Clear Sky Science · pt
Uma abordagem de migração e integração de dados para gerenciamento de big data usando linked data
Por que domar dados desorganizados importa
Cada busca, clique, leitura de sensor e compra online acrescenta a um oceano invisível de informações. A maior parte desse "big data" é desorganizada: e-mails e páginas da web, logs e documentos, além de bancos de dados mais tradicionais. Empresas e pesquisadores sabem que essa informação esconde insights valiosos, mas os dados estão espalhados por formatos diferentes que não funcionam naturalmente em conjunto. Este artigo apresenta uma forma de transformar essa mistura confusa em uma única teia de dados bem conectada que os computadores podem entender e analisar com mais inteligência.
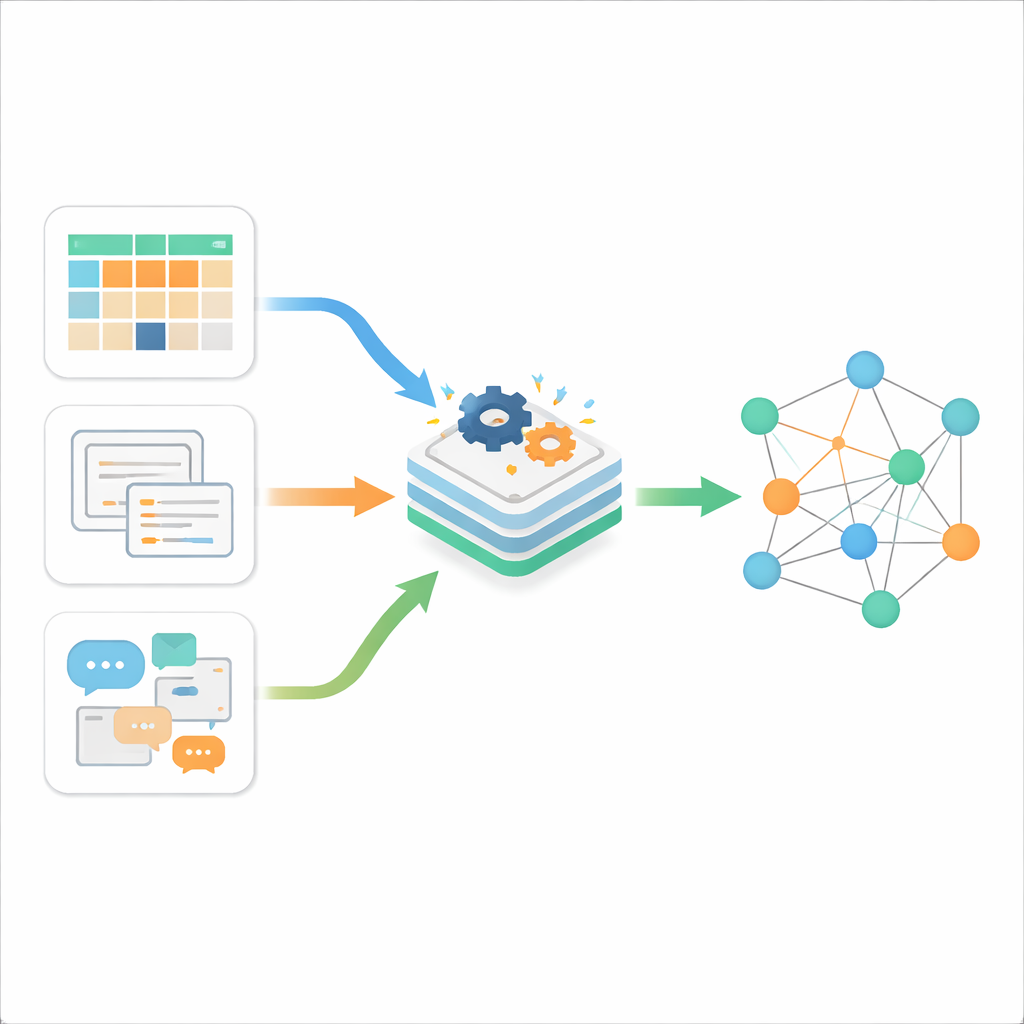
Três tipos de desordem digital
Os autores começam explicando que a informação online normalmente aparece em três tipos. Dados estruturados são os organizados e arrumados, armazenados em tabelas com linhas e colunas, como nos bancos de dados empresariais clássicos. Dados semi-estruturados têm alguma organização, mas não um layout rígido de tabela; exemplos incluem páginas web, arquivos XML, JSON ou e-mails. Dados não estruturados são a grande maioria — texto livre, documentos e outros conteúdos que não seguem um modelo fixo. Enquanto ferramentas tradicionais lidam bem com um desses tipos, a realidade atual é um fluxo constante dos três, gerado em alta velocidade pela web, smartphones e Internet das Coisas. O desafio central não é apenas armazená-los, mas fazê-los comunicar-se entre si de maneira significativa.
