Clear Sky Science · ru
Интегрированная классификация руд с использованием автономных и гибридных алгоритмов машинного обучения
Поиск богатых пород с помощью умных компьютеров
Судьба золотых месторождений часто решается простым вопросом: какие породы стоит везти на переработку, а какие — просто отбросить? Во многих месторождениях золото распределено кусками, меняясь резко на всего нескольких метрах. В этой статье показано, как набор современных инструментов искусственного интеллекта может просеять тонкие химические подсказки в кернах бурения и надёжнее, чем традиционные методы, разделять породы на руду, низкосортный материал и отходы.
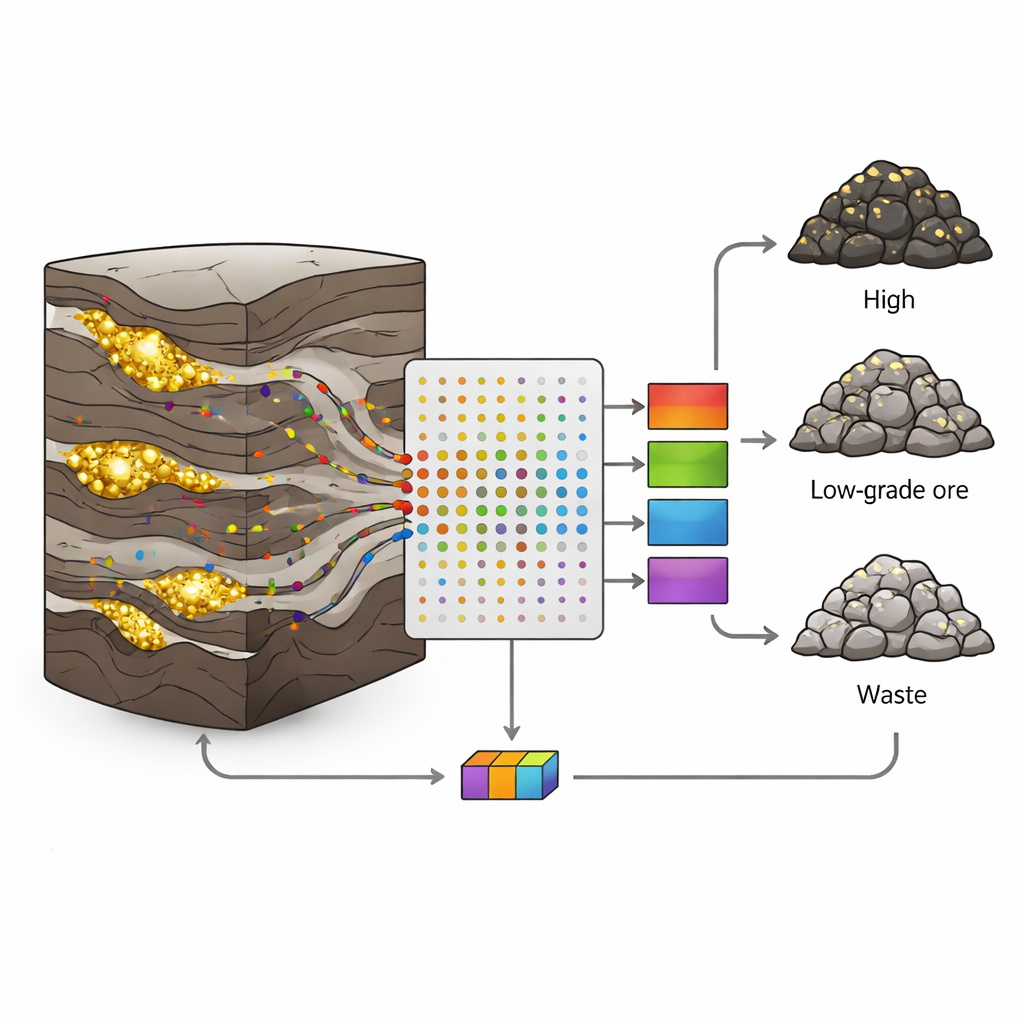
Почему золотые месторождения так трудно прочитать
На руднике Сари‑Гунай в западном Иране золото встречается в узких нерегулярных жилах внутри сложного сочетания вулканических и осадочных пород. Разломы, трещины и переменная минерализация вызывают резкие скачки содержания золота от богатых участков к пустым на небольших расстояниях. Классические геологические и статистические подходы с трудом справляются с такой беспорядочностью: они часто предполагают плавные изменения и используют лишь несколько переменных. Между тем в каждом керне скрыто множество дополнительных сведений: крошечные количества элементов, таких как мышьяк, сурьма или висмут, которые транспортируются вместе с флюидами, несущими золото. Задача — превратить эти многочисленные, шумные измерения в чёткие решения о типе породы.
