Clear Sky Science · sv
Integrerad malmklassificering med fristående och hybridiserade maskininlärningsalgoritmer
Hitta rika bergarter med smarta datorer
Guldgruvor lever eller dör på en enkel fråga: vilka bergarter är värda att föra till anrikningsverket, och vilka är bara avfall? I många fyndigheter är guldet fläckvis fördelat och förändras snabbt över bara några meter. Denna artikel visar hur en uppsättning moderna artificiella intelligens‑verktyg kan sålla igenom subtila kemiska ledtrådar i borrkärnor för att sortera bergarter till malm, låggradigt material och avfall mycket mer tillförlitligt än traditionella metoder.
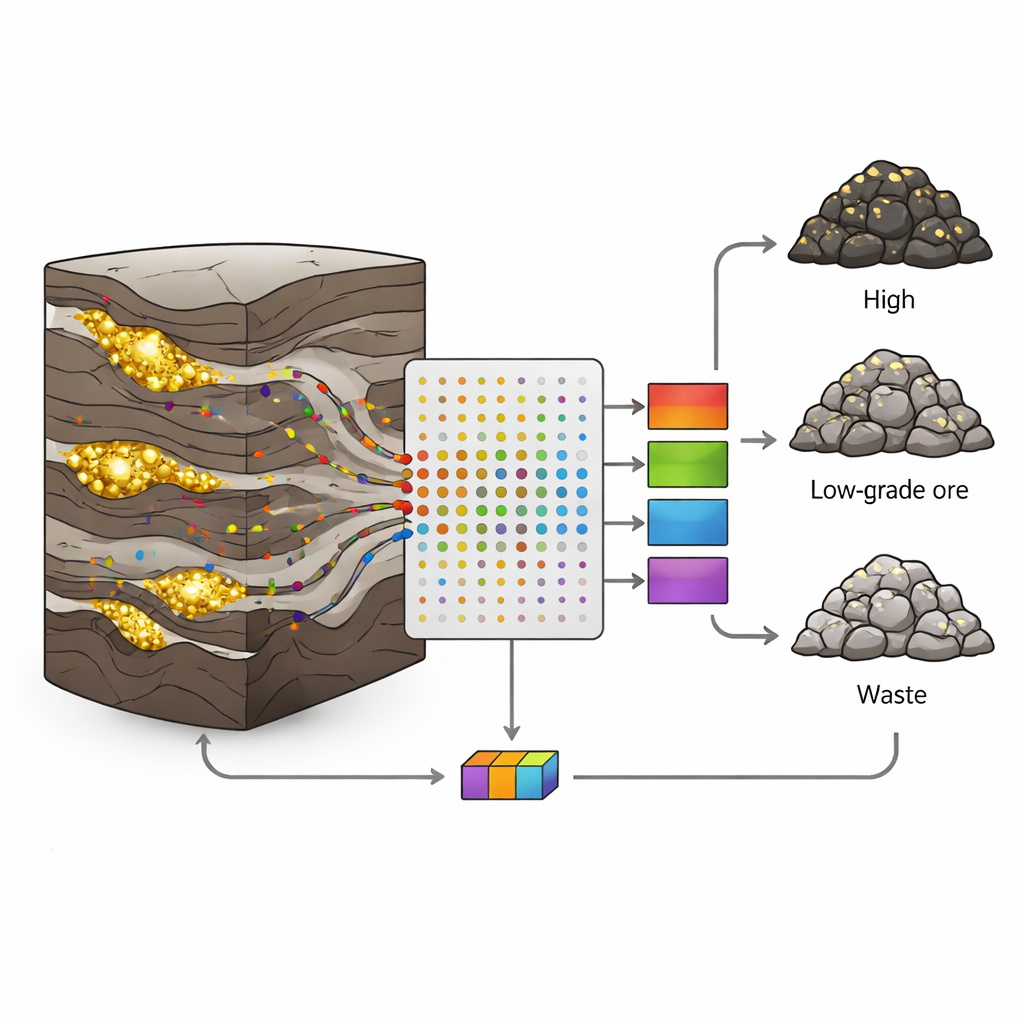
Varför guldavlagringar är så svåra att läsa
I Sari‑Gunay‑guld‑polymetallgruvan i västra Iran förekommer guldet i smala, oregelbundna ådror inom en komplex blandning av vulkaniska och sedimentära bergarter. Fält, sprickor och varierande mineralisering gör att guldhalter hoppar abrupt från rika till sterila över korta avstånd. Klassiska geologiska och statistiska angreppssätt har svårt med sådan oordning; de antar ofta jämna förändringar och använder bara ett fåtal variabler. Men varje borrkärna rymmer en mängd extra information: mycket små mängder element som arsenik, antimon eller vismut som transporteras med guldbärande vätskor. Utmaningen är att omvandla dessa många, brusiga mätningar till tydliga beslut om bergartstyp.