De ilhas de dados para uma teia conectada
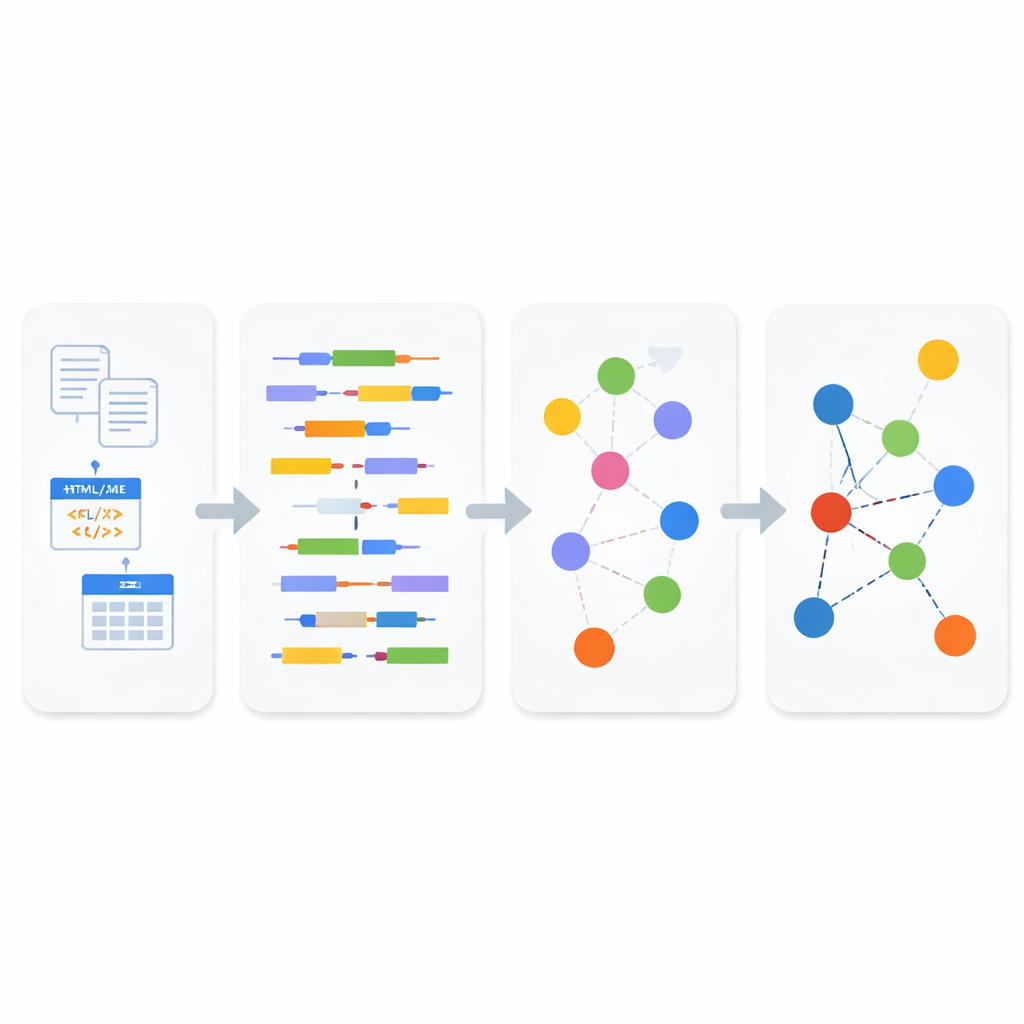
Para ligar essas ilhas, os autores baseiam-se na ideia de Linked Data, uma forma de descrever informações para que fatos possam ser conectados entre fontes, um pouco como uma versão estendida e legível por máquinas da rede de links da Wikipédia. Linked Data depende de um padrão chamado RDF, em que o conhecimento é fragmentado em simples "triplas" que indicam como uma coisa se relaciona com outra. O artigo propõe uma estrutura unificada que converte automaticamente tabelas estruturadas, arquivos semi-estruturados e texto livre para esse formato ligado. Em vez de construir ferramentas de conversão separadas para cada fonte, a estrutura processa tudo por meio de um pipeline em duas partes: um módulo de análise que identifica que tipo de dado está sendo tratado e um módulo de síntese que transforma esse entendimento em declarações RDF interconectadas.
