Clear Sky Science · pt
Classificação integrada de minério usando algoritmos de aprendizado de máquina autônomos e hibridizados
Encontrando Rochas Ricas com Computadores Inteligentes
As minas de ouro vivem ou morrem por uma pergunta simples: quais rochas valem a pena levar até a planta e quais são apenas rejeito? Em muitos depósitos o ouro é descontínuo, variando rapidamente em poucos metros. Este artigo mostra como um conjunto de ferramentas modernas de inteligência artificial pode peneirar pistas químicas sutis em testemunhos de sondagem para classificar rochas em minério, material de baixo teor e rejeito de forma muito mais confiável do que métodos tradicionais.
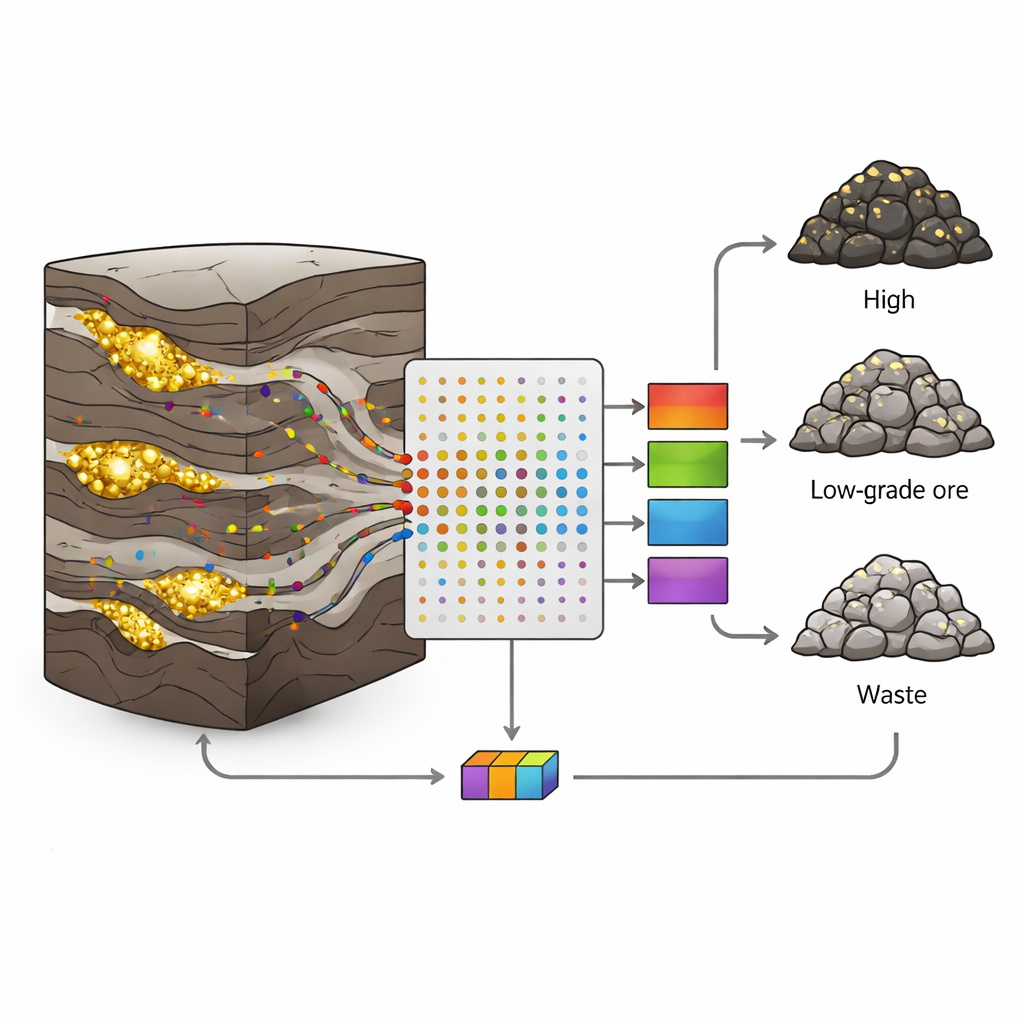
Por que os Depósitos de Ouro São Tão Difíceis de Interpretar
No minério de ouro e polimetálico Sari-Gunay, no oeste do Irã, o ouro ocorre em veios estreitos e irregulares dentro de uma mistura complexa de rochas vulcânicas e sedimentares. Falhas, fraturas e variações na mineralização fazem com que os teores de ouro saltem abruptamente de ricos para estéreis em curtas distâncias. Abordagens geológicas e estatísticas clássicas têm dificuldade com essa desordem; frequentemente assumem variações suaves e usam apenas poucas variáveis. No entanto, cada testemunho de sondagem guarda uma riqueza de informações adicionais: quantidades minúsculas de elementos como arsênio, antimônio ou bismuto que se movimentam com os fluidos portadores de ouro. O desafio é transformar essas muitas medições ruidosas em decisões claras sobre o tipo de rocha.
