Clear Sky Science · fr
Classification intégrée du minerai utilisant des algorithmes d’apprentissage automatique autonomes et hybrides
Trouver les roches riches grâce aux ordinateurs intelligents
La viabilité d’une mine d’or se joue sur une question simple : quelles roches valent la peine d’être transportées à l’usine et lesquelles sont du simple stérile ? Dans de nombreux gisements, l’or est distribué de manière hétérogène, changeant rapidement sur seulement quelques mètres. Cet article montre comment un ensemble d’outils d’intelligence artificielle modernes peut trier, à partir d’indices chimiques subtils dans les carottes de forage, les roches en minerai, matière à faible teneur et stérile, beaucoup plus fiablement que les méthodes traditionnelles.
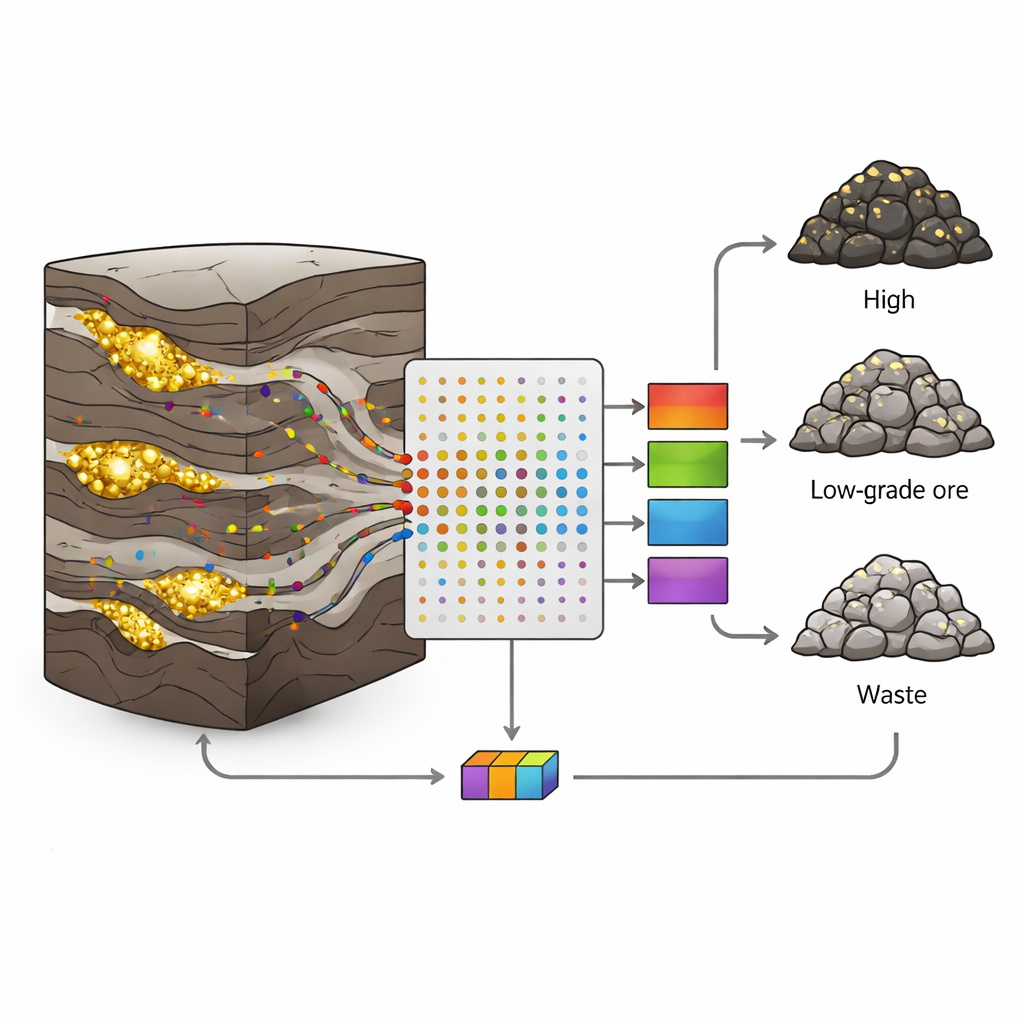
Pourquoi les gisements aurifères sont si difficiles à lire
Dans la mine d’or–polymétallique de Sari-Gunay, dans l’ouest de l’Iran, l’or se trouve dans de veines étroites et irrégulières au sein d’un mélange complexe de roches volcaniques et sédimentaires. Failles, fractures et variations de minéralisation font que les teneurs en or passent brusquement du riche au pauvre sur de courtes distances. Les approches géologiques et statistiques classiques peinent face à un tel désordre ; elles supposent souvent des variations lissées et n’utilisent que quelques variables. Pourtant, chaque carotte de forage recèle une richesse d’informations supplémentaires : de très faibles quantités d’éléments comme l’arsenic, l’antimoine ou le bismuth qui accompagnent les fluides enrichissant en or. Le défi consiste à transformer ces nombreuses mesures bruitées en décisions claires sur le type de roche.