Como o novo pipeline funciona
Dentro do módulo de análise, os dados recebidos são primeiro classificados como estruturados, semi-estruturados ou não estruturados. Para texto não estruturado e conteúdo web semi-estruturado, o sistema aplica processamento de linguagem natural para decompor sentenças em sujeitos, verbos e objetos, e então usa um padrão semântico orientado a negócios chamado SBVR para reconhecer conceitos como pessoas, coisas, ações e suas propriedades. Esses conceitos tornam-se os blocos de construção do Linked Data. Para formatos semi-estruturados como XML e JSON, um parser leve registra cuidadosamente a hierarquia de tags e atributos antes de transformá-los em texto, de modo que relações mais profundas do documento original não se percam. Para bancos de dados estruturados, o sistema usa regras de transformação modelo-a-modelo: primeiro converte tabelas em uma representação XML e depois mapeia sistematicamente esse XML em triplas RDF, preservando chaves, linhas e significados das colunas ao longo do processo.
Testando precisão, escala e confiabilidade
Os pesquisadores testaram a estrutura com diferentes tipos de dados: parágrafos de texto amostrais, páginas web acessadas por URLs e um banco de dados relacional. Mediram quantos dos conceitos e relacionamentos relevantes o sistema capturou corretamente (recall) e quantas de suas extrações estavam realmente certas (precisão). Nos experimentos, a precisão variou tipicamente entre cerca de 90% a 97%, e o recall entre aproximadamente 82% a 94%, indicando que o pipeline captura a maior parte das informações importantes ao cometer relativamente poucos erros. Eles também verificaram quão bem consultas sobre o Linked Data resultante correspondiam às respostas obtidas nos bancos de dados originais, encontrando taxas de concordância em torno de 90–97%. Testes de desempenho com conjuntos de dados crescentes, até 160.000 registros, mostraram que o tempo de processamento aumentou aproximadamente em linha com o tamanho dos dados e o uso de memória permaneceu estável, sugerindo que a abordagem escala para coleções maiores do mundo real.
O que isso significa para o uso cotidiano de dados
Em termos práticos, o trabalho oferece uma maneira de transformar uma mistura caótica de tabelas, páginas web e documentos em uma camada única de conhecimento conectada. Em comparação com ferramentas existentes que lidam apenas com tabelas de banco de dados organizadas, essa estrutura suporta os três principais tipos de dados em um único pipeline, preservando melhor estrutura e significado. Ainda há lacunas — multimídia como imagens ou vídeo não estão incluídos por enquanto, e alguns detalhes estruturais finos podem ser perdidos ao simplificar dados semi-estruturados —, mas os autores descrevem como versões futuras poderiam abordar essas limitações. Para um leitor leigo, a conclusão é clara: ao traduzir conteúdos digitais diversos em um formato compartilhado e linkável, essa abordagem facilita integrar informações, movê-las entre sistemas e extrair padrões, aproximando-nos de uma web de dados mais inteligente e pesquisável.
Citação: Sattar, H., Al-Khasawneh, M.A., Shafi, U.F. et al. A data migration and integration approach for big data management using linked data. Sci Rep 16, 12210 (2026). https://doi.org/10.1038/s41598-026-43298-x
Palavras-chave: integração de big data, linked data, migração de dados, web semântica, conversão para RDF