Clear Sky Science · tr
Tek başına ve hibrit makine öğrenmesi algoritmaları kullanılarak entegre cevher sınıflandırması
Zengin Kayaçları Akıllı Bilgisayarlarla Bulmak
Altın madenleri basit bir soruya göre yaşar veya ölür: hangi kayaçlar değirmene taşınmaya değerdir, hangileri sadece atıktır? Birçok yatakta altın yamalıdır, sadece birkaç metre içinde hızla değişir. Bu makale, modern yapay zeka araçlarının bir demetinin sondaj kütüklerindeki ince kimyasal ipuçlarını nasıl ellediğini ve kayaçları cevher, düşük tenörlü malzeme ve atık olarak geleneksel yöntemlerden çok daha güvenilir şekilde sınıflandırabildiğini gösteriyor.
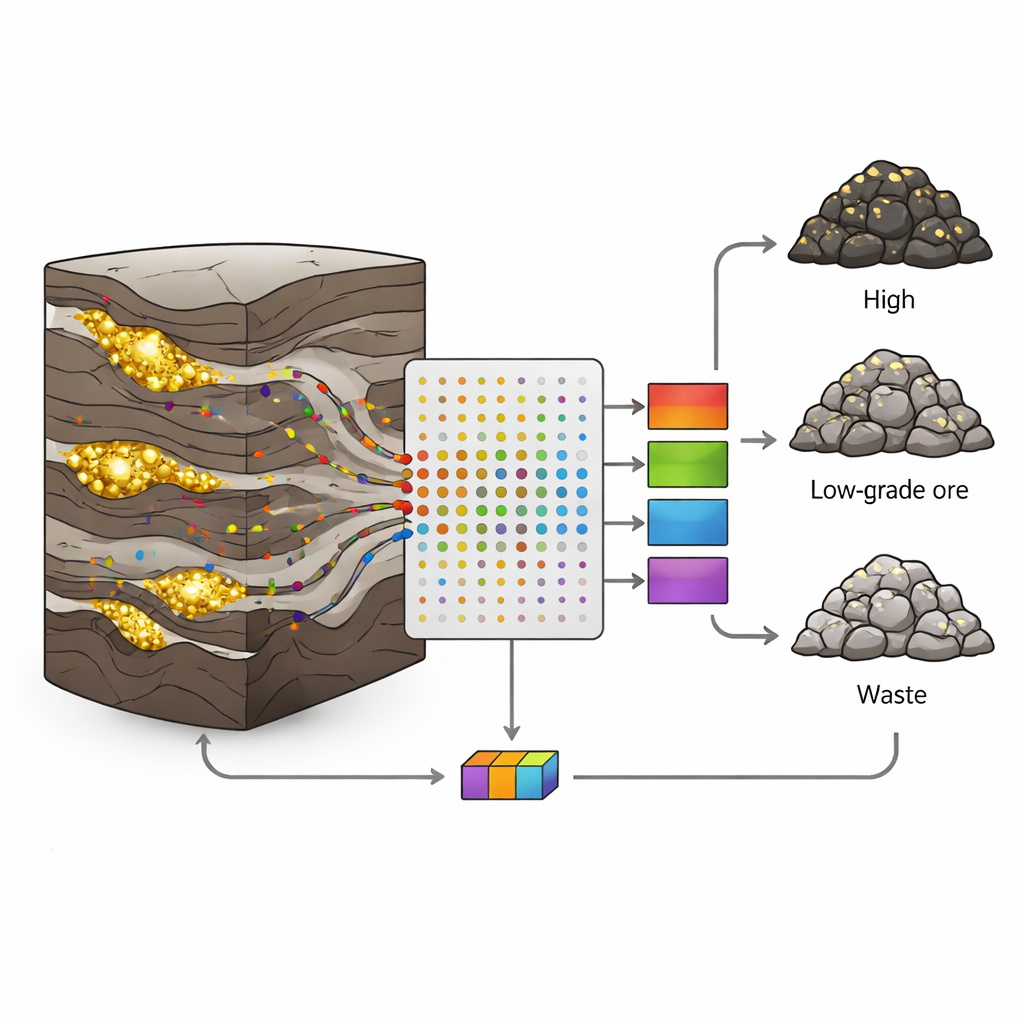
Altın Yataklarını Okumanın Neden Bu Kadar Zor Olduğu
İran’ın batısındaki Sari‑Gunay altın‑polimetalik madeninde altın, volkanik ve sedimanter kayaçların karmaşık karışımı içinde dar, düzensiz damarlar halinde bulunur. Faylar, kırıklar ve değişen mineralizasyon, altın tenörlerinin kısa mesafelerde zenginlikten verimsize ani sıçramasına neden olur. Klasik jeolojik ve istatistiksel yaklaşımlar bu tür düzensizlikle zorlanır; genellikle pürüzsüz değişimleri varsayar ve yalnızca birkaç değişken kullanır. Oysa her sondaj kütüğü çok daha fazla bilgi taşır: arsenik, antimuan veya bizmut gibi altın taşıyan sıvılarla birlikte hareket eden çok küçük miktardaki elementler. Zorluk, bu çok sayıda ve gürültülü ölçümü kayaç tipi hakkında net kararlara dönüştürmektir.
