Clear Sky Science · pl
Zintegrowana klasyfikacja rud przy użyciu samodzielnych i zhybrydyzowanych algorytmów uczenia maszynowego
Znajdowanie bogatych skał za pomocą inteligentnych komputerów
Kopalnie złota żyją lub umierają w oparciu o proste pytanie: które skały warto przewieźć do młyna, a które to tylko odpad? W wielu złożach złoto występuje łaciato, zmieniając się gwałtownie na przestrzeni zaledwie kilku metrów. Artykuł pokazuje, jak zestaw nowoczesnych narzędzi sztucznej inteligencji potrafi przesiać subtelne chemiczne wskazówki w rdzeniach odwiertów, by bardziej niezawodnie niż tradycyjne metody sortować skały na rudę, niskogatunkowy materiał i odpad.
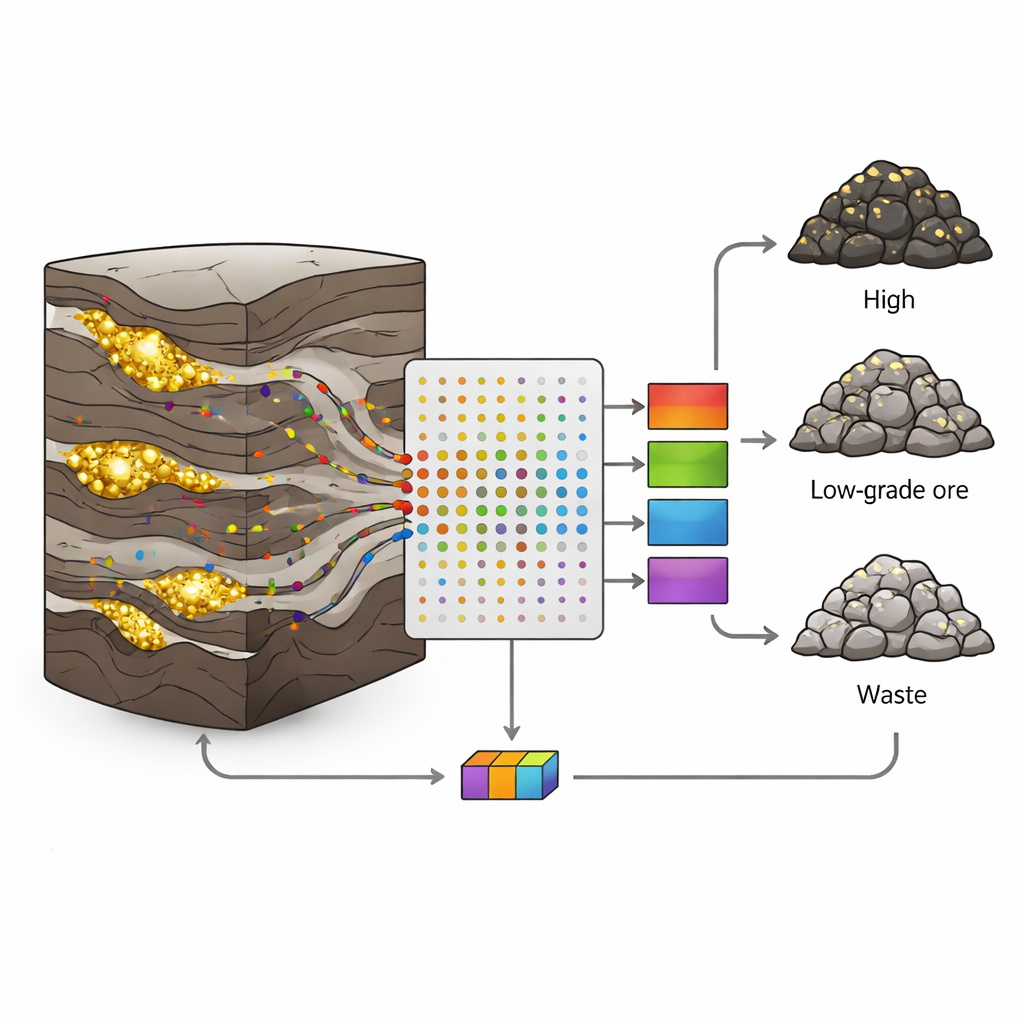
Dlaczego złoża złota są tak trudne do odczytania
W kopalni Sari-Gunay złota i polimetalicznej w zachodnim Iranie złoto występuje w wąskich, nieregularnych żyłach w obrębie złożonej mozaiki skał wulkanicznych i osadowych. Uszkodzenia tektoniczne, spękania i zmienna mineralizacja powodują, że wartości złota skaczą nagle z bogatych do jałowych na krótkich dystansach. Klasyczne podejścia geologiczne i statystyczne mają problemy z takim chaosem; często zakładają gładkie zmiany i wykorzystują tylko kilka zmiennych. Tymczasem każdy rdzeń odwiertu zawiera bogactwo dodatkowych informacji: śladowe ilości pierwiastków jak arsen, antymon czy bizmut, które przemieszczają się z płynami niosącymi złoto. Wyzwanie polega na przekształceniu tych wielu, zaszumionych pomiarów w jasne decyzje dotyczące typu skały.
