Clear Sky Science · es
Clasificación integrada de mena mediante algoritmos de aprendizaje automático autónomos e hibridados
Encontrar rocas ricas con ordenadores inteligentes
Las minas de oro viven o mueren por una pregunta simple: ¿qué rocas vale la pena llevar al molino y cuáles son sólo desecho? En muchos yacimientos el oro es irregular, cambiando rápidamente en apenas unos metros. Este artículo muestra cómo un conjunto de herramientas modernas de inteligencia artificial puede cribar las sutiles pistas químicas en testigos de perforación para clasificar las rocas en mena, material de bajo grado y desecho de forma mucho más fiable que los métodos tradicionales.
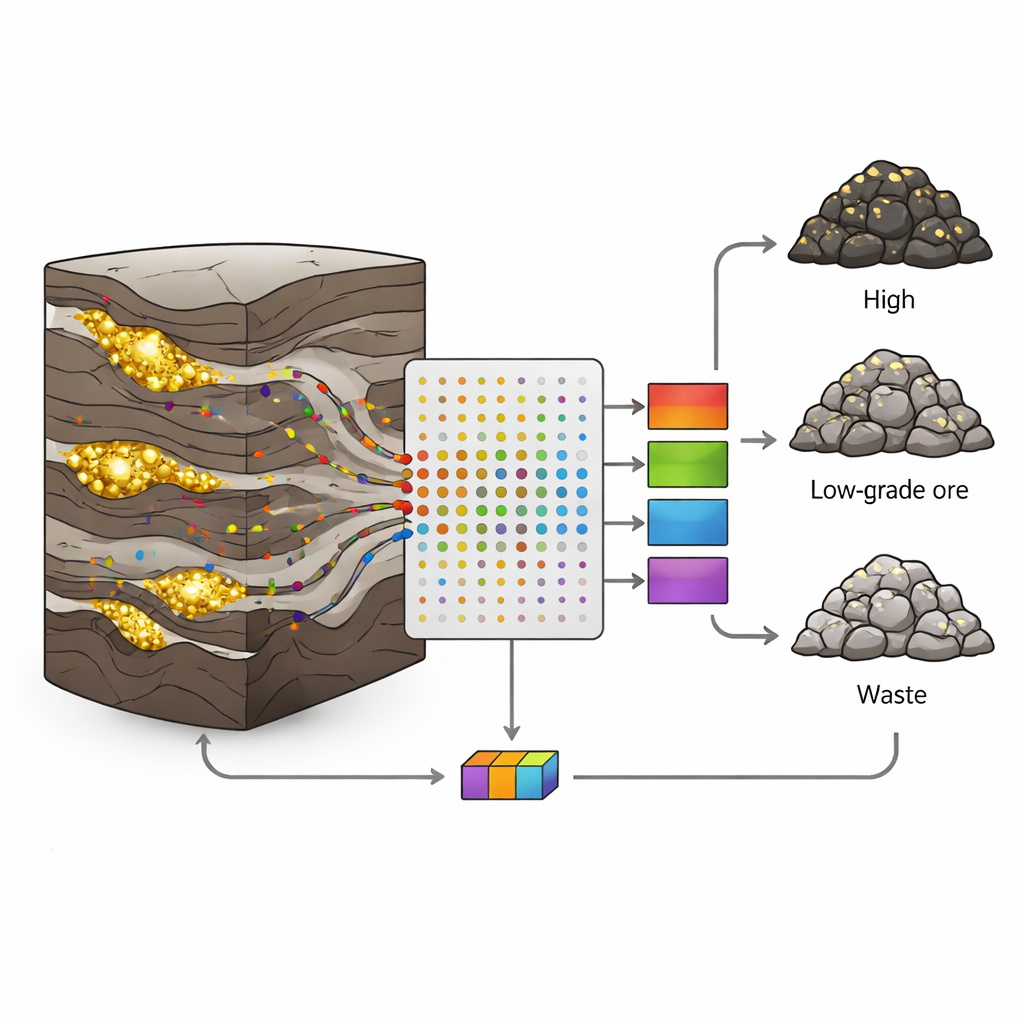
Por qué los yacimientos auríferos son tan difíciles de interpretar
En la mina aurífera polimetálica Sari-Gunay, en el oeste de Irán, el oro aparece en vetas estrechas e irregulares dentro de una mezcla compleja de rocas volcánicas y sedimentarias. Fallas, fracturas y cambios en la mineralización hacen que las leyes de oro salten bruscamente de ricas a estériles en distancias cortas. Los enfoques geológicos y estadísticos clásicos tienen problemas con esta desordenada realidad; a menudo asumen cambios suaves y usan sólo unas pocas variables. Sin embargo, cada testigo de perforación contiene una gran cantidad de información adicional: trazas de elementos como arsénico, antimonio o bismuto que viajan con los fluidos portadores de oro. El reto es convertir esas muchas mediciones ruidosas en decisiones claras sobre el tipo de roca.
