Clear Sky Science · de
Integrierte Erzklassifizierung mit eigenständigen und hybridisierten Machine‑Learning‑Algorithmen
Reiche Gesteine mit schlauen Rechnern finden
Goldminen leben oder sterben an einer einfachen Frage: Welche Gesteine lohnen sich zu verarbeiten, und welche sind bloßer Abfall? In vielen Lagerstätten ist das Gold sehr ungleich verteilt und ändert sich bereits über wenige Meter stark. Diese Studie zeigt, wie ein Set moderner künstlicher‑Intelligenz‑Werkzeuge subtile chemische Hinweise in Bohrkernen auswerten kann, um Gesteine zuverlässiger als traditionelle Methoden in Erz, minderwertiges Erz und Abfall zu sortieren.
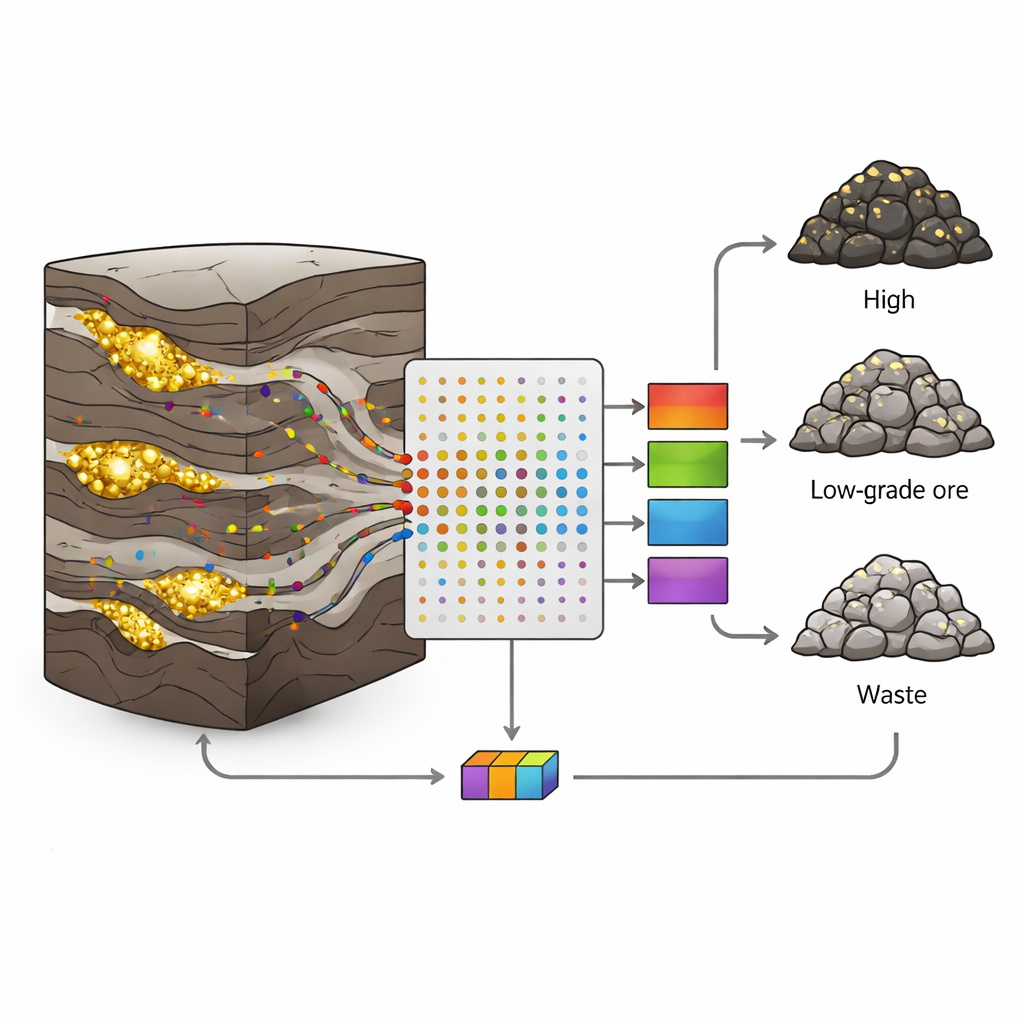
Warum Goldvorkommen so schwer zu lesen sind
In der Sari‑Gunay‑Gold‑Polymetall‑Mine im Westen Irans tritt Gold in schmalen, unregelmäßigen Adern innerhalb eines komplexen Gemischs aus vulkanischen und sedimentären Gesteinen auf. Störungen, Klüfte und wechselnde Mineralisierung lassen die Goldgehalte über kurze Distanzen abrupt von ergiebig zu erzfremd schwanken. Klassische geologische und statistische Ansätze tun sich mit solcher Unordnung schwer; sie setzen oft auf glatte Verläufe und nur wenige Variablen. Jeder Bohrkern enthält jedoch eine Fülle zusätzlicher Informationen: winzige Mengen von Elementen wie Arsen, Antimon oder Wismut, die mit den goldführenden Fluiden transportiert werden. Die Herausforderung besteht darin, diese zahlreichen, verrauschten Messwerte in klare Entscheidungen über Gesteinsklasse zu überführen.