Преобразование следовых элементов в обучающие данные
Авторы собрали 190 образцов керна из восьми скважин, каждый представлял интервал в один метр. Для каждого образца они измерили 19 следовых элементов методом индуктивно-связанной плазмы (ICP), затем отнесли образец к одному из трёх классов по содержанию золота: руда (более 1 г/т), низкосортная руда (0,5–1 г/т) или отходы (меньше 0,5 г/т). Около двух третей образцов в каждом классе использовали для обучения моделей, а оставшуюся треть зарезервировали для проверки способности моделей распознавать невидимые данные. Такое аккуратное разделение помогло избежать распространённой ошибки переобучения, когда алгоритм запоминает тренировочный набор, но терпит неудачу в реальной практике.
Восемь разных «мнений» от машинного обучения
Чтобы прочитать химические подписи, исследователи применили восемь типов моделей машинного обучения — от нейронных сетей и нечетких логических систем до нескольких методов бустинга, которые объединяют множество простых решающих деревьев. Каждая модель обучалась связывать шаблоны в 19 следовых элементах с тремя классами пород. Команда автоматически настраивала ключевые параметры для каждого алгоритма, тестируя тысячи вариантов, чтобы максимизировать три показателя эффективности: общую точность (как часто класс был угадан правильно), точность предсказаний (насколько «чистым» был каждый предсказанный класс) и полноту (сколько реальных образцов руды или отходов было успешно найдено). Среди отдельных методов лучший баланс показал бустинг решающих деревьев под названием AdaBoost — он правильно классифицировал почти 90% тестовых образцов и сделал наименьшее число ошибок по всем трём классам.
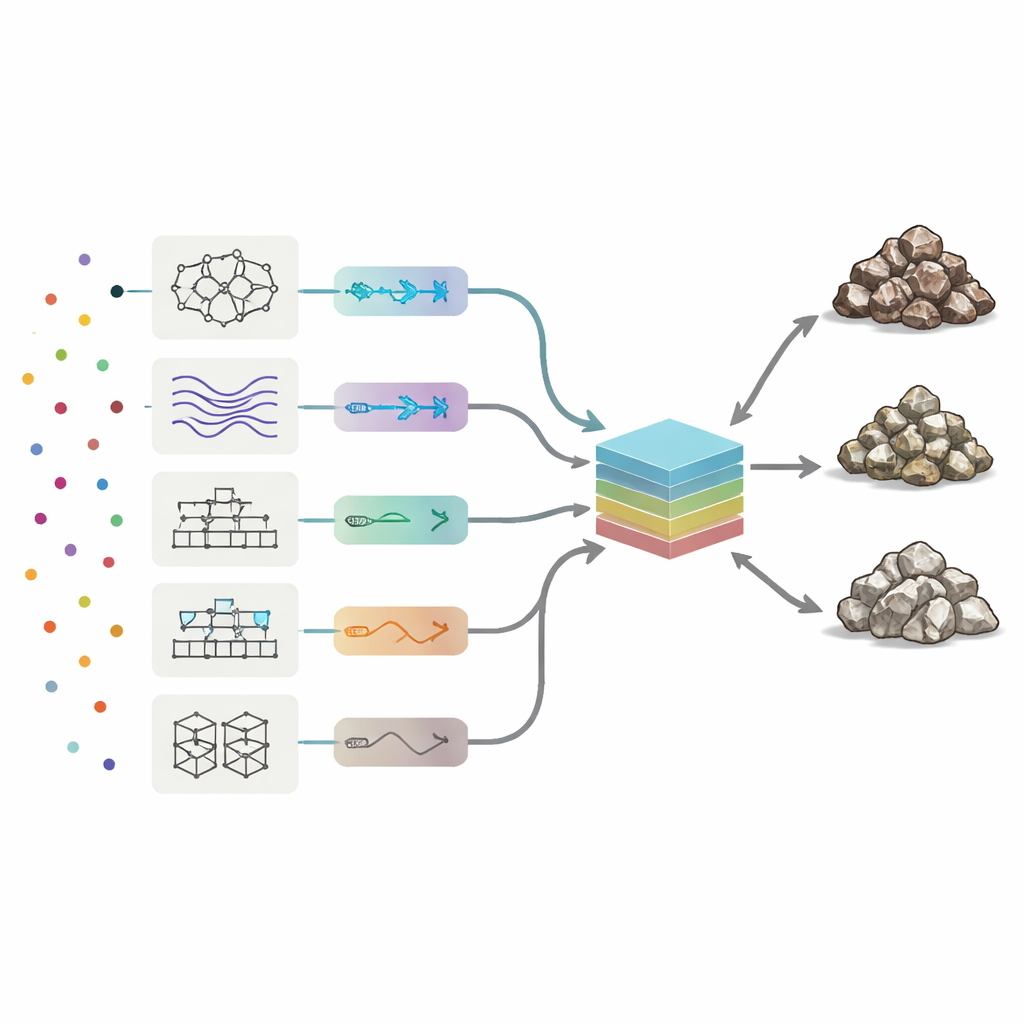
Построение комитета моделей