Convertir elementos traza en datos de entrenamiento
Los autores recogieron 190 muestras de testigos procedentes de ocho sondeos, cada una representando un intervalo de un metro. Para cada muestra midieron 19 elementos traza mediante análisis por plasma acoplado inductivamente (ICP), y luego asignaron cada muestra a una de tres clases según su contenido de oro: mena (más de 1 gramo por tonelada), mena de bajo grado (0,5–1 g/t) o desecho (menos de 0,5 g/t). Aproximadamente dos tercios de las muestras de cada clase se utilizaron para entrenar los modelos, y el tercio restante se reservó para probar lo bien que esos modelos reconocían datos no vistos. Esta partición cuidadosa ayudó a evitar la trampa habitual del sobreajuste, en la que un algoritmo memoriza el conjunto de entrenamiento pero fracasa en el mundo real.
Ocho “opiniones” distintas del aprendizaje automático
Para leer las firmas químicas, los investigadores desplegaron ocho tipos de modelos de aprendizaje automático, que van desde redes neuronales y sistemas de lógica difusa hasta varios métodos de boosting que combinan muchos árboles de decisión simples. Cada modelo aprendió cómo los patrones en los 19 elementos traza se correspondían con las tres clases de roca. El equipo ajustó automáticamente los parámetros clave de cada algoritmo, probando miles de variantes para maximizar tres medidas de rendimiento: exactitud global (con qué frecuencia la clase era correcta), precisión (qué tan pura era cada clase predicha) y recall (cuántas muestras verdaderas de mena o desecho fueron detectadas). Entre los métodos individuales, un enfoque de árboles de decisión potenciados llamado AdaBoost ofreció el mejor equilibrio, clasificando correctamente casi el 90% de las muestras de prueba y cometiendo el menor número de errores entre mena, bajo grado y desecho.
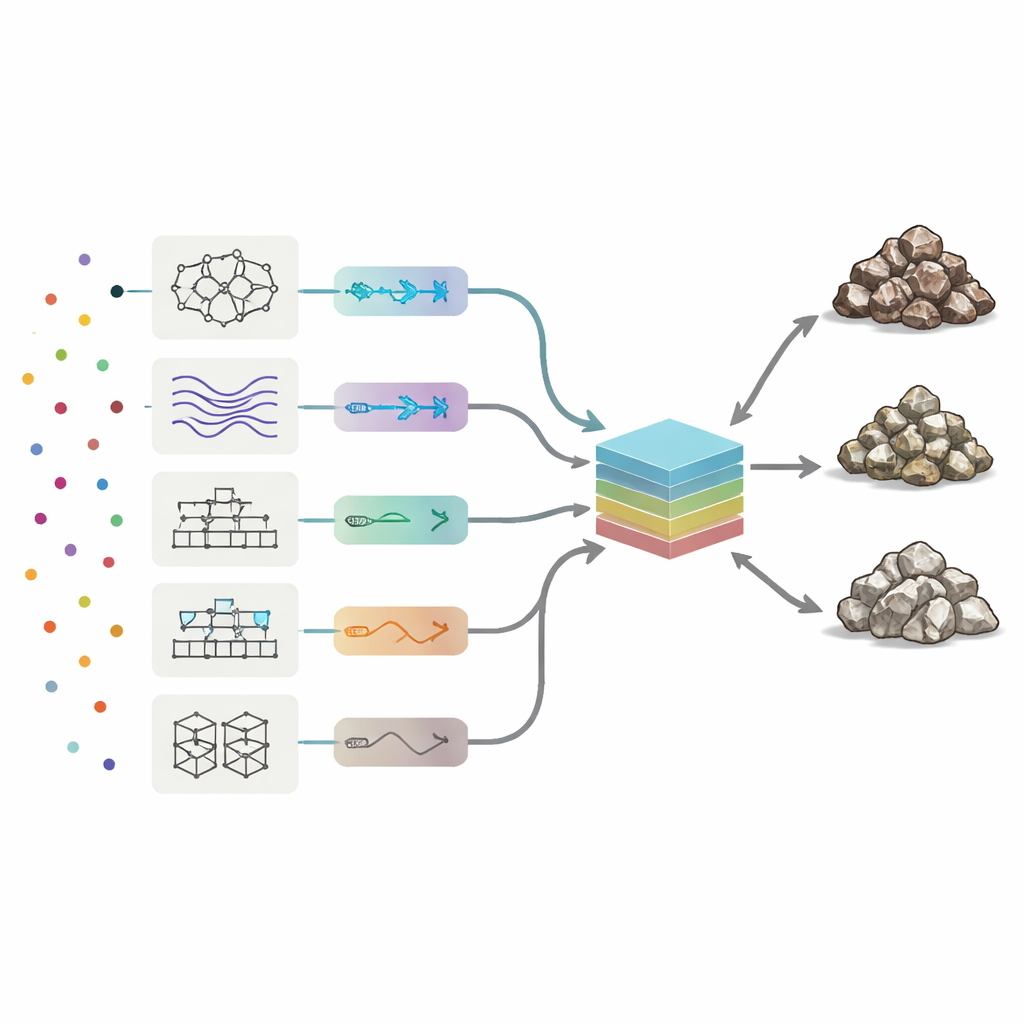
Construir un comité de modelos
