Clear Sky Science · pt
Detecção explicável de música gerada por máquina e avaliação sistemática inicial
Por que isso importa para fãs de música e criadores
A inteligência artificial já pode compor músicas convincentes em segundos. Isso é empolgante para a criatividade, mas preocupante para músicos, gravadoras e ouvintes que valorizam originalidade e crédito justo. Este estudo faz uma pergunta simples, porém urgente: podemos distinguir de forma confiável se uma peça musical foi criada por um humano ou por uma máquina, e podemos entender como esses sistemas de detecção tomam suas decisões?
O desafio de identificar canções feitas por IA
A música gerada por máquina já é usada em trilhas de fundo, auxílio na composição e até em terapia. Ainda assim, as mesmas ferramentas podem inundar plataformas de streaming com faixas de baixo esforço, borrar a autoria e enfraquecer o valor de composições humanas. Pesquisas anteriores sobre detecção de áudio falso concentraram-se principalmente em fala ou em casos musicais estreitos, frequentemente apoiando-se em modelos não publicados ou em testes pontuais. Os autores argumentam que o campo carece de uma comparação clara e sistemática de métodos, especialmente uma que também explique por que um detector rotula uma faixa como real ou falsa. O objetivo deles é construir esse primeiro benchmark abrangente.
Como os pesquisadores testaram os detectores
Para comparar abordagens concorrentes de forma justa, os autores avaliaram dez tipos populares de modelos em um grande conjunto de dados aberto chamado FakeMusicCaps, que mistura milhares de trechos curtos de música composta por humanos com clipes gerados por vários sistemas de texto-para-música. Todo o áudio foi convertido em espectrogramas Mel, uma representação visual do som amplamente usada em IA de áudio moderna, e cada modelo recebeu exatamente as mesmas entradas. A seleção incluiu aprendizado de máquina tradicional, várias famílias de redes neurais profundas, sistemas baseados em Transformer e modelos de espaço de estado mais recentes, projetados para acompanhar longas sequências ao longo do tempo. A equipe então avaliou os detectores treinados em um segundo conjunto de dados mais difícil, chamado M6, contendo músicas mais longas e variadas, para ver o quanto eles generalizavam além do ambiente de treinamento.
O que funcionou melhor em diferentes tipos de música
No conjunto FakeMusicCaps original, muitos modelos de aprendizado profundo tiveram desempenho forte. Uma arquitetura compacta chamada MobileNet alcançou a maior acurácia e pontuação F1, mostrando que sistemas rápidos e leves podem se sair bem quando o material de teste se assemelha ao conjunto de treinamento. Entretanto, na coleção M6, mais difícil e fora do domínio, o desempenho caiu para todos os modelos, revelando como os detectores atuais podem ser frágeis quando confrontados com novos geradores, gêneros ou condições de gravação. Nesse cenário mais realista, uma rede convolucional clássica conhecida como ResNet18 ofereceu o melhor equilíbrio entre sucesso em domínio e robustez fora do domínio, superando opções mais complexas como Transformers e modelos de sequência estendida. O estudo também testou uma configuração multimodal simples que combinava características de áudio com representações das letras, e essa fusão claramente superou as linhas de base só de áudio sempre que texto cantado estava disponível.
Olhando dentro da caixa-preta
Altas pontuações por si só não bastam quando a detecção pode afetar carreiras e direitos autorais, portanto os autores recorreram a ferramentas de inteligência artificial explicável para inspecionar como o melhor modelo, ResNet18, tomou suas decisões. Eles aplicaram vários métodos populares de explicação que destacam quais regiões de um espectrograma foram mais relevantes para classificar um trecho como humano ou gerado por máquina. Em vez de confiar em uma única técnica, introduziram uma abordagem em “ensemble” que procura por regiões que múltiplos métodos concordam serem importantes. Quando removeram digitalmente apenas essas regiões sobrepostas da representação de áudio, o desempenho de detecção caiu drasticamente, mesmo que uma porção relativamente pequena do espectrograma tenha sido mascarada. Isso sugere que o consenso destaca padrões acústicos genuinamente críticos em vez de ruído aleatório.