Przekształcanie pierwiastków śladowych w dane uczące
Autorzy zebrali 190 próbek rdzeni z ośmiu otworów wiertniczych, z których każda reprezentowała odcinek jednego metra. Dla każdej próbki zmierzono 19 pierwiastków śladowych przy użyciu analizy ICP (indukcyjnie sprzężone plazmy), po czym przypisano próbkę do jednej z trzech klas opartych na zawartości złota: ruda (powyżej 1 grama na tonę), ruda niskogatunkowa (0,5–1 g/t) lub odpad (mniej niż 0,5 g/t). Około dwie trzecie próbek z każdej klasy wykorzystano do trenowania modeli, a pozostałą jedną trzecią zarezerwowano do testowania, jak dobrze modele rozpoznają niewidziane wcześniej dane. Taki staranny podział pomógł uniknąć powszechnej pułapki przeuczenia, w której algorytm zapamiętuje zbiór treningowy, ale zawodzi w praktyce.
Osiem różnych „opinii” od uczenia maszynowego
Aby odczytać chemiczne sygnatury, badacze zastosowali osiem typów modeli uczenia maszynowego, począwszy od sieci neuronowych i systemów rozmytych po kilka metod boostingu łączących wiele prostych drzew decyzyjnych. Każdy model uczył się, jak wzory w 19 pierwiastkach śladowych odpowiadają trzem klasom skał. Zespół automatycznie stroił kluczowe ustawienia każdego algorytmu, testując tysiące wariantów, aby zmaksymalizować trzy miary wydajności: dokładność ogólną (jak często klasa była poprawna), precyzję (jak czysta była każda przewidywana klasa) oraz czułość/odbiór (ile prawdziwych próbek rudy lub odpadu zostało poprawnie wykrytych). Spośród metod indywidualnych najlepszą równowagę zapewnił podejście oparte na wzmacnianych drzewach decyzyjnych zwane AdaBoost — poprawnie klasyfikowało niemal 90% próbek testowych i popełniało najmniej błędów wśród rudy, niskogatunkowej i odpadu.
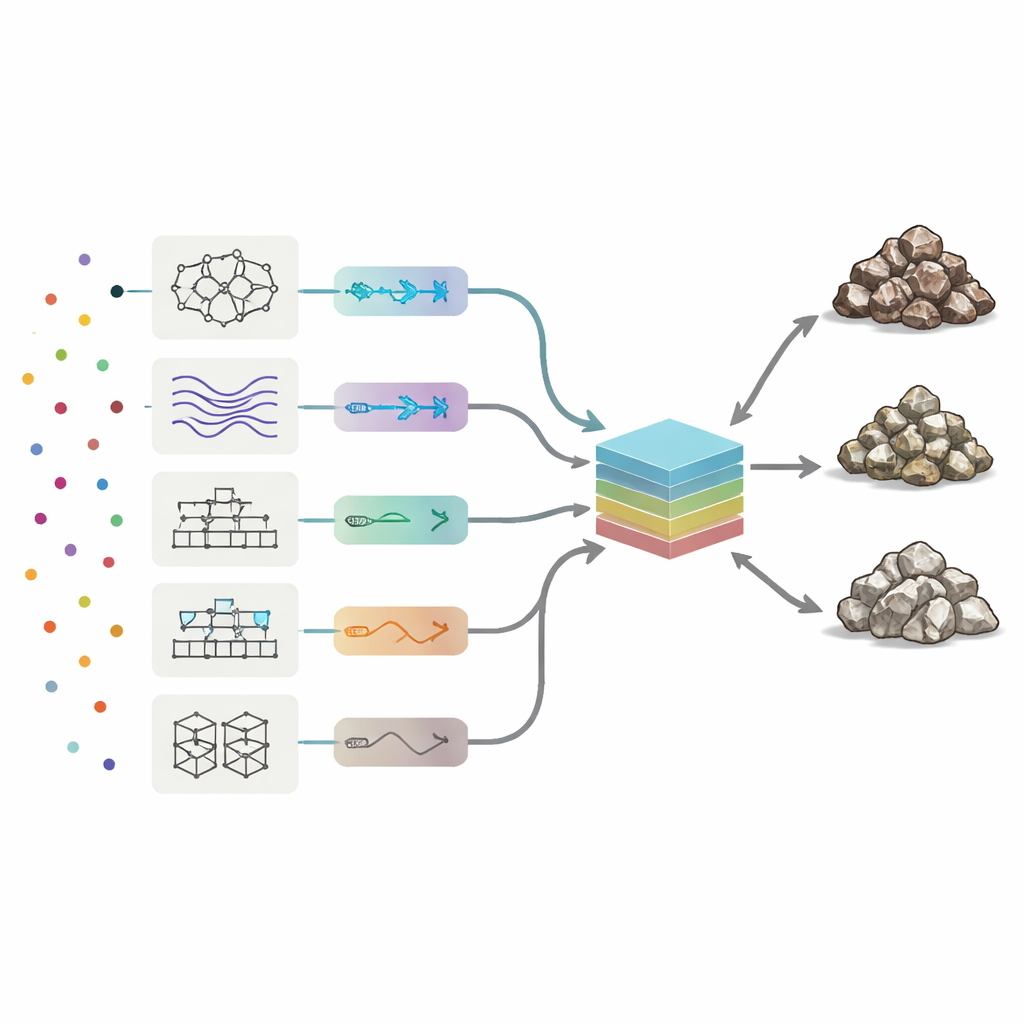
Budowanie komitetu modeli