Transformando Elementos-traço em Dados de Treinamento
Os autores coletaram 190 amostras de testemunho de oito furos de sondagem, cada uma representando um intervalo de um metro. Para cada amostra mediram 19 elementos-traço usando análise por plasma indutivamente acoplado (ICP), e em seguida atribuíram cada amostra a uma das três classes com base no teor de ouro: minério (mais de 1 grama por tonelada), minério de baixo teor (0,5–1 g/t) ou rejeito (menos de 0,5 g/t). Cerca de dois terços das amostras de cada classe foram usados para treinar os modelos, e o terço restante foi reservado para testar o desempenho em dados não vistos. Essa divisão cuidadosa ajudou a evitar o erro comum de sobreajuste, quando um algoritmo memoriza o conjunto de treinamento mas falha no mundo real.
Oito “Opiniões” Diferentes do Aprendizado de Máquina
Para ler as assinaturas químicas, os pesquisadores empregaram oito tipos de modelos de aprendizado de máquina, variando desde redes neurais e sistemas de lógica fuzzy até vários métodos de boosting que combinam muitas árvores de decisão simples. Cada modelo aprendeu como padrões nos 19 elementos-traço correspondiam às três classes de rocha. A equipe ajustou automaticamente parâmetros chave de cada algoritmo, testando milhares de variantes para maximizar três medidas de desempenho: acurácia geral (com que frequência a classe estava correta), precisão (quão limpa era cada classe prevista) e recall (quantas amostras verdadeiras de minério ou rejeito foram corretamente encontradas). Entre os métodos individuais, uma abordagem de árvore de decisão com boosting chamada AdaBoost apresentou o melhor equilíbrio, classificando corretamente quase 90% das amostras de teste e cometendo menos erros entre minério, baixo teor e rejeito.
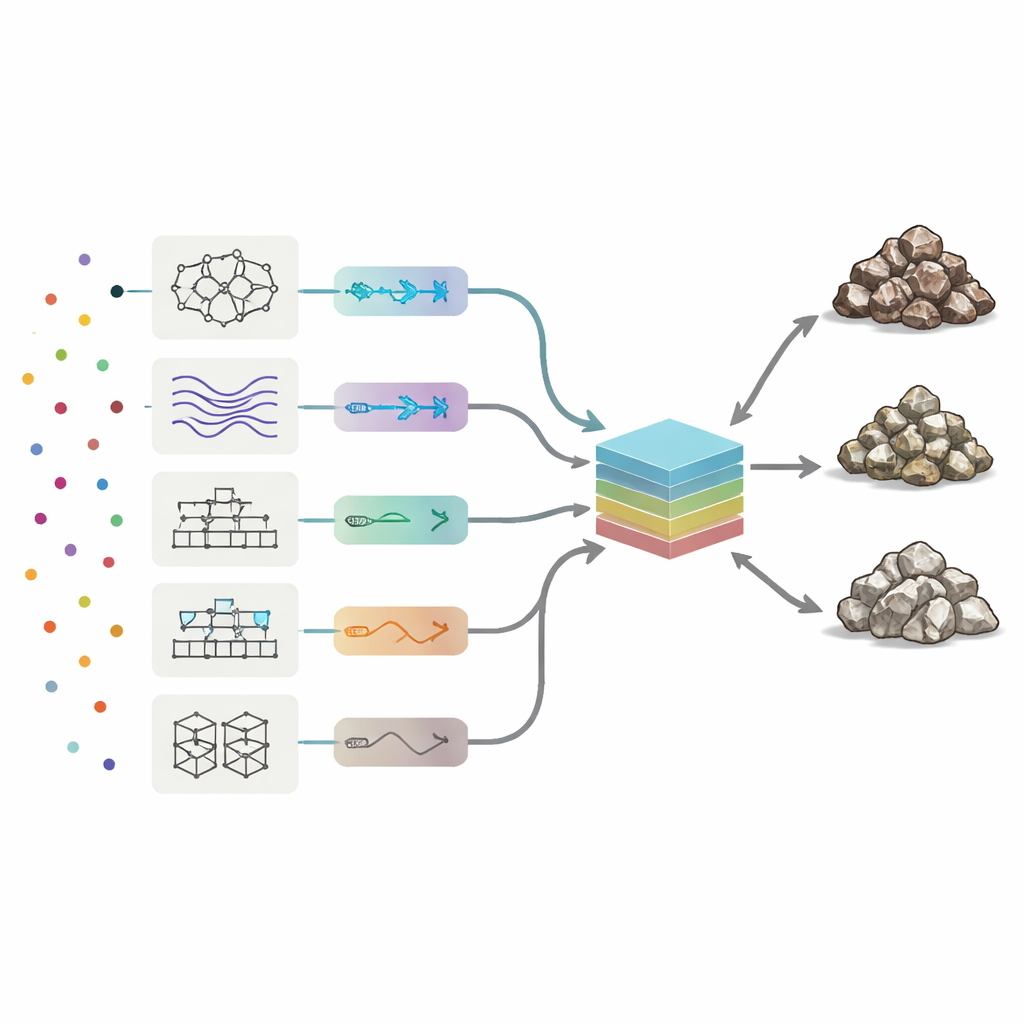
Construindo um Comitê de Modelos
