Clear Sky Science · zh
使用独立与混合化机器学习算法的综合矿石分类
用智能计算机寻找富含矿体的岩石
金矿的成败取决于一个简单问题:哪些岩石值得运往选厂,哪些只是废石?在许多矿床中,金的分布很不均匀,在几米范围内就可能剧烈变化。本文展示了一套现代人工智能工具如何从钻芯中的微小化学线索中筛选出信息,将岩石更可靠地分为矿石、低品位矿石和废石,优于传统方法。
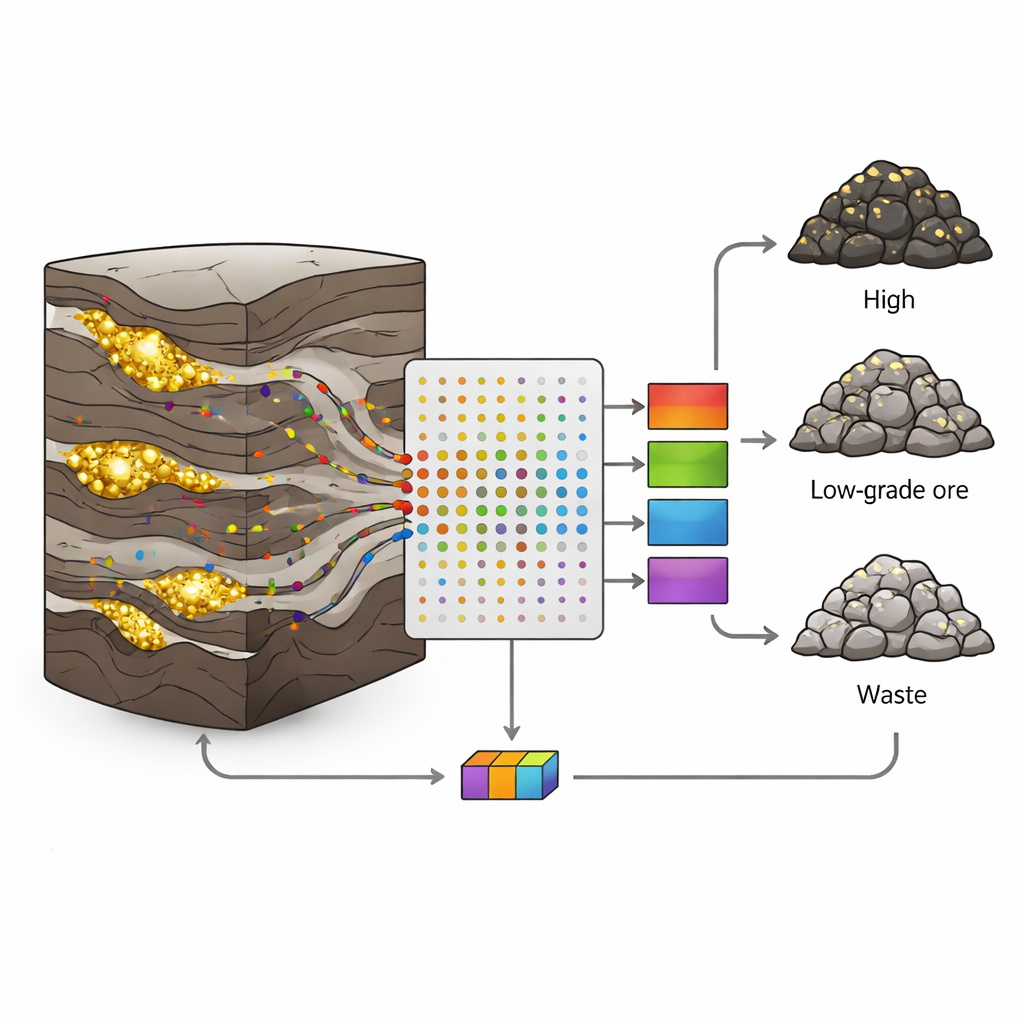
为何金矿难以判读
在伊朗西部的Sari-Gunay金-多金属矿床中,金常出现在狭窄、不规则的脉体中,寄生于复杂的火山岩和沉积岩组合。断层、裂隙和矿化方式的变化使得金品位在短距离内从富矿跳跃到贫瘠。经典的地质与统计方法在这种混乱情形下往往力不从心;它们常假定变化平滑且只使用少数变量。然而每根钻芯包含大量额外信息:伴随含金流体迁移的砷、锑或铋等微量元素的少量存在。挑战在于如何将这些多而嘈杂的测量结果转为关于岩石类型的清晰决策。
把微量元素变成训练数据
作者从八个钻孔中采集了190个一米间隔的芯样。对每个样品用感应耦合等离子体(ICP)分析测量了19种微量元素,然后根据金含量将每个样品分为三类:矿石(>1克/吨)、低品位矿石(0.5–1克/吨)或废石(<0.5克/吨)。每类中约三分之二的样品用于训练模型,剩下的三分之一用于测试模型识别未知数据的能力。这种谨慎的划分有助于避免常见的过拟合陷阱,即算法记住了训练集但在实际应用中失败。
来自机器学习的八种“意见”
为解读化学特征,研究人员部署了八种类型的机器学习模型,涵盖神经网络、模糊逻辑系统以及几种将许多简单决策树组合起来的提升方法。每个模型学习19种微量元素的模式如何对应三种岩石类别。团队自动调整每个算法的关键参数,测试数千个变体以最大化三项性能指标:总体准确率(类别正确的频率)、精确率(每个预测类别的纯度)和召回率(成功找到真实矿石或废石的比例)。在各个单一方法中,一种名为AdaBoost的提升决策树方法取得了最佳平衡,在测试样本上正确分类近90%,并在矿石、低品位和废石三类中犯错最少。
