Clear Sky Science · zh
可解释的机器生成音乐检测与早期系统评估
这对音乐爱好者和创作者为何重要
人工智能现在可以在几秒钟内创作出令人信服的歌曲。这对创作而言令人兴奋,但对关心原创性和公平署名的音乐人、唱片公司和听众来说也令人担忧。本研究提出了一个简单却紧迫的问题:我们能否可靠地判断一段音乐是由人类还是由机器创作的,并且能否理解这些检测系统如何做出决定?
识别 AI 制作歌曲的挑战
机器生成的音乐已被用于背景配乐、歌曲创作辅助,甚至治疗。然而,同样的工具也可能充斥流媒体平台以低成本产出的曲目,模糊作者身份并削弱人类作品的价值。此前针对伪造音频的研究主要集中在语音或狭窄的音乐场景,且常依赖未公开的模型或一次性的测试。作者认为,该领域缺乏清晰、系统的方法比较,尤其缺少能解释检测器为何将一首曲目判定为真实或伪造的研究。他们的目标是建立这样一个早期且全面的基准。
研究人员如何测试检测器
为公平比较不同方法,作者在一个名为 FakeMusicCaps 的大型开放数据集上评估了十类常见模型,该数据集混合了数千段人类创作的短音乐片段与由多种文本到音乐系统生成的片段。所有音频都被转换为梅尔谱图(Mel spectrogram),这种声音的可视化表示在现代音频 AI 中广泛使用,并且每个模型看到的输入完全相同。候选模型包括传统机器学习、几类深度神经网络、基于 Transformer 的系统以及为跟踪长序列而设计的新型状态空间模型。随后,团队将训练好的检测器在第二个更困难的数据集 M6 上进行了测试,该数据集包含更长、更具多样性的歌曲,以检验模型在训练环境之外的泛化能力。