Вместо того чтобы остановиться на лучшем одиночном исполнителе, авторы поинтересовались, не даст ли сочетание всех восьми «мнений» ещё лучший результат. Они создали комитетную машину: итоговую модель, которая принимает выходы восьми автономных алгоритмов и формирует взвешенное усреднение. Чтобы определить, сколько доверия отдавать каждому участнику, использовали две стратегии оптимизации, вдохновлённые природными процессами — генетические алгоритмы и имитацию отжига. Они просматривают множество возможных комбинаций весов, чтобы найти смесь, дающую наивысшую точность на тесте. В лучших конфигурациях комитета наибольшие веса получили AdaBoost и гибридная нейро‑нечёткая система, тогда как более слабые модели вносили небольшие корректировки.
Более чёткие решения для рудника
Обе версии комитета заметно превзошли отдельные модели. В то время как средняя точность одиночных моделей составляла около 88%, оптимизированный комитет достиг примерно 94% по точности, точности предсказаний и полноте на независимом тестовом наборе — улучшение на 7,28%. Количество неверно классифицированных образцов сократилось почти вдвое по сравнению с одним AdaBoost. Для действующего рудника такое улучшение прямо переводится в меньшую потерю богатых метров, отправленных в отходы, и меньше пустой породы, отправляемой на переработку. Проще говоря, исследование показывает, что сочетание разных подходов машинного обучения, управляемое алгоритмами оптимизации, может превратить тонкие химические следы в надёжные решения масштаба рудника о том, где находится настоящее золото.
Цитирование: Gholami Vijouyeh, A., Kadkhodaie, A., Siahcheshm, K. et al. Integrated ore classification using stand-alone and hybridised machine learning algorithms. Sci Rep 16, 14625 (2026). https://doi.org/10.1038/s41598-026-42248-x
Ключевые слова: классификация золотой руды, геохимия следовых элементов, машинное обучение в горнодобыче, ансамблевые модели, анализ керна бурения