Clear Sky Science · he
שיטת הגירה ואינטגרציה של נתונים לניהול נתוני ענק באמצעות Linked Data
מדוע חשוב להסדיר נתונים מבולגנים
כל חיפוש, לחיצה, קריאת חיישן ורכישה מקוונת מוסיפים לאוקיינוס בלתי נראה של מידע. רוב ה"נתוני ענק" הללו מבולגנים: דוא"ל ודפי אינטרנט, יומנים ומסמכים, בנוסף למסדי נתונים מסורתיים יותר. חברות וחוקרים יודעים שמידע זה מסתיר תובנות חשובות, אך הנתונים מפוזרים בפורמטים שונים שאינם משתלבים באופן טבעי. מאמר זה מציע דרך להפוך את התערובת המבולגנת הזו לרשת נתונים אחת ומחוברת היטב שמחשבים יכולים להבין ולנתח באופן חכם יותר.
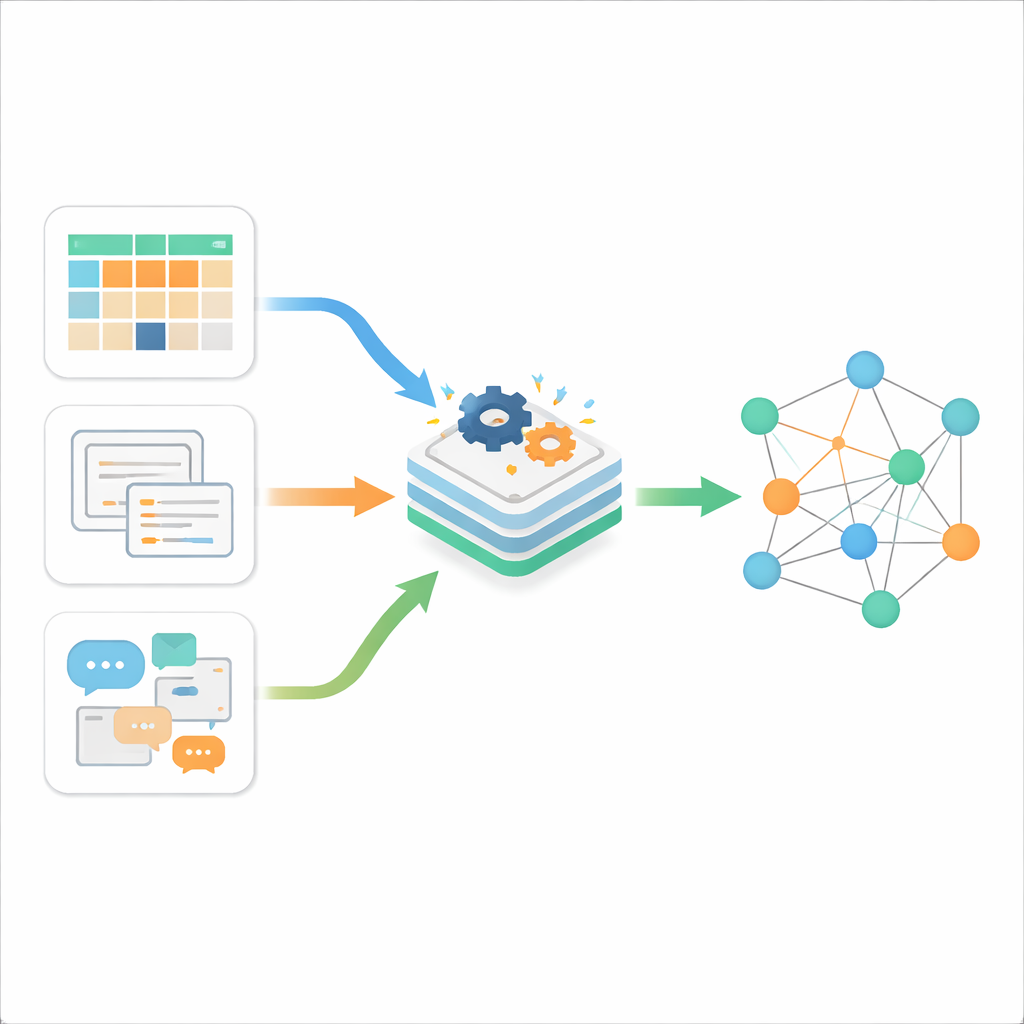
שלושה סוגי בלגן דיגיטלי
המחברים מתחילים בהסבר שמידע מקוון מגיע בדרך כלל בשלושה טעמים. נתונים מובנים הם הסוג הסדור והמסודר, המאוחסן בטבלאות עם שורות ועמודות, כמו מסדי נתונים עסקיים קלאסיים. נתונים חצי-מובנים מכילים কিছু ארגון אך לא מבנה טבלאי קשיח; דוגמאות הן דפי אינטרנט, XML, קבצי JSON או דוא"ל. נתונים לא-מובנים מהווים את הרוב הפרוע—טקסט חופשי, מסמכים ותכנים אחרים שאינם נשמעים לתבנית קבועה. בעוד שכלים מסורתיים מטפלים בסוג אחד מן הנתונים די טוב, המציאות של היום היא זרם מתמיד של שלושתם, הנוצר במהירות על ידי האינטרנט, הסמארטפונים ואינטרנט הדברים. האתגר המרכזי אינו רק לאחסן אותם, אלא לגרום להם "לדבר" זה עם זה באופן משמעותי.