İz Elementleri Eğitim Verisine Dönüştürmek
Yazarlar, her biri bir metrelik aralığı temsil eden sekiz sondaj deliğinden 190 adet kütük örneği topladı. Her örnek için indüktif eşleştirilmiş plazma (ICP) analizi ile 19 iz elementi ölçtüler ve ardından her örneği altın içeriğine göre üç sınıftan birine atadılar: cevher (ton başına 1 gramdan fazla), düşük tenörlü cevher (0,5–1 g/t) veya atık (0,5 g/t’den az). Her sınıftaki örneklerin yaklaşık üçte ikisi modelleri eğitmek için, kalan üçte biri ise modellerin görülmemiş verileri ne kadar iyi tanıyabildiğini test etmek için ayrıldı. Bu dikkatli bölme, bir algoritmanın eğitim setini ezberlemesi ama gerçek dünyada başarısız olmasıyla sonuçlanan aşırı öğrenme (overfitting) tuzağını önlemeye yardımcı oldu.
Makine Öğrenmesinden Sekiz Farklı “Görüş”
Kimyasal imzaları okumak için araştırmacılar, sinir ağları ve bulanık mantık sistemlerinden birçok basit karar ağacını birleştiren çeşitli boosting yöntemlerine kadar sekiz tür makine öğrenmesi modeli kullandı. Her model, 19 iz elementteki desenlerin üç kayaç sınıfıyla nasıl ilişkili olduğunu öğrendi. Ekip, her algoritma için binlerce varyantı test ederek anahtar ayarları otomatik olarak ayarladı ve üç performans ölçüsünü maksimize etti: genel doğruluk (sınıfın ne sıklıkla doğru olduğu), keskinlik/precision (öngörülen her sınıfın ne kadar saf olduğu) ve duyarlılık/recall (gerçek cevher veya atık örneklerinin ne kadarının başarıyla bulunduğu). Bireysel yöntemler arasında AdaBoost adındaki bir boosted karar ağacı yaklaşımı en iyi dengeyi sağladı; test örneklerinin neredeyse %90’ını doğru sınıflandırdı ve cevher, düşük tenör ve atık arasındaki hataları en aza indirdi.
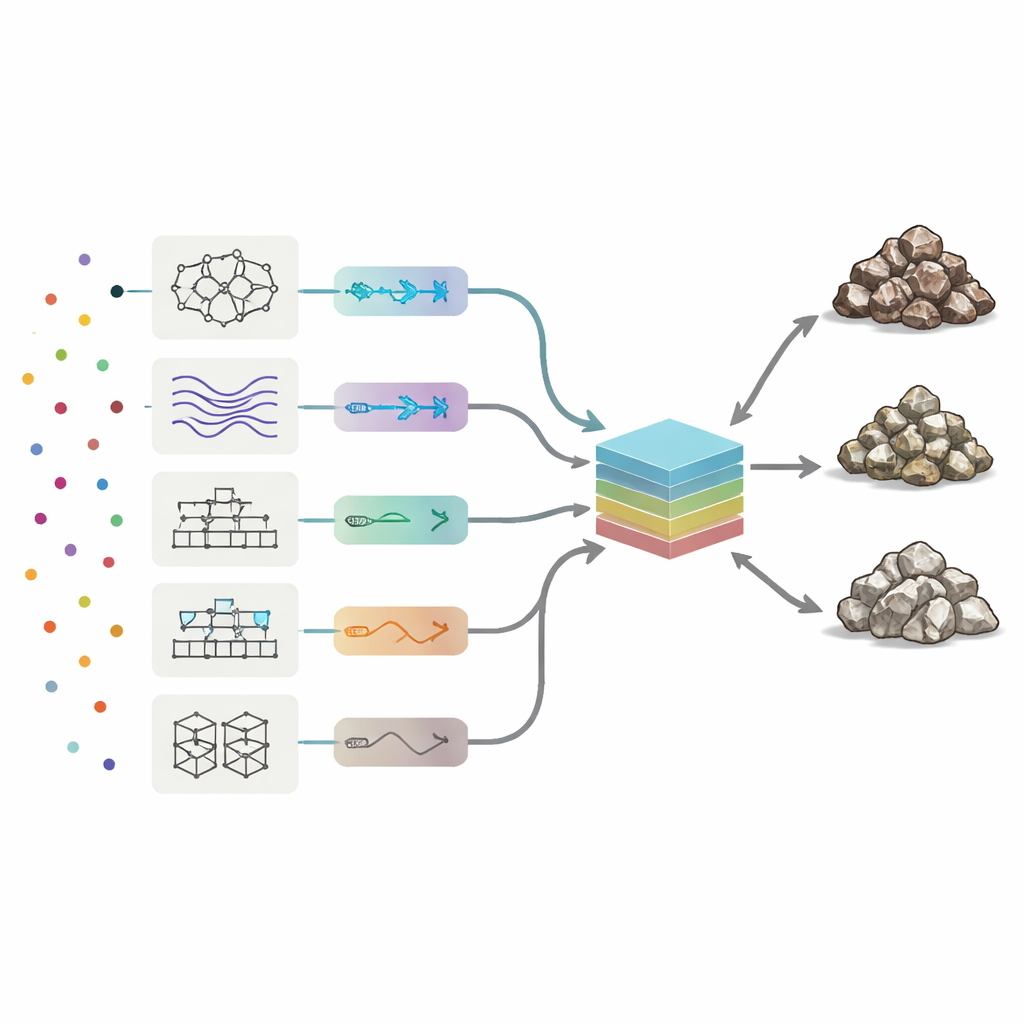
Modellerden Bir Komite Kurmak