Transformer les éléments traces en données d’entraînement
Les auteurs ont prélevé 190 échantillons de carottes provenant de huit forages, chaque échantillon représentant un intervalle d’un mètre. Pour chaque échantillon, ils ont mesuré 19 éléments traces par analyse par plasma à couplage inductif (ICP), puis ont affecté chaque échantillon à l’une des trois classes selon sa teneur en or : minerai (plus de 1 gramme par tonne), minerai à faible teneur (0,5–1 g/t) ou stérile (moins de 0,5 g/t). Environ les deux tiers des échantillons de chaque classe ont servi à entraîner les modèles, et le tiers restant a été réservé pour tester la capacité des modèles à reconnaître des données inédites. Cette séparation soigneuse a aidé à éviter le piège courant du surapprentissage, où un algorithme mémorise l’ensemble d’entraînement mais échoue dans le monde réel.
Huit « opinions » différentes d’apprentissage automatique
Pour interpréter les signatures chimiques, les chercheurs ont déployé huit types de modèles d’apprentissage automatique, allant des réseaux neuronaux et systèmes flous à plusieurs méthodes de boosting qui combinent de nombreux arbres de décision simples. Chaque modèle a appris comment les motifs des 19 éléments traces correspondaient aux trois classes de roche. L’équipe a automatiquement réglé les paramètres clés de chaque algorithme, testant des milliers de variantes pour maximiser trois mesures de performance : la précision globale (à quelle fréquence la classe était correcte), la précision (la pureté de chaque classe prédite) et le rappel (combien d’échantillons réellement minerai ou stériles ont été correctement trouvés). Parmi les méthodes individuelles, une approche d’arbres de décision boostés appelée AdaBoost a offert le meilleur équilibre, classant correctement près de 90 % des échantillons de test et commettant le moins d’erreurs entre minerai, faible teneur et stérile.
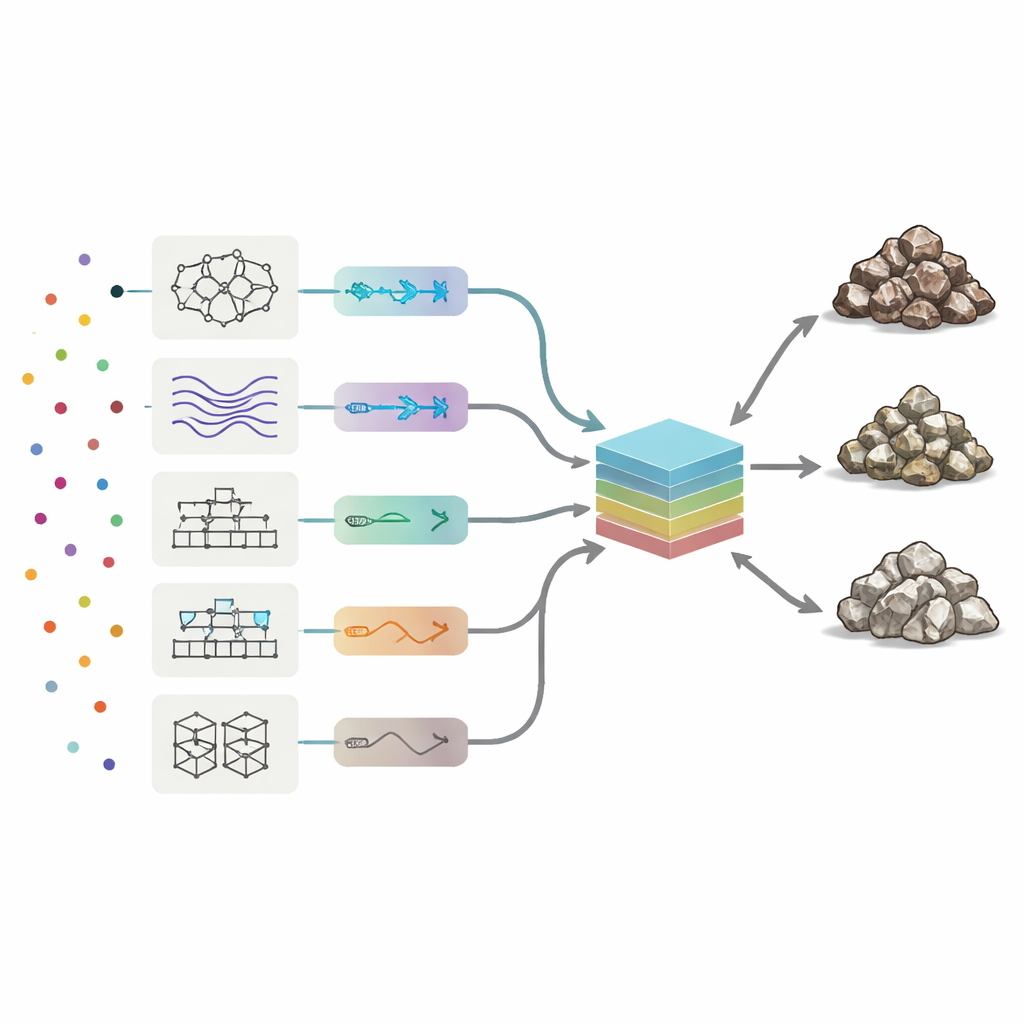
Construire un comité de modèles