מאיים של נתונים לאיים מקושרים
כדי לגשר בין האיים הללו, המחברים נשענים על רעיון ה-Linked Data, דרך לתאר מידע כך שעובדות יכולות להתחבר בין מקורות—כמו גרסה מורחבת וקריאה למכונה של רשת הקישורים של ויקיפדיה. Linked Data מתבסס על תקן בשם RDF, שבו הידע מפורק ל"טריפלים" פשוטים שמציינים כיצד דבר אחד קשור לדבר אחר. המאמר מציע מסגרת מאוחדת שממירה אוטומטית טבלאות מובנות, קבצים חצי-מובנים וטקסט חופשי לפורמט המקושר הזה. במקום לבנות כלי המרה נפרדים לכל מקור, המסגרת מריצה את כל הקלט דרך צינור דו-חלקי: מודול ניתוח שקובע את סוג הנתונים ומודול סינתזה שהופך את ההבנה הזו להצהרות RDF מקושרות.
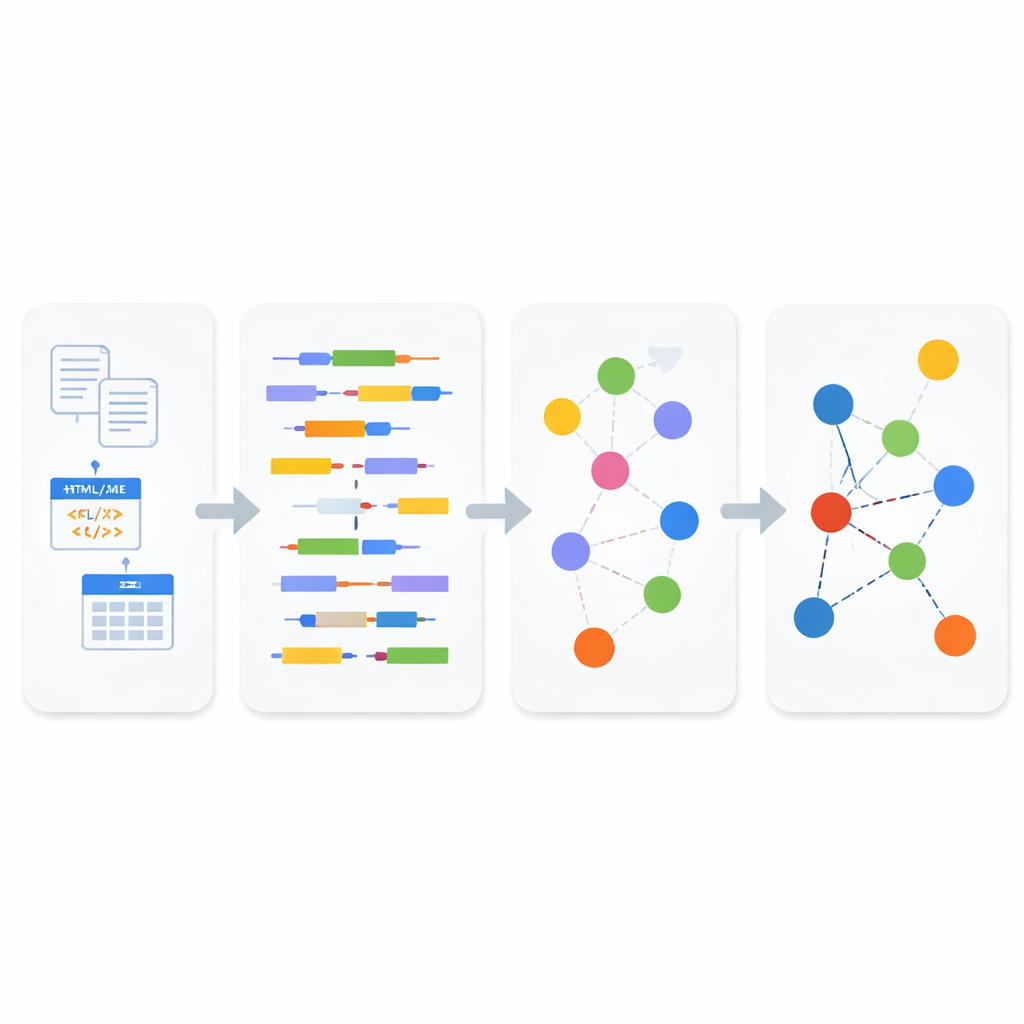
כיצד עובד הצינור החדש
בתוך מודול הניתוח, הנתונים הנכנסים מסווגים תחילה כמובנים, חצי-מובנים או לא-מובנים. לטקסט לא-מובנה ולתוכן רשת חצי-מובנה המערכת מיישמת עיבוד שפה טבעית בשביל לפרק משפטים לנושאים, פעלים ומושאיהם, ולאחר מכן משתמשת בתקן סמנטי מוכוון עסקים הנקרא SBVR לזיהוי מושגים כגון אנשים, ישויות, פעולות ותכונותיהן. מושגים אלה הופכים ליחידות הבניין של Linked Data. עבור פורמטים חצי-מובנים כמו XML ו-JSON, מפענח קל-משקל מתעד בקפידה את היררכיית התגים והתכונות לפני המרתם לטקסט, כדי שלא יאבדו יחסים עמוקים במסמך המקורי. עבור מסדי נתונים מובנים, המערכת משתמשת בכלל טרנספורמציה של מודל-למודל: היא ממירה תחילה טבלאות לייצוג XML, ואז ממפה שיטתי את ה-XML הזה לטריפלי RDF, ושומרת על מפתחות, שורות ומשמעויות עמודות לאורך כל התהליך.
בדיקת דיוק, קנה מידה ואמינות