En lugar de detenerse en el mejor rendimiento en solitario, los autores se preguntaron si combinar las ocho “opiniones” podría mejorar aún más los resultados. Construyeron una máquina comité: un modelo final que toma las salidas de los ocho algoritmos independientes y forma un promedio ponderado. Para decidir cuánta confianza depositar en cada miembro, emplearon dos estrategias de optimización inspiradas en procesos naturales: algoritmos genéticos y recocido simulado. Estos buscan entre muchas combinaciones posibles de pesos para encontrar la mezcla que proporciona la mayor exactitud de prueba. En las mejores configuraciones del comité, AdaBoost y un sistema neuro-difuso híbrido llevaron los mayores pesos, mientras que los modelos más débiles contribuyeron con correcciones menores.
Decisiones más afinadas para la mina
Ambas versiones del comité superaron significativamente a los modelos individuales. Mientras que la exactitud media de los modelos independientes era de alrededor del 88%, el comité optimizado alcanzó aproximadamente un 94% de exactitud, precisión y recall en el conjunto de prueba independiente—una mejora del 7,28%. Las muestras mal clasificadas se redujeron casi a la mitad en comparación con AdaBoost solo. Para una mina en operación, esa mejora se traduce directamente en menos metros ricos descartados como desecho y menos roca estéril enviada al molino. En términos sencillos, el estudio muestra que mezclar múltiples enfoques de aprendizaje automático, guiados por algoritmos de optimización, puede convertir trazas químicas sutiles en decisiones robustas a escala de mina sobre dónde se encuentra el oro real.
Cita: Gholami Vijouyeh, A., Kadkhodaie, A., Siahcheshm, K. et al. Integrated ore classification using stand-alone and hybridised machine learning algorithms. Sci Rep 16, 14625 (2026). https://doi.org/10.1038/s41598-026-42248-x
Palabras clave: clasificación de mena aurífera, geoquímica de elementos traza, aprendizaje automático en minería, modelos ensamblados, análisis de testigos de perforación