Plutôt que de s’arrêter au meilleur performeur isolé, les auteurs se sont demandé si la combinaison des huit « opinions » pouvait faire encore mieux. Ils ont construit une machine comité : un modèle final qui prend les sorties des huit algorithmes autonomes et forme une moyenne pondérée. Pour décider de la confiance à accorder à chaque membre, ils ont utilisé deux stratégies d’optimisation inspirées de processus naturels — des algorithmes génétiques et le recuit simulé. Ces méthodes explorent de nombreuses combinaisons possibles de poids pour trouver le mélange qui donne la meilleure précision sur le jeu de test. Dans les meilleures configurations du comité, AdaBoost et un système neuro-flou hybride portaient les poids les plus importants, tandis que les modèles plus faibles apportaient de petites corrections.
Des décisions plus nettes pour la mine
Les deux versions du comité ont nettement surpassé les modèles individuels. Alors que la précision moyenne des modèles autonomes était d’environ 88 %, le comité optimisé a atteint environ 94 % de précision, précision (precision) et rappel sur l’ensemble de test indépendant — une amélioration de 7,28 %. Les échantillons mal classés ont été réduits de près de moitié par rapport à AdaBoost seul. Pour une mine en exploitation, cette amélioration se traduit directement par moins de mètres riches jetés comme stérile et moins de roche pauvre envoyée à l’usine. En termes simples, l’étude montre que le mélange de plusieurs approches d’apprentissage automatique, guidé par des algorithmes d’optimisation, peut transformer des traces chimiques subtiles en décisions robustes à l’échelle de la mine sur l’emplacement réel de l’or.
Citation: Gholami Vijouyeh, A., Kadkhodaie, A., Siahcheshm, K. et al. Integrated ore classification using stand-alone and hybridised machine learning algorithms. Sci Rep 16, 14625 (2026). https://doi.org/10.1038/s41598-026-42248-x
Mots-clés: classification du minerai aurifère, géochimie des éléments traces, apprentissage automatique dans les mines, modèles d’ensemble, analyse de carottes de forage