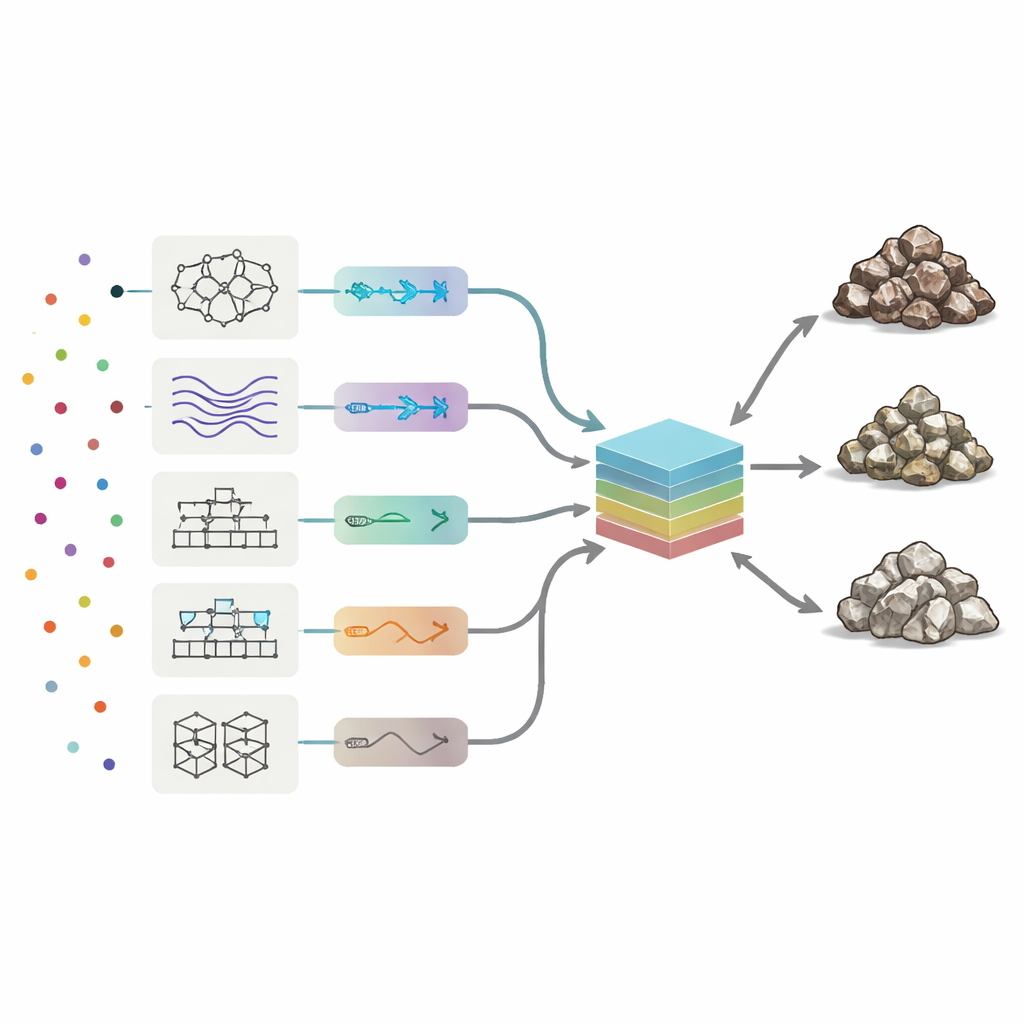
构建模型委员会
作者没有止步于表现最好的单一模型,而是探问将所有八种“意见”结合起来是否能做得更好。他们构建了一个委员会机器:一个最终模型接受八个独立算法的输出并形成加权平均。为决定对每个成员给予多少信任,他们采用了两种受自然过程启发的优化策略——遗传算法和模拟退火。这些方法遍历大量可能的权重组合,寻找能在测试集上给出最高准确率的权重配比。在最佳委员会配置中,AdaBoost和一种混合神经-模糊系统获得了最大的权重,而较弱的模型则提供较小的修正贡献。
为矿山带来更明确的决策
两种委员会版本均显著优于单一模型。尽管单一模型的平均准确率约为88%,经优化的委员会在独立测试集上的准确率、精确率和召回率均达到约94%——提高了约7.28%。与仅用AdaBoost相比,误分类样本几乎减少了一半。对于正在运营的矿山而言,这种改进直接意味着更少的富矿米段被当作废石丢弃,和更少的贫矿送往选厂。简而言之,研究表明将多种机器学习方法融合,并用优化算法引导,可以把微妙的化学踪迹转化为稳健的、在矿山尺度上判断真实含金位置的决策。
引用: Gholami Vijouyeh, A., Kadkhodaie, A., Siahcheshm, K. et al. Integrated ore classification using stand-alone and hybridised machine learning algorithms. Sci Rep 16, 14625 (2026). https://doi.org/10.1038/s41598-026-42248-x
关键词: 金矿石分类, 微量元素地球化学, 采矿中的机器学习, 集成模型, 钻芯分析