החוקרים בחנו את המסגרת שלהם על סוגים שונים של נתונים: קטעי טקסט לדוגמה, דפי אינטרנט שניגשו אליהם דרך URLים ומסד נתונים רלציוני. הם מדדו כמה מן המושגים והקשרים הרלוונטיים המערכת זיהתה נכונה (recall) וכמה מהחילוצים שלה היו אכן מדויקים (precision). בניסויים, הדיוק נע בדרך כלל סביב 90%–97% והזכירה סביב 82%–94%, מה שמצביע על כך שהצינור לוכד את רוב המידע החשוב תוך ביצוע יחסית מועט של טעויות. הם בדקו גם עד כמה שאילתות על ה-Linked Data המתקבלות תואמות לתשובות שהתקבלו ממסדי הנתונים המקוריים, ומצאו שיעורי הסכמה סביב 90–97%. מבחני ביצועים עם גדילת מערך הנתונים, עד 160,000 רשומות, הראו כי זמן העיבוד עלה בקירוב ביחס לגודל הנתונים ושימוש הזיכרון נשאר יציב, דבר המצביע על כך שהגישה מתקדמת לקנה מידה המתאים לאוספים גדולים בעולם המציאות.
מה זה אומר לשימוש יומיומי בנתונים
ברמה הפרקטית, העבודה מציעה דרך להפוך תערובת כאוטית של טבלאות, דפי רשת ומסמכים לשכבת ידע אחת מחוברת. בהשוואה לכלים קיימים המטפלים רק בטבלאות מסודרות, מסגרת זו תומכת בשלושת סוגי הנתונים העיקריים בצינור אחד, תוך שמירה טובה יותר על מבנה ומשמעות. עדיין קיימים פערים—מולטימדיה כגון תמונות או וידאו אינם כלולים עדיין, וחלק מפרטי המבנה העדינים עלולים להאבד בפישוט של נתונים חצי-מובנים—אך המחברים מסמנים כיצד גרסאות עתידיות יכולות לטפל במגבלות אלו. לקורא לא מקצועי, המסקנה ברורה: על ידי תרגום תכנים דיגיטליים מגוונים לפורמט משותף וקישור, הגישה הזו מקלה על אינטגרציה של מידע, העברתו בין מערכות וחילוץ דפוסים, ומקרבת אותנו לרשת נתונים חכמה וניתנת לחיפוש יותר.
ציטוט: Sattar, H., Al-Khasawneh, M.A., Shafi, U.F. et al. A data migration and integration approach for big data management using linked data. Sci Rep 16, 12210 (2026). https://doi.org/10.1038/s41598-026-43298-x
מילות מפתח: אינטגרציה של נתוני ענק, linked data, הגירת נתונים, הרשת הסמנטית, המרת RDF