Clear Sky Science · nl
Geïntegreerde ertsklassementen met zelfstandige en gehybridiseerde machine-learningalgoritmen
Rijke stenen vinden met slimme computers
Goudmijnen leven of sterven op een eenvoudige vraag: welke stenen zijn het waard om naar de verwerkingsfabriek te brengen en welke zijn slechts afval? In veel afzettingen is het goud ongelijk verdeeld en verandert het snel over slechts enkele meters. Dit artikel laat zien hoe een reeks moderne kunstmatige-intelligentie-instrumenten subtiele chemische aanwijzingen in boorkernen kan doorzoeken om stenen veel betrouwbaarder dan traditionele methoden in ertsen, laagwaardige materialen en afval te classificeren.
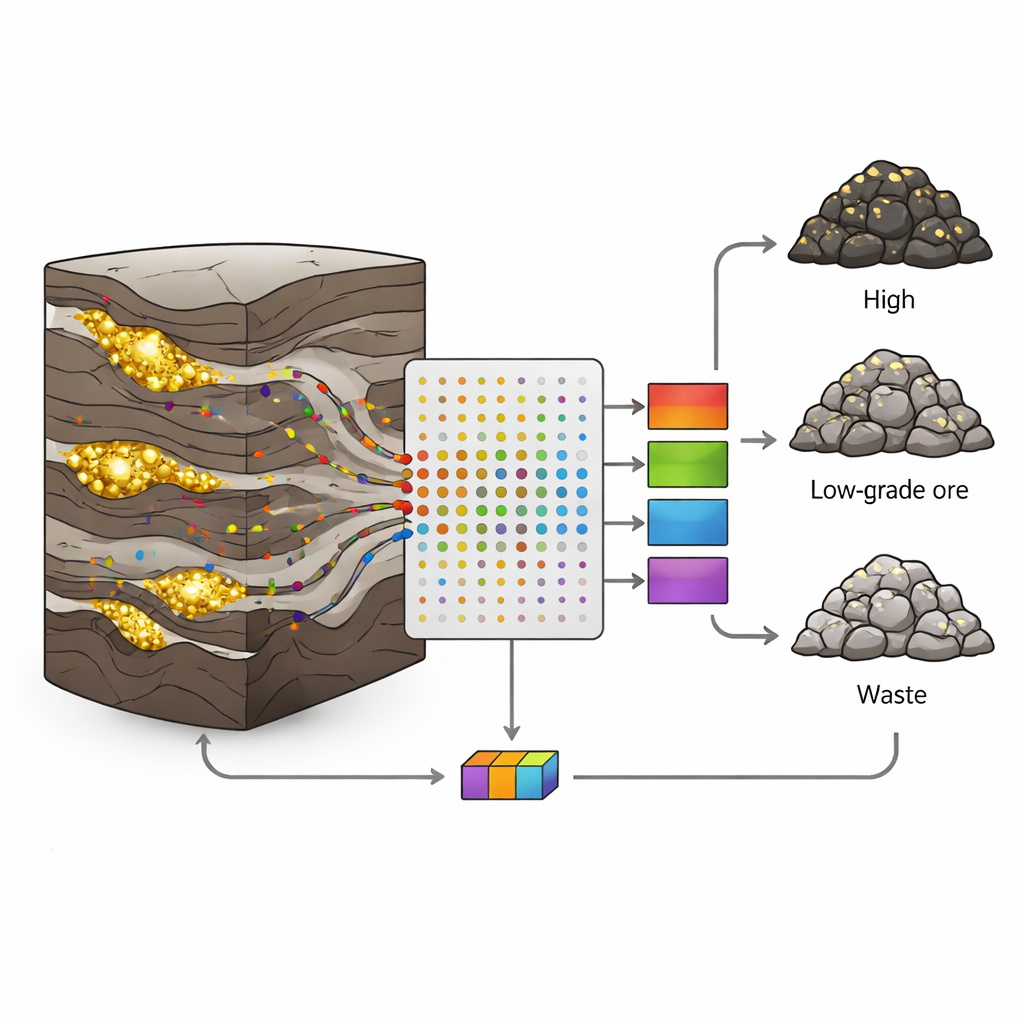
Waarom goudafzettingen zo moeilijk te lezen zijn
In de Sari-Gunay goud‑polymetaalhoudende mijn in westelijk Iran komt goud voor in smalle, onregelmatige aders binnen een complexe mix van vulkanische en sedimentaire gesteenten. Breuken, scheuren en variërende mineralisatie zorgen ervoor dat de goudgehaltes abrupt kunnen springen van rijk naar arm over korte afstanden. Klassieke geologische en statistische benaderingen worstelen met zulke wanorde; ze veronderstellen vaak geleidelijke veranderingen en gebruiken slechts een paar variabelen. Toch bevat elke boorkern een schat aan extra informatie: zeer kleine hoeveelheden elementen zoals arseen, antimoon of bismut die met de goudhoudende vloeistoffen meereizen. De uitdaging is deze veelvoud aan rumoerige metingen om te zetten in heldere beslissingen over gesteentetypen.