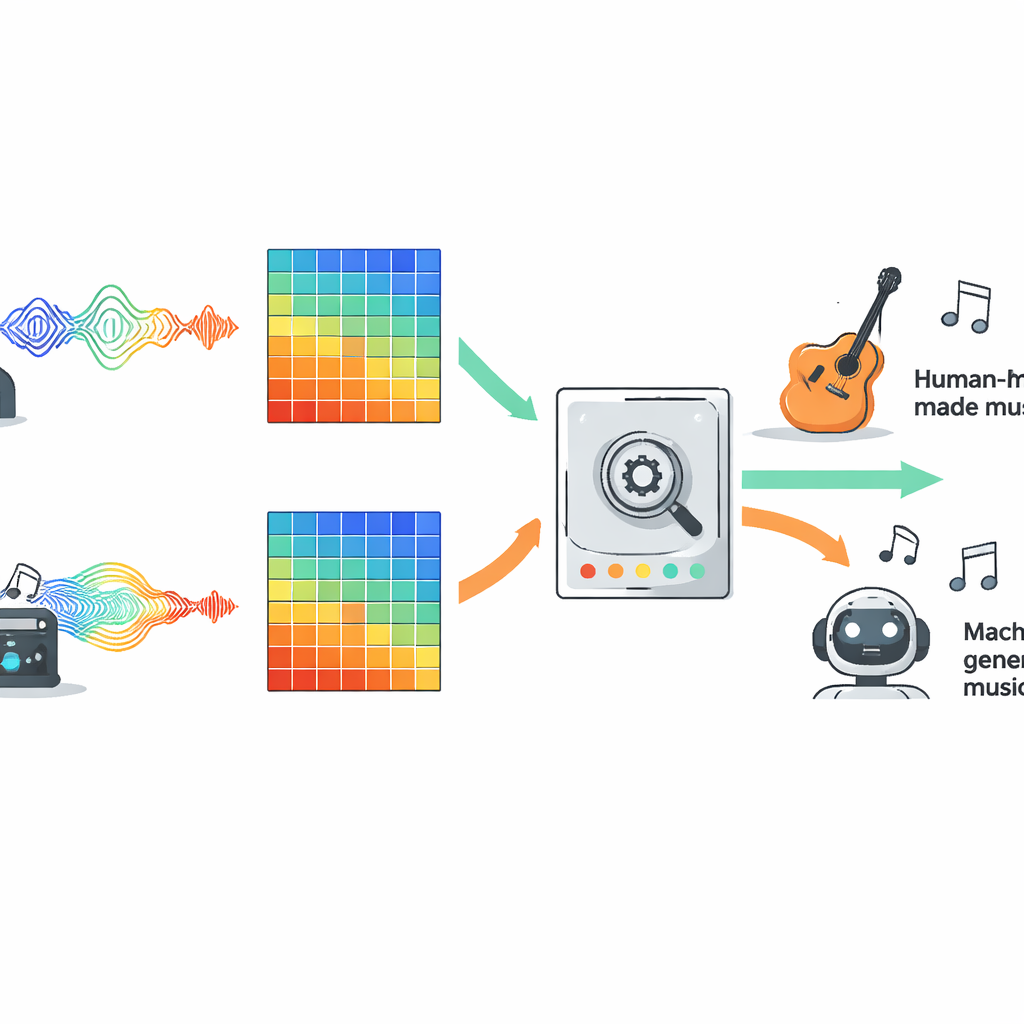
在不同类型音乐中表现最好的方法
在原始的 FakeMusicCaps 数据上,许多深度学习模型表现出色。一种名为 MobileNet 的紧凑架构取得了最高的准确率和 F1 分数,表明在测试材料与训练集相似时,快速且轻量的系统也能有良好表现。然而,在更具挑战性、域外的 M6 集合上,所有模型的性能都有所下降,揭示出当前检测器在面对新的生成器、流派或录音条件时的脆弱性。在这一更现实的设置中,一种经典的卷积网络 ResNet18 在域内成功与域外鲁棒性之间取得了最佳平衡,优于更复杂的 Transformer 和扩展序列模型。研究还测试了一个简单的多模态方案,将音频特征与歌词表示结合,当存在演唱文本时,这种融合明显优于仅有音频的基线。
窥视“黑箱”内部
仅有高分不足以令人放心,尤其当检测可能影响职业和版权时,作者转而使用可解释人工智能工具来检查表现最好的模型 ResNet18 的决策过程。他们应用了若干主流的解释方法,突出显示在谱图中对将片段判定为人类或机器制作最重要的区域。他们并不依赖单一技术,而是引入了一种“集成”方法,寻找多个方法一致认为重要的区域。当他们仅从音频表示中数字化移除这些重叠区域时,检测性能显著下降,尽管被掩蔽的谱图部分相对较小。这表明这些共识性区域确实突出了关键的声学模式,而非随机噪声。
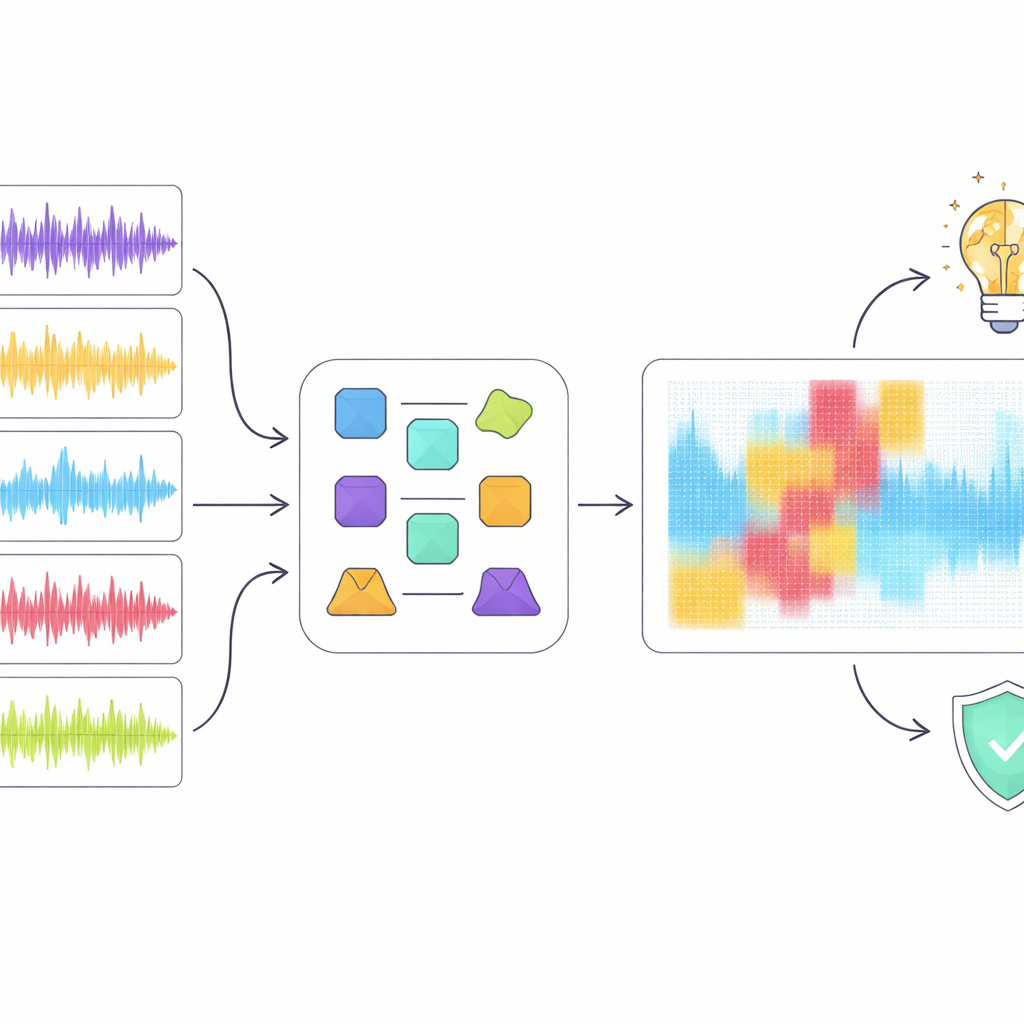
