Clear Sky Science · en
A data migration and integration approach for big data management using linked data
Why Taming Messy Data Matters
Every search, click, sensor reading, and online purchase adds to an invisible ocean of information. Most of this "big data" is messy: emails and web pages, logs and documents, plus more traditional databases. Companies and researchers know this information hides valuable insights, but the data is scattered across different formats that don’t naturally work together. This paper presents a way to turn that messy mix into a single, well-connected web of data that computers can understand and analyze more intelligently.
Three Kinds of Digital Clutter
The authors begin by explaining that online information typically comes in three flavors. Structured data is the neat and tidy kind, stored in tables with rows and columns, such as classic business databases. Semi-structured data has some organization but not a rigid table layout; examples include web pages, XML, JSON files, or emails. Unstructured data is the wild majority—free-form text, documents, and other content that does not follow a fixed template. While traditional tools handle one of these types fairly well, today’s reality is a constant stream of all three, produced at high speed by the web, smartphones, and the Internet of Things. The core challenge is not just storing them, but making them talk to one another in a meaningful way.
From Islands of Data to a Connected Web
To bridge these islands, the authors build on the idea of Linked Data, a way of describing information so that facts can be connected across sources, a bit like an extended, machine-readable version of Wikipedia’s network of links. Linked Data relies on a standard called RDF, where knowledge is broken into simple "triples" that state how one thing is related to another. The paper proposes a unified framework that automatically converts structured tables, semi-structured files, and plain text into this linked format. Instead of building separate conversion tools for each source, the framework runs everything through a two-part pipeline: an analysis module that figures out what kind of data it is dealing with and a synthesis module that turns that understanding into interconnected RDF statements.
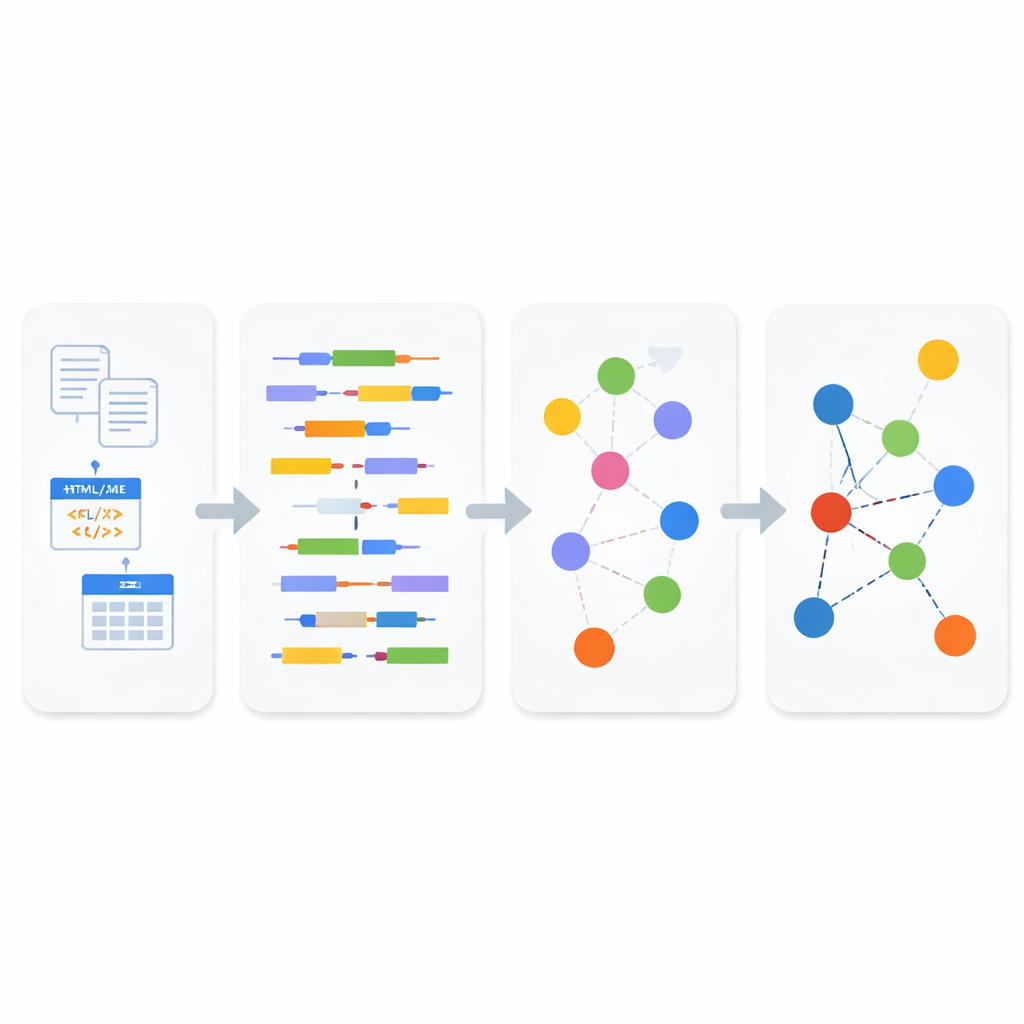
How the New Pipeline Works
Inside the analysis module, incoming data is first classified as structured, semi-structured, or unstructured. For unstructured text and semi-structured web content, the system applies natural language processing to break sentences into subjects, verbs, and objects, then uses a business-oriented semantic standard called SBVR to recognize concepts such as people, things, actions, and their properties. These concepts become the building blocks of Linked Data. For semi-structured formats like XML and JSON, a lightweight parser carefully records the hierarchy of tags and attributes before turning them into text, so that deeper relationships in the original document are not lost. For structured databases, the system uses model-to-model transformation rules: it first converts tables into an XML representation, then systematically maps that XML into RDF triples, preserving keys, rows, and column meanings along the way.
Testing Accuracy, Scale, and Reliability
The researchers put their framework to the test on different kinds of data: sample paragraphs of text, web pages accessed through URLs, and a relational database. They measured how many of the relevant concepts and relationships the system correctly captured (recall) and how many of its extractions were actually right (precision). Across experiments, precision typically ranged from about 90% to 97%, and recall from roughly 82% to 94%, indicating that the pipeline captures most important information while making relatively few mistakes. They also checked how well queries on the resulting Linked Data matched the answers you would get from the original databases, and found agreement rates around 90–97%. Performance tests with growing datasets, up to 160,000 records, showed that processing time increased roughly in line with data size and memory usage remained stable, suggesting the approach scales to larger real-world collections.
What This Means for Everyday Data Use
In practical terms, the work offers a way to turn a chaotic mix of tables, web pages, and documents into a single, connected knowledge layer. Compared with existing tools that only handle neat database tables, this framework supports all three major data types in one pipeline, while better preserving structure and meaning. There are still gaps—multimedia such as images or video are not yet included, and some fine structural detail can be lost when simplifying semi-structured data—but the authors outline how future versions could address these limits. For a lay reader, the takeaway is clear: by translating diverse digital content into a shared, linkable format, this approach makes it easier to integrate information, move it between systems, and mine it for patterns, bringing us closer to a more intelligent, searchable web of data.
Citation: Sattar, H., Al-Khasawneh, M.A., Shafi, U.F. et al. A data migration and integration approach for big data management using linked data. Sci Rep 16, 12210 (2026). https://doi.org/10.1038/s41598-026-43298-x
Keywords: big data integration, linked data, data migration, semantic web, RDF conversion