Clear Sky Science · it
Classificazione integrata dei minerali usando algoritmi di machine learning autonomi e ibridizzati
Trovare le rocce ricche con computer intelligenti
Le miniere d'oro vivono o muoiono in base a una domanda semplice: quali rocce vale la pena portare al mulino e quali sono solo scarto? In molti giacimenti l'oro è irregolare, cambiando rapidamente in pochi metri. Questo articolo mostra come una serie di strumenti di intelligenza artificiale moderna possa setacciare indizi chimici sottili nei campioni di perforazione per classificare le rocce in minerale, materiale a basso tenore e scarto in modo molto più affidabile rispetto ai metodi tradizionali.
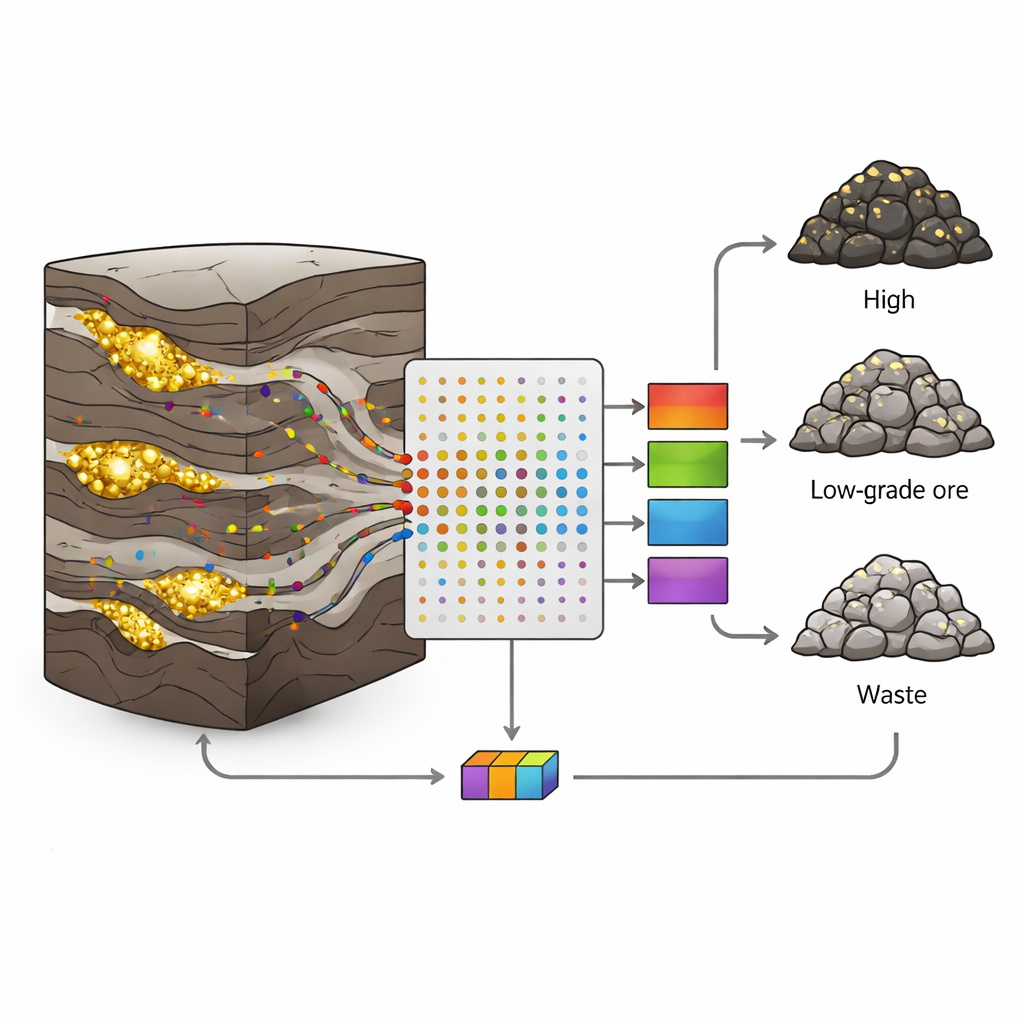
Perché i giacimenti auriferi sono così difficili da interpretare
Nel giacimento aurifero-polimetallico Sari-Gunay nell'Iran occidentale, l'oro si trova in vene strette e irregolari all'interno di un mix complesso di rocce vulcaniche e sedimentarie. Faglie, fratture e variazioni di mineralizzazione fanno sì che i tenori d'oro passino bruscamente dal ricco al sterile su brevi distanze. Gli approcci geologici e statistici classici faticano con tale disordine; spesso assumono cambiamenti graduali e usano solo poche variabili. Eppure ogni nucleo di perforazione contiene una ricchezza di informazioni aggiuntive: piccole quantità di elementi come arsenico, antimonio o bismuto che viaggiano con i fluidi mineralizzanti. La sfida è trasformare queste molteplici e rumorose misure in decisioni chiare sul tipo di roccia.