Spurenelemente in Trainingsdaten verwandeln
Die Autoren sammelten 190 Kernproben aus acht Bohrlöchern, jeweils repräsentativ für ein ein Meter langes Intervall. Für jede Probe maßen sie 19 Spurenelemente mittels induktiv gekoppelter Plasmaanalyse (ICP) und ordneten dann jede Probe einer von drei Klassen nach ihrem Goldgehalt zu: Erz (mehr als 1 Gramm pro Tonne), niedriggradiges Erz (0,5–1 g/t) oder Abfall (weniger als 0,5 g/t). Etwa zwei Drittel der Proben jeder Klasse wurden zum Trainieren der Modelle verwendet, das übrige Drittel blieb für Tests zurück, um zu prüfen, wie gut die Modelle unbekannte Daten erkennen. Diese sorgfältige Aufteilung half, das häufige Problem des Overfittings zu vermeiden, bei dem ein Algorithmus die Trainingsdaten auswendig lernt, aber in der Praxis versagt.
Acht verschiedene „Meinungen“ aus dem maschinellen Lernen
Um die chemischen Signaturen zu lesen, setzten die Forscher acht Arten von Machine‑Learning‑Modellen ein, von neuronalen Netzen und Fuzzy‑Logic‑Systemen bis hin zu mehreren Boosting‑Verfahren, die viele einfache Entscheidungsbäume kombinieren. Jedes Modell lernte, wie Muster in den 19 Spurenelementen den drei Gesteinsklassen entsprechen. Das Team passte automatisch zentrale Parameter für jeden Algorithmus an und testete tausende Varianten, um drei Leistungsmaße zu maximieren: Gesamtgenauigkeit (wie oft die Klasse korrekt war), Präzision (wie sauber jede vorhergesagte Klasse war) und Recall (wie viele echte Erz‑ oder Abfallproben erfolgreich gefunden wurden). Unter den Einzelmethoden erzielte ein boosted Entscheidungsbaumverfahren namens AdaBoost die beste Balance und klassifizierte fast 90 % der Testproben korrekt, mit den wenigsten Fehlern über Erz, niedriggradiges Erz und Abfall hinweg.
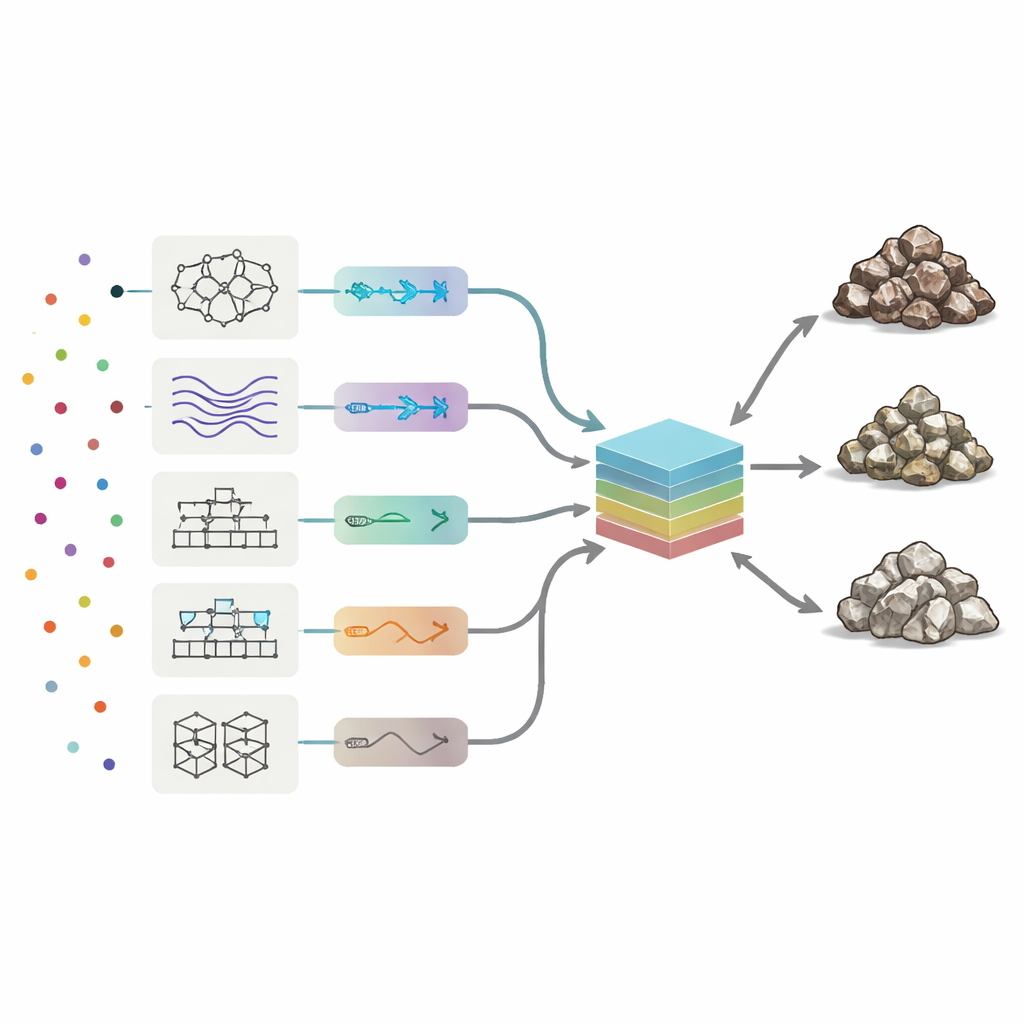
Ein Gremium aus Modellen bilden
