Clear Sky Science · en
Integrated ore classification using stand-alone and hybridised machine learning algorithms
Finding Rich Rocks with Smart Computers
Gold mines live or die on a simple question: which rocks are worth hauling to the mill, and which are just waste? In many deposits the gold is patchy, changing quickly over just a few meters. This paper shows how a suite of modern artificial‑intelligence tools can sift through subtle chemical clues in drill cores to sort rocks into ore, low‑grade material, and waste far more reliably than traditional methods.
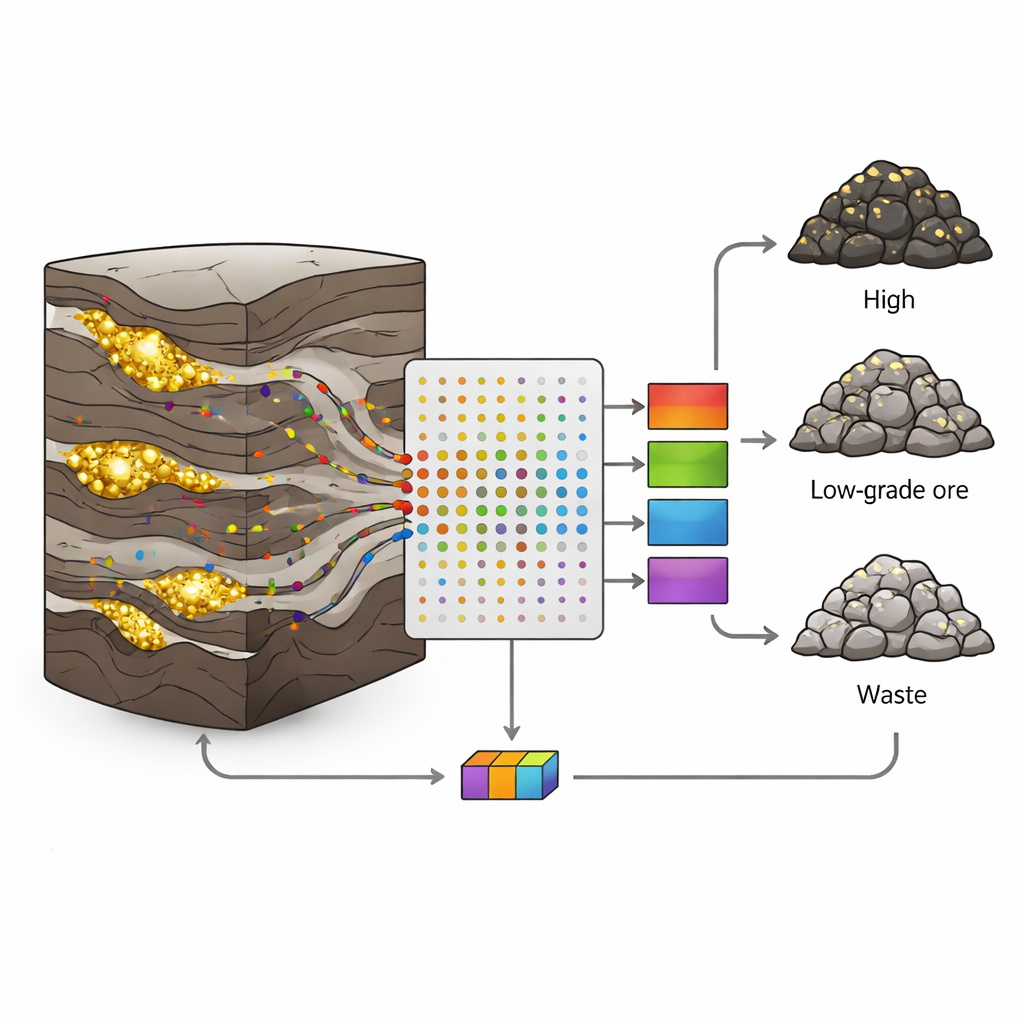
Why Gold Deposits Are So Hard to Read
In the Sari-Gunay gold–polymetallic mine in western Iran, gold occurs in narrow, irregular veins within a complex mix of volcanic and sedimentary rocks. Faults, fractures, and changing mineralisation make gold grades jump abruptly from rich to barren over short distances. Classic geological and statistical approaches struggle with such disorder; they often assume smooth changes and use only a few variables. Yet every drill core holds a wealth of extra information: tiny amounts of elements like arsenic, antimony, or bismuth that travel with the gold-bearing fluids. The challenge is to turn these many, noisy measurements into clear decisions about rock type.
Turning Trace Elements into Training Data
The authors collected 190 core samples from eight drill holes, each representing a one‑meter interval. For every sample they measured 19 trace elements using inductively coupled plasma (ICP) analysis, then assigned each sample to one of three classes based on its gold content: ore (more than 1 gram per tonne), low‑grade ore (0.5–1 g/t), or waste (less than 0.5 g/t). About two‑thirds of the samples in each class were used to train models, and the remaining third was reserved to test how well those models could recognise unseen data. This careful split helped avoid the common pitfall of overfitting, where an algorithm memorises the training set but fails in the real world.