Göra spårelement till träningsdata
Författarna samlade 190 kärnprover från åtta borrhål, varje prov motsvarande ett ettmetersintervall. För varje prov mätte de 19 spårelement med induktivt kopplad plasma (ICP)‑analys och klassade sedan varje prov i en av tre klasser baserat på dess guldinnehåll: malm (mer än 1 gram per ton), låggradig malm (0,5–1 g/t) eller avfall (mindre än 0,5 g/t). Cirka två tredjedelar av proven i varje klass användes för att träna modellerna, och den återstående tredjedelen reserverades för att testa hur väl modellerna kunde känna igen osedda data. Denna noggranna uppdelning hjälpte till att undvika den vanliga fallgropen överanpassning, där en algoritm memorerar träningsdata men misslyckas i verkligheten.
Åtta olika ”åsikter” från maskininlärning
För att läsa de kemiska signaturerna använde forskarna åtta typer av maskininlärningsmodeller, från neurala nätverk och fuzzy‑logiksystem till flera boostingmetoder som kombinerar många enkla beslutsträd. Varje modell lärde sig hur mönster i de 19 spårelementen motsvarade de tre bergartsklasserna. Teamet ställde automatiskt in nyckelparametrar för varje algoritm och testade tusentals varianter för att maximera tre prestationsmått: total noggrannhet (hur ofta klassificeringen var korrekt), precision (hur ren varje förutsagd klass var) och recall (hur många verkliga malm‑ eller avfallsprover som framgångsrikt hittades). Bland de individuella metoderna gav en boostad beslutsträdsmetod kallad AdaBoost den bästa balansen, och klassificerade nästan 90 % av testproven korrekt och gjorde minst fel över malm, låggradigt material och avfall.
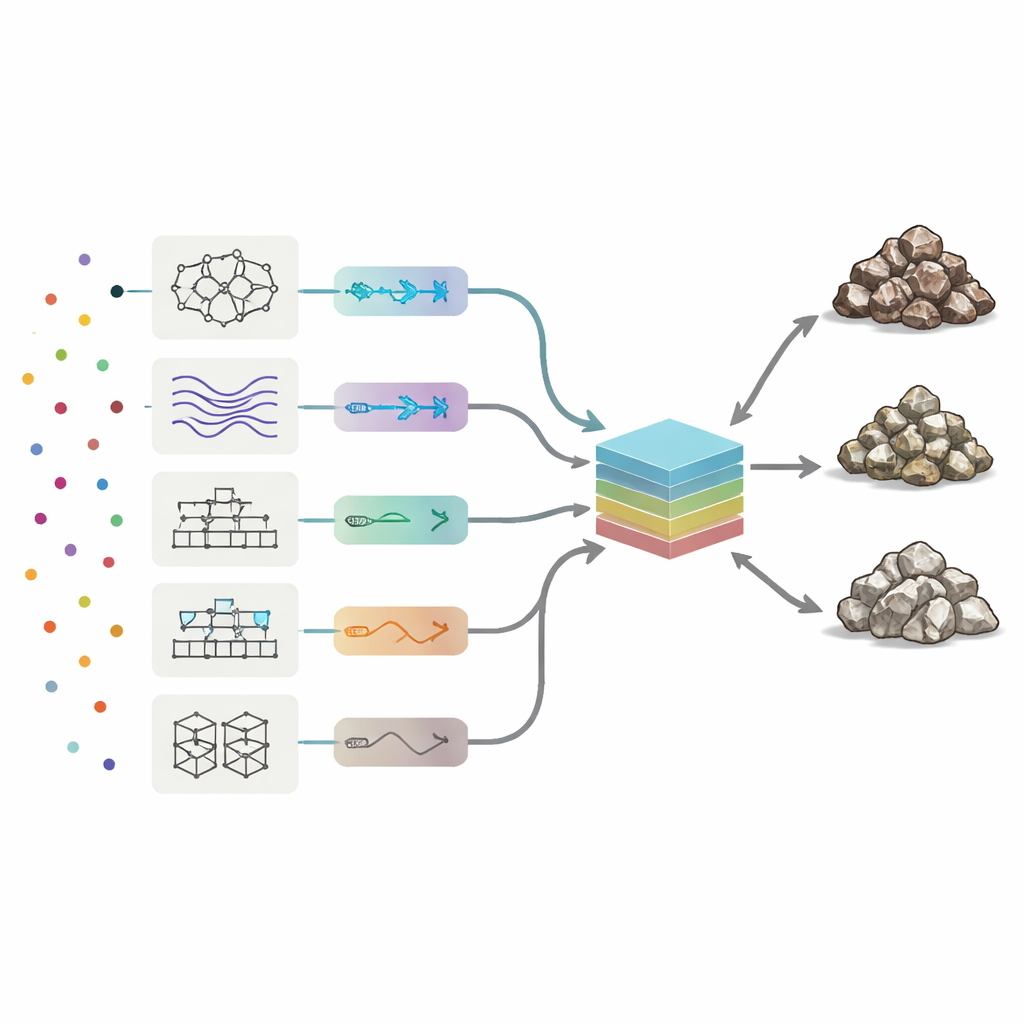
Bygga en kommitté av modeller