Sporelementen omzetten in trainingsdata
De auteurs verzamelden 190 kernmonsters uit acht boorputten, elk representatief voor een interval van één meter. Voor elk monster maten ze 19 sporelementen met inductief gekoppeld plasma (ICP)-analyse en wezen ze vervolgens elk monster toe aan een van drie klassen op basis van het goudgehalte: ertslagen (meer dan 1 gram per ton), laagwaardige ertsen (0,5–1 g/t) of afval (minder dan 0,5 g/t). Ongeveer twee derde van de monsters in elke klasse werd gebruikt om modellen te trainen en het resterende derde werd gereserveerd om te testen hoe goed die modellen ongeziene data konden herkennen. Deze zorgvuldige split hielp de veelvoorkomende valkuil van overfitting te vermijden, waarbij een algoritme de trainingsset memoriseert maar faalt in de echte wereld.
Acht verschillende “meningen” van machine learning
Om de chemische handtekeningen te lezen, zetten de onderzoekers acht typen machine-learningmodellen in, variërend van neurale netwerken en fuzzy-logicasystemen tot verschillende boostingmethoden die vele eenvoudige beslissingsbomen combineren. Elk model leerde hoe patronen in de 19 sporelementen overeenkomen met de drie gesteenteklassen. Het team stemde automatisch belangrijke instellingen voor elk algoritme af en testte duizenden varianten om drie prestatiemaatstaven te maximaliseren: algemene nauwkeurigheid (hoe vaak de klasse juist was), precisie (hoe zuiver elke voorspelde klasse was) en recall (hoeveel echte ertsen of afvalmonsters succesvol werden gevonden). Onder de individuele methoden bood een boosted decision-tree-benadering genaamd AdaBoost de beste balans; die classificeerde bijna 90% van de testmonsters correct en maakte de minste fouten over ertsen, laagwaardige en afvalmonsters heen.
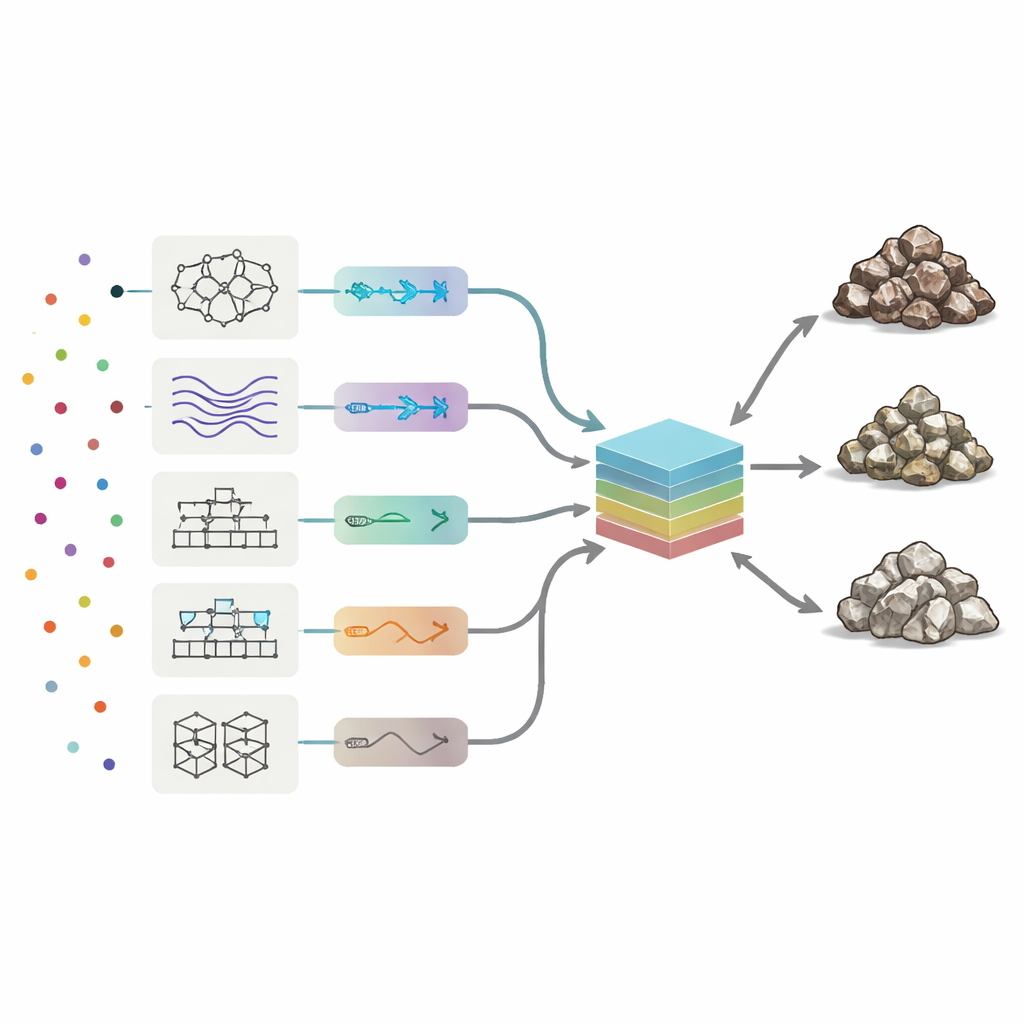
Een comité van modellen opbouwen