Zamiast zatrzymać się na najlepszym wykonawcy solo, autorzy zapytali, czy połączenie wszystkich ośmiu „opinii” mogłoby dać jeszcze lepszy rezultat. Zbudowali maszynę-komitet: model końcowy, który przyjmuje wyjścia ośmiu samodzielnych algorytmów i tworzy ważoną średnią. Aby zdecydować, ile ufności przyznać każdemu członkowi, wykorzystali dwie strategie optymalizacyjne inspirowane procesami naturalnymi — algorytmy genetyczne oraz wyżarzanie symulowane. Przeszukiwały one wiele możliwych kombinacji wag, aby znaleźć mieszankę dającą najwyższą dokładność testową. W najlepszych konfiguracjach komitetu największe wagi otrzymały AdaBoost i hybrydowy system neuro‑rozmyty, podczas gdy słabsze modele wnosiły mniejsze korekty.
Bardziej precyzyjne decyzje dla kopalni
Obie wersje komitetu znacząco przewyższały modele indywidualne. Podczas gdy średnia dokładność pojedynczych modeli wynosiła około 88%, zoptymalizowany komitet osiągnął około 94% w zakresie dokładności, precyzji i czułości na niezależnym zbiorze testowym — co stanowi poprawę o 7,28%. Błędnie sklasyfikowane próbki zostały zredukowane niemal o połowę w porównaniu z samym AdaBoostem. Dla działającej kopalni taka poprawa przekłada się bezpośrednio na mniej bogatych metrów wyrzucanych jako odpad i mniej jałowej skały kierowanej do młyna. Mówiąc prosto, badanie pokazuje, że łączenie wielu podejść uczenia maszynowego, wspierane przez algorytmy optymalizacyjne, potrafi przemienić subtelne ślady chemiczne w solidne, kopalniane decyzje dotyczące lokalizacji prawdziwego złota.
Cytowanie: Gholami Vijouyeh, A., Kadkhodaie, A., Siahcheshm, K. et al. Integrated ore classification using stand-alone and hybridised machine learning algorithms. Sci Rep 16, 14625 (2026). https://doi.org/10.1038/s41598-026-42248-x
Słowa kluczowe: klasyfikacja rud złota, geochemia pierwiastków śladowych, uczenie maszynowe w górnictwie, modele zespołowe, analiza rdzeni odwiertów