Trasformare gli elementi in tracce in dati di addestramento
Gli autori hanno raccolto 190 campioni di nucleo da otto carotaggi, ciascuno rappresentante un intervallo di un metro. Per ogni campione hanno misurato 19 elementi in tracce mediante analisi ICP (plasma accoppiato induttivamente), quindi hanno assegnato ogni campione a una delle tre classi in base al contenuto d'oro: minerale (più di 1 grammo per tonnellata), minerale a basso tenore (0,5–1 g/t) o scarto (meno di 0,5 g/t). Circa due terzi dei campioni di ogni classe sono stati usati per addestrare i modelli e il terzo rimanente è stato riservato per testare quanto bene quei modelli riconoscessero dati non visti. Questa divisione accurata ha aiutato a evitare il comune rischio di overfitting, in cui un algoritmo memorizza il set di addestramento ma fallisce nel mondo reale.
Otto diverse “opinioni” dal machine learning
Per leggere le firme chimiche, i ricercatori hanno impiegato otto tipi di modelli di machine learning, dai reti neurali e sistemi di logica fuzzy a diversi metodi di boosting che combinano molti alberi decisionali semplici. Ogni modello ha imparato come i pattern nei 19 elementi in tracce corrispondono alle tre classi di roccia. Il team ha sintonizzato automaticamente i parametri chiave per ogni algoritmo, testando migliaia di varianti per massimizzare tre misure di prestazione: accuratezza complessiva (quanto spesso la classe era corretta), precisione (quanto “pura” era ciascuna classe predetta) e richiamo (quanti veri campioni di minerale o scarto sono stati effettivamente trovati). Tra i metodi singoli, un approccio basato su alberi decisionali potenziati chiamato AdaBoost ha offerto il miglior equilibrio, classificando correttamente quasi il 90% dei campioni di test e commettendo il minor numero di errori tra minerale, basso tenore e scarto.
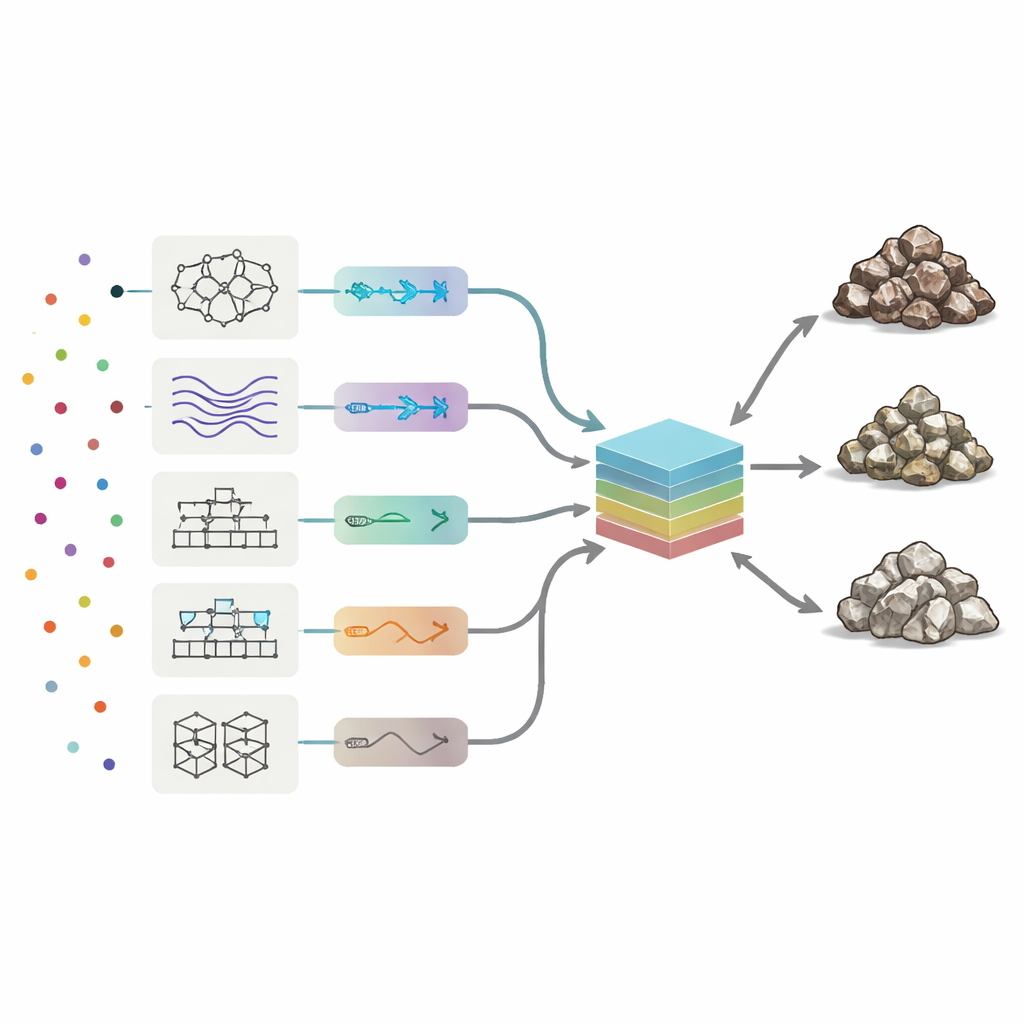
Costruire una commissione di modelli