In plaats van te stoppen bij de beste solo-presteerder, vroegen de auteurs zich af of het combineren van alle acht “meningen” nog beter kon presteren. Ze bouwden een commissie‑machine: een eindmodel dat de outputs van de acht zelfstandige algoritmen neemt en een gewogen gemiddelde vormt. Om te bepalen hoeveel vertrouwen aan elk lid toe te kennen, gebruikten ze twee optimalisatiestrategieën geïnspireerd door natuurlijke processen—genetische algoritmen en gesimuleerde annealing. Deze zoeken door vele mogelijke gewichtcombinaties om de mix te vinden die de hoogste testnauwkeurigheid geeft. In de beste commissieconfiguraties droegen AdaBoost en een hybride neuro‑fuzzy systeem de grootste gewichten, terwijl zwakkere modellen kleinere correcties bijdroegen.
Scherpere beslissingen voor de mijn
Beide commissievarianten presteerden aanzienlijk beter dan de individuele modellen. Terwijl de gemiddelde zelfstandige nauwkeurigheid ongeveer 88% was, bereikte de geoptimaliseerde commissie ongeveer 94% voor nauwkeurigheid, precisie en recall op de onafhankelijke testset—een verbetering van 7,28%. Verkeerd geclassificeerde monsters werden bijna gehalveerd vergeleken met AdaBoost alleen. Voor een actieve mijn vertaalt die verbetering zich direct naar minder rijke meters die als afval worden weggegooid en minder arm gesteente dat naar de verwerkingsfabriek wordt gestuurd. In eenvoudige termen toont de studie aan dat het mengen van meerdere machine-learningbenaderingen, geleid door optimalisatiealgoritmen, subtiele chemische sporen kan omzetten in robuuste, mijnschaalbeslissingen over waar het echte goud ligt.
Bronvermelding: Gholami Vijouyeh, A., Kadkhodaie, A., Siahcheshm, K. et al. Integrated ore classification using stand-alone and hybridised machine learning algorithms. Sci Rep 16, 14625 (2026). https://doi.org/10.1038/s41598-026-42248-x
Trefwoorden: klassificatie van gouden ertsen, spoor-element geochemie, machine learning in de mijnbouw, ensemblemodellen, analyse van boorkernen