En iyi tek başına performans gösterenle yetinmek yerine, yazarlar sekiz “görüşün” tümünü birleştirmenin daha iyi yapıp yapamayacağını sordular. Sekiz bağımsız algoritmanın çıktısını alan ve ağırlıklı ortalama oluşturan bir nihai model —komite makinesi— kurdular. Her üyenin ne kadar güvenilir olduğuna karar vermek için genetik algoritmalar ve benzetimli tavlama (simulated annealing) gibi doğal süreçlerden esinlenen iki optimizasyon stratejisi kullandılar. Bu yöntemler, en yüksek test doğruluğunu veren ağırlık kombinasyonunu bulmak için birçok olası ağırlık düzenini tarar. En iyi komite konfigürasyonlarında AdaBoost ve hibrit bir nöro‑bulanık sistem en büyük ağırlıkları taşırken, daha zayıf modeller daha küçük düzeltmeler sağladı.
Maden İçin Daha Keskin Kararlar
Her iki komite versiyonu da bireysel modelleri önemli ölçüde geride bıraktı. Ortalama tek başına doğruluk yaklaşık %88 iken, optimize edilmiş komite bağımsız test setinde yaklaşık %94 doğruluk, keskinlik ve duyarlılığa ulaştı—%7,28’lik bir iyileşme. Yanlış sınıflandırılan örnekler, yalnızca AdaBoost’a kıyasla neredeyse yarı yarıya azaldı. Çalışan bir maden için bu iyileşme, doğrudan atık olarak atılan zengin metrelerin daha az olmasına ve değirmene gönderilen verimsiz kaya miktarının azalmasına dönüşür. Açıkça söylemek gerekirse, çalışma, optimizasyon algoritmaları ile yönlendirilen birden çok makine öğrenmesi yaklaşımının harmanlanmasının, ince kimyasal izleri madencilik ölçeğinde sağlam kararlara dönüştürebileceğini gösteriyor: gerçek altının nerede olduğu konusunda.
Atıf: Gholami Vijouyeh, A., Kadkhodaie, A., Siahcheshm, K. et al. Integrated ore classification using stand-alone and hybridised machine learning algorithms. Sci Rep 16, 14625 (2026). https://doi.org/10.1038/s41598-026-42248-x
Anahtar kelimeler: altın cevheri sınıflandırması, iz element jeokimyası, madencilikte makine öğrenmesi, topluluk (ensemble) modeller, kuyu örneklemesi analizi