I stället för att nöja sig med bästa ensampresteraren frågade författarna om en kombination av alla åtta ”åsikter” kunde bli ännu bättre. De byggde en kommittémaskin: en slutlig modell som tar utdata från de åtta fristående algoritmerna och bildar ett viktat medelvärde. För att bestämma hur mycket förtroende som skulle ges varje medlem använde de två optimeringsstrategier inspirerade av naturliga processer — genetiska algoritmer och simulerad glödgning. Dessa söker genom många möjliga viktkombinationer för att hitta den mix som ger högst testnoggrannhet. I de bästa kommittékonfigurationerna bar AdaBoost och ett hybrid neuro‑fuzzy‑system de största vikterna, medan svagare modeller bidrog med mindre korrigeringar.
Skarpare beslut för gruvan
Båda kommittéversionerna överträffade de individuella modellerna avsevärt. Medan genomsnittlig fristående noggrannhet låg omkring 88 % nådde den optimerade kommittén ungefär 94 % i noggrannhet, precision och recall på den oberoende testuppsättningen — en förbättring med 7,28 %. Felklassificerade prover halverades nästan jämfört med AdaBoost ensam. För en aktiv gruva översätts den förbättringen direkt till färre rika meter som kasseras som avfall och mindre steril bergart som skickas till anrikningsverket. I klara ord visar studien att en blandning av flera maskininlärningsmetoder, vägledd av optimeringsalgoritmer, kan förvandla subtila kemiska spår till robusta beslut i gruvskala om var det verkliga guldet finns.
Citering: Gholami Vijouyeh, A., Kadkhodaie, A., Siahcheshm, K. et al. Integrated ore classification using stand-alone and hybridised machine learning algorithms. Sci Rep 16, 14625 (2026). https://doi.org/10.1038/s41598-026-42248-x
Nyckelord: klassificering av guldmalm, spårelementgeokemi, maskininlärning inom gruvdrift, ensemblemodeller, analys av borrkärnor