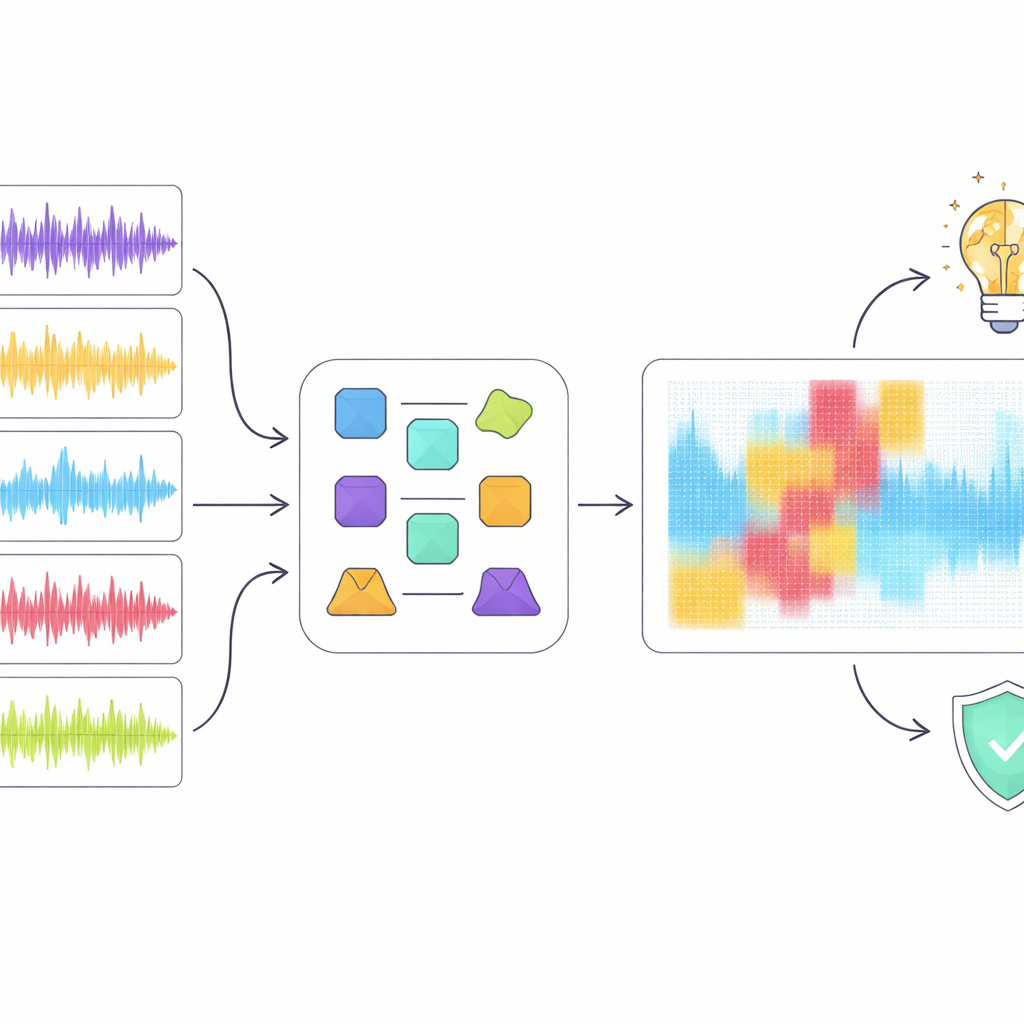
O que isso revela sobre música e máquinas
A análise de explicabilidade revelou uma lacuna entre como o modelo “escuta” e como os humanos ouvem música. Por exemplo, o detector às vezes tratou pequenas pausas musicais como artefatos suspeitos em vez de estruturas naturais, penalizando trechos que ouvintes humanos considerariam bem formados. No geral, o modelo parecia depender mais de peculiaridades espectrais de baixo nível do que de ideias musicais de alto nível, como ritmo, melodia e forma. Os autores defendem que detectores futuros devem incorporar recursos mais ricos e conscientes de música e um uso melhor das letras, buscando decisões que se alinhem mais estreitamente com a compreensão musical em vez de apenas padrões superficiais.
Onde isso deixa a IA e a música hoje
Este trabalho entrega um dos primeiros parâmetros amplos e transparentes para detectar música gerada por IA e para explicar como tais detectores operam. Mostra que sistemas atuais muitas vezes conseguem sinalizar faixas falsas corretamente em ambientes controlados, mas têm dificuldade quando a música vem de fontes novas, e que ainda não compreendem a estrutura musical do modo que as pessoas compreendem. Os autores propõem construir detectores de próxima geração que combinem pistas acústicas, significado das letras, conceitos da teoria musical e métodos explicáveis em um único pipeline. Se bem-sucedidas, tais ferramentas poderiam ajudar serviços de streaming, detentores de direitos e ouvintes a navegar um futuro onde música feita por humanos e por máquinas coexistam de forma mais justa e transparente.
Citação: Li, Y., Sun, Q., Li, H. et al. Explainable detection of machine generated music and early systematic evaluation. Sci Rep 16, 13757 (2026). https://doi.org/10.1038/s41598-026-42133-7
Palavras-chave: música gerada por IA, detecção de áudio deepfake, autenticidade musical, IA explicável, modelos multimodais