Em vez de parar no melhor desempenho individual, os autores investigaram se combinar as oito “opiniões” poderia melhorar ainda mais os resultados. Eles construíram uma máquina comitê: um modelo final que recebe as saídas dos oito algoritmos autônomos e forma uma média ponderada. Para decidir quanto confiar em cada membro, usaram duas estratégias de otimização inspiradas em processos naturais — algoritmos genéticos e recozimento simulado. Essas estratégias procuram entre muitas combinações possíveis de pesos para encontrar a mistura que oferece a maior acurácia de teste. Nas melhores configurações do comitê, AdaBoost e um sistema neuro-fuzzy híbrido receberam os maiores pesos, enquanto modelos mais fracos contribuíram com correções menores.
Decisões Mais Precisos para a Mina
Ambas as versões do comitê superaram significativamente os modelos individuais. Enquanto a acurácia média dos modelos isolados ficou em torno de 88%, o comitê otimizado alcançou aproximadamente 94% de acurácia, precisão e recall no conjunto de teste independente — uma melhoria de 7,28%. As amostras classificadas incorretamente foram quase reduzidas pela metade em comparação com o AdaBoost sozinho. Para uma mina em operação, essa melhoria se traduz diretamente em menos metros ricos jogados fora como rejeito e menos rocha estéril enviada à planta. Em termos simples, o estudo mostra que combinar múltiplas abordagens de aprendizado de máquina, guiadas por algoritmos de otimização, pode transformar traços químicos sutis em decisões robustas em escala de mina sobre onde o ouro real está localizado.
Citação: Gholami Vijouyeh, A., Kadkhodaie, A., Siahcheshm, K. et al. Integrated ore classification using stand-alone and hybridised machine learning algorithms. Sci Rep 16, 14625 (2026). https://doi.org/10.1038/s41598-026-42248-x
Palavras-chave: classificação de minério de ouro, geoquímica de elementos-traço, aprendizado de máquina na mineração, modelos ensemble, análise de testemunho de sondagem