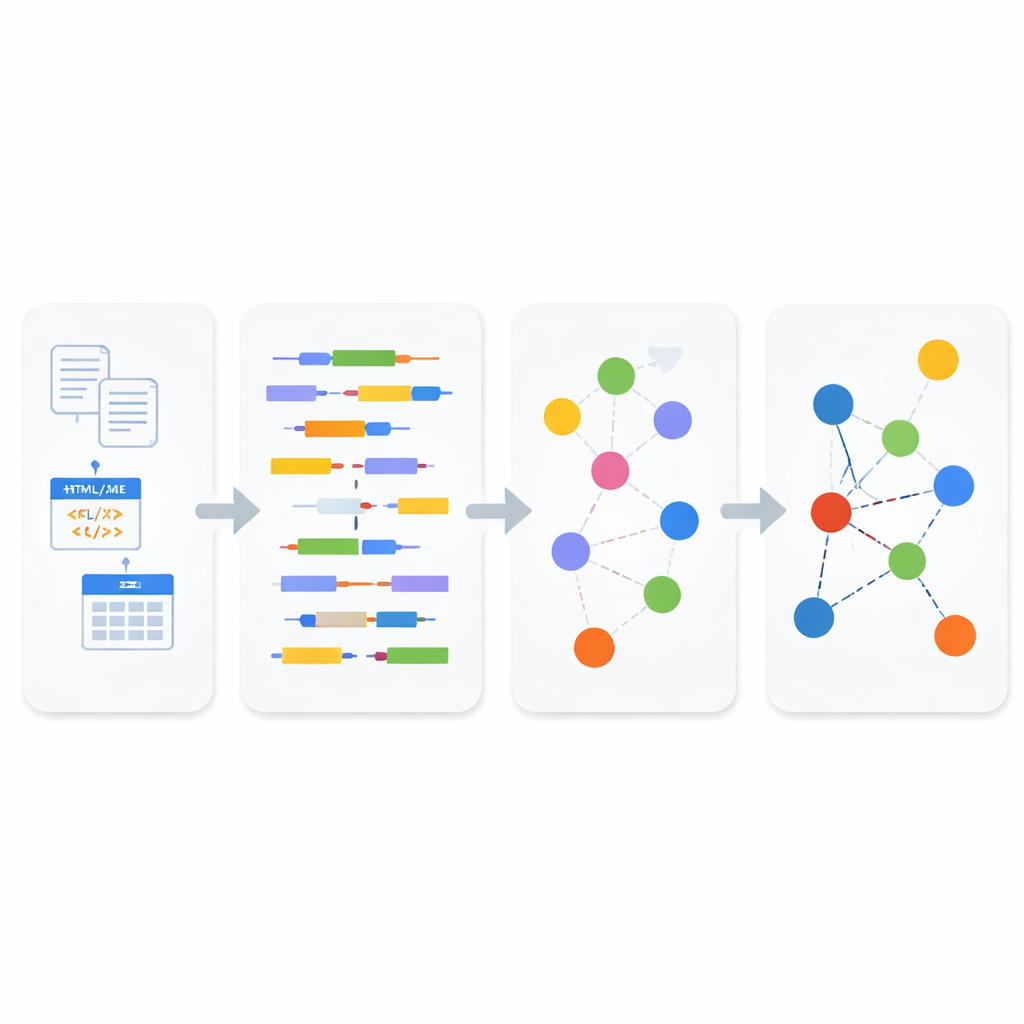
Cómo funciona la nueva canalización
Dentro del módulo de análisis, los datos entrantes se clasifican primero como estructurados, semiestructurados o no estructurados. Para texto no estructurado y contenido web semiestructurado, el sistema aplica procesamiento de lenguaje natural para descomponer las oraciones en sujetos, verbos y objetos, y luego usa un estándar semántico orientado a negocios llamado SBVR para reconocer conceptos como personas, cosas, acciones y sus propiedades. Esos conceptos se convierten en los bloques con los que se construyen los Datos Enlazados. Para formatos semiestructurados como XML y JSON, un analizador ligero registra cuidadosamente la jerarquía de etiquetas y atributos antes de convertirlos en texto, de modo que no se pierdan las relaciones profundas del documento original. Para bases de datos estructuradas, el sistema emplea reglas de transformación modelo-a-modelo: primero convierte las tablas en una representación XML y luego mapea sistemáticamente ese XML a tripletas RDF, preservando claves, filas y el significado de las columnas en el proceso.
Probando precisión, escala y fiabilidad
Los investigadores pusieron a prueba su marco con distintos tipos de datos: párrafos de texto de ejemplo, páginas web accesibles por URL y una base de datos relacional. Midieron cuántos de los conceptos y relaciones relevantes el sistema capturó correctamente (recall) y cuántas de sus extracciones eran en realidad correctas (precisión). En los experimentos, la precisión osciló típicamente entre aproximadamente 90 % y 97 %, y el recall entre unos 82 % y 94 %, lo que indica que la canalización captura la mayor parte de la información importante cometiendo relativamente pocos errores. También verificaron cuánto coincidían las consultas sobre los Datos Enlazados resultantes con las respuestas que se obtendrían de las bases de datos originales, encontrando tasas de acuerdo alrededor del 90–97 %. Pruebas de rendimiento con conjuntos de datos crecientes, hasta 160 000 registros, mostraron que el tiempo de procesamiento aumentó más o menos en línea con el tamaño de los datos y que el uso de memoria se mantuvo estable, lo que sugiere que el enfoque escala a colecciones del mundo real más grandes.
Qué significa esto para el uso cotidiano de los datos
En términos prácticos, el trabajo ofrece una manera de convertir una mezcla caótica de tablas, páginas web y documentos en una capa de conocimiento única y conectada. En comparación con las herramientas existentes que solo manejan tablas de bases de datos ordenadas, este marco soporta los tres tipos de datos principales en una sola canalización, a la vez que preserva mejor la estructura y el significado. Aun así quedan lagunas: los medios multimedia como imágenes o vídeo todavía no están incluidos, y algún detalle estructural fino puede perderse al simplificar datos semiestructurados, pero los autores describen cómo versiones futuras podrían abordar estas limitaciones. Para un lector no experto, la conclusión es clara: al traducir contenido digital diverso a un formato compartido y enlazable, este enfoque facilita integrar información, moverla entre sistemas y extraer patrones, acercándonos a una web de datos más inteligente y consultable.
Cita: Sattar, H., Al-Khasawneh, M.A., Shafi, U.F. et al. A data migration and integration approach for big data management using linked data. Sci Rep 16, 12210 (2026). https://doi.org/10.1038/s41598-026-43298-x
Palabras clave: integración de big data, datos enlazados, migración de datos, web semántica, conversión a RDF