Eight Different “Opinions” from Machine Learning
To read the chemical signatures, the researchers deployed eight types of machine learning models, ranging from neural networks and fuzzy‑logic systems to several boosting methods that combine many simple decision trees. Each model learned how patterns in the 19 trace elements corresponded to the three rock classes. The team automatically tuned key settings for every algorithm, testing thousands of variants to maximise three measures of performance: overall accuracy (how often the class was right), precision (how clean each predicted class was), and recall (how many true ore or waste samples were successfully found). Among the individual methods, a boosted decision‑tree approach called AdaBoost gave the best balance, correctly classifying nearly 90% of test samples and making the fewest mistakes across ore, low‑grade, and waste.
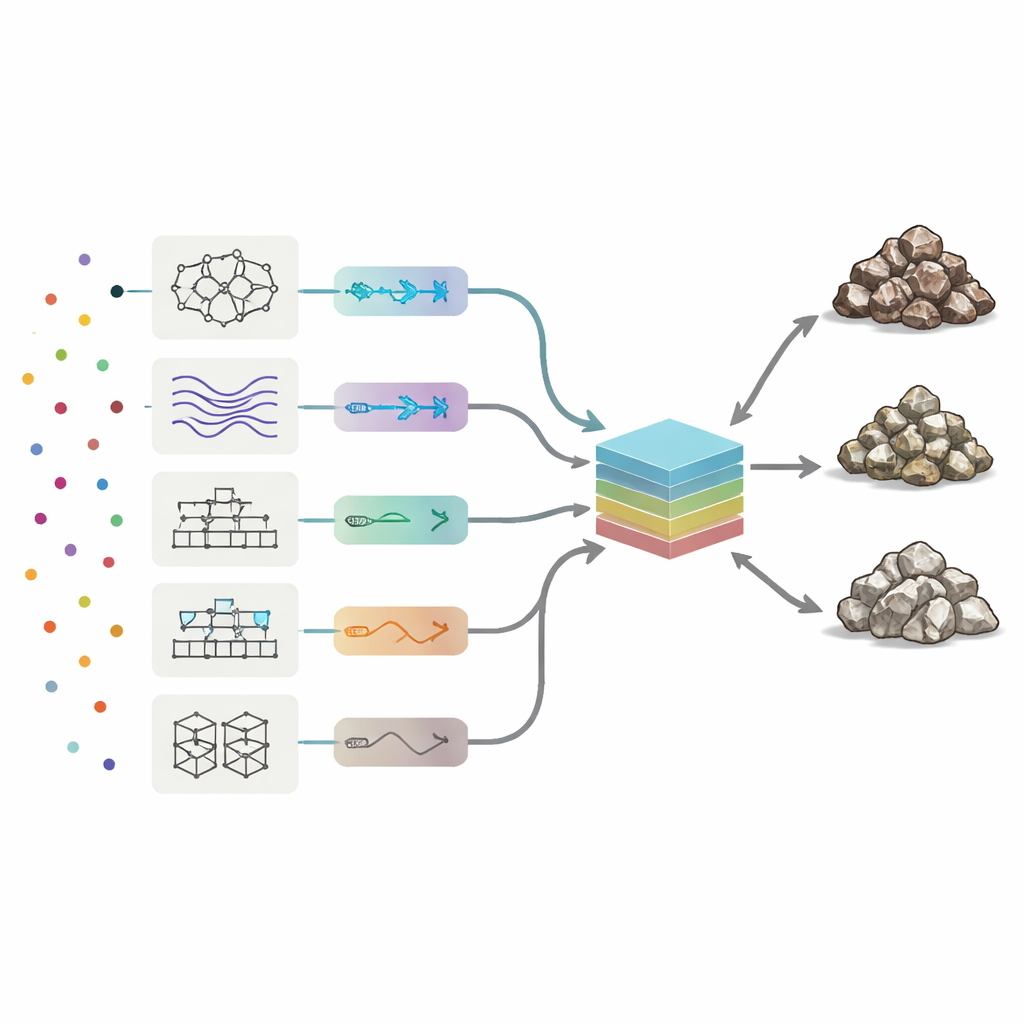
Building a Committee of Models
Instead of stopping at the best solo performer, the authors asked whether combining all eight “opinions” could do even better. They built a committee machine: a final model that takes the outputs of the eight stand‑alone algorithms and forms a weighted average. To decide how much trust to place in each member, they used two optimisation strategies inspired by natural processes—genetic algorithms and simulated annealing. These search through many possible weight combinations to find the mix that gives the highest test accuracy. In the best committee configurations, AdaBoost and a hybrid neuro‑fuzzy system carried the largest weights, while weaker models contributed smaller corrections.
Sharper Decisions for the Mine
Both committee versions significantly outperformed the individual models. While the average stand‑alone accuracy was about 88%, the optimised committee reached roughly 94% accuracy, precision, and recall on the independent test set—a 7.28% improvement. Misclassified samples were cut nearly in half compared with AdaBoost alone. For a working mine, that improvement translates directly into fewer rich meters thrown away as waste and less barren rock sent to the mill. In straightforward terms, the study shows that blending multiple machine‑learning approaches, guided by optimisation algorithms, can turn subtle chemical traces into robust, mine‑scale decisions about where the real gold lies.
Citation: Gholami Vijouyeh, A., Kadkhodaie, A., Siahcheshm, K. et al. Integrated ore classification using stand-alone and hybridised machine learning algorithms. Sci Rep 16, 14625 (2026). https://doi.org/10.1038/s41598-026-42248-x
Keywords: gold ore classification, trace element geochemistry, machine learning in mining, ensemble models, drill core analysis