Invece di fermarsi al miglior singolo performer, gli autori si sono chiesti se combinare tutte e otto le “opinioni” potesse fare ancora meglio. Hanno costruito una macchina a commissione: un modello finale che prende gli output degli otto algoritmi autonomi e forma una media pesata. Per decidere quanta fiducia attribuire a ciascun membro, hanno usato due strategie di ottimizzazione ispirate a processi naturali—algoritmi genetici e simulated annealing. Queste tecniche esplorano molte possibili combinazioni di pesi per trovare la miscela che offre la massima accuratezza sui test. Nelle migliori configurazioni della commissione, AdaBoost e un sistema neuro-fuzzy ibrido hanno ricevuto i pesi maggiori, mentre i modelli più deboli hanno fornito correzioni minori.
Decisioni più nette per la miniera
Entrambe le versioni della commissione hanno sovraperformato significativamente i modelli individuali. Mentre l'accuratezza media dei singoli modelli era circa l'88%, la commissione ottimizzata ha raggiunto approssimativamente il 94% di accuratezza, precisione e richiamo sul set di test indipendente—un miglioramento del 7,28%. I campioni classificati erroneamente sono quasi dimezzati rispetto ad AdaBoost da solo. Per una miniera operativa, quel miglioramento si traduce direttamente in meno metri ricchi scartati come rifiuto e meno rocce sterili inviate al mulino. In termini semplici, lo studio dimostra che mescolare più approcci di machine learning, guidati da algoritmi di ottimizzazione, può trasformare tracce chimiche sottili in decisioni robuste su scala di miniera su dove si trova il vero oro.
Citazione: Gholami Vijouyeh, A., Kadkhodaie, A., Siahcheshm, K. et al. Integrated ore classification using stand-alone and hybridised machine learning algorithms. Sci Rep 16, 14625 (2026). https://doi.org/10.1038/s41598-026-42248-x
Parole chiave: classificazione del minerale aurifero, geochimica degli elementi in tracce, machine learning nell'estrazione, modelli ensemble, analisi del nucleo di perforazione