Statt beim besten Einzelergebnis zu bleiben, fragten die Autoren, ob die Kombination aller acht „Meinungen“ noch bessere Ergebnisse liefern könnte. Sie bauten eine Komiteemaschine: ein finales Modell, das die Ausgaben der acht eigenständigen Algorithmen entgegennimmt und einen gewichteten Durchschnitt bildet. Um zu entscheiden, wie viel Vertrauen jedem Mitglied entgegengebracht werden sollte, nutzten sie zwei Optimierungsstrategien, die von natürlichen Prozessen inspiriert sind — genetische Algorithmen und Simulated Annealing. Diese durchsuchen viele mögliche Gewichtskombinationen, um die Mischung zu finden, die die höchste Testgenauigkeit liefert. In den besten Komitee‑Konfigurationen hatten AdaBoost und ein hybrides Neuro‑Fuzzy‑System die größten Gewichte, während schwächere Modelle kleinere Korrekturen beitrugen.
Schärfere Entscheidungen für die Mine
Beide Komitee‑Versionen übertrafen die Einzelmodelle deutlich. Während die durchschnittliche Einzelmodellgenauigkeit bei etwa 88 % lag, erreichte das optimierte Komitee rund 94 % Genauigkeit, Präzision und Recall im unabhängigen Testset — eine Verbesserung um 7,28 %. Fehlklassifizierte Proben wurden verglichen mit AdaBoost allein nahezu halbiert. Für eine laufende Mine bedeutet diese Verbesserung direkt: weniger ergiebige Meter, die fälschlich als Abfall verworfen werden, und weniger unergiebiges Gestein, das zur Aufbereitung geschickt wird. Kurz: Die Studie zeigt, dass das Mischen mehrerer Machine‑Learning‑Ansätze, gelenkt durch Optimierungsalgorithmen, subtile chemische Spuren in robuste, bergwerksgerechte Entscheidungen darüber verwandeln kann, wo das echte Gold liegt.
Zitation: Gholami Vijouyeh, A., Kadkhodaie, A., Siahcheshm, K. et al. Integrated ore classification using stand-alone and hybridised machine learning algorithms. Sci Rep 16, 14625 (2026). https://doi.org/10.1038/s41598-026-42248-x
Schlüsselwörter: Erdgoldklassifizierung, Geochemie von Spurenelementen, Maschinelles Lernen im Bergbau, Ensemble‑Modelle, Bohrkernanalyse