这对音乐与机器揭示了什么
可解释性分析揭示了模型“听觉”与人类听音之间的差距。例如,该检测器有时将短暂的音乐停顿视为可疑的人工痕迹,而非自然的结构,因而惩罚了人类听众会认为是良好结构的片段。总体来看,模型似乎更多依赖低层次的频谱奇异性,而非节奏、旋律与曲式等高层次的音乐概念。作者认为,未来的检测器应融入更丰富的音乐感知特征并更好地利用歌词,力求使决策更贴近音乐理解,而不仅仅是表面模式。
到目前为止,AI 与音乐的现状
这项工作提供了对检测 AI 生成音乐及解释此类检测器运作方式的首批广泛且透明的标尺之一。研究表明,当前系统在受控环境中往往能正确识别伪造曲目,但在音乐来自新来源时表现会下降,并且尚未以人类般的方式理解音乐结构。作者建议构建下一代检测器,将声学线索、歌词含义、音乐理论概念与可解释方法整合到统一流程中。如果成功,这类工具可帮助流媒体服务、权利持有者和听众在一个人类与机器作品共存的未来中,更公平、更透明地应对作品归属与识别问题。
引用: Li, Y., Sun, Q., Li, H. et al. Explainable detection of machine generated music and early systematic evaluation. Sci Rep 16, 13757 (2026). https://doi.org/10.1038/s41598-026-42133-7
关键词: AI 生成音乐, 深度伪造音频检测, 音乐真实性, 可解释的人工智能, 多模态模型