Clear Sky Science · en
Explainable detection of machine generated music and early systematic evaluation
Why this matters for music fans and creators
Artificial intelligence can now compose convincing songs in seconds. That is exciting for creativity but worrying for musicians, record labels, and listeners who care about originality and fair credit. This study asks a simple but urgent question: can we reliably tell whether a piece of music was created by a human or by a machine, and can we understand how these detection systems make their decisions?
The challenge of spotting AI-made songs
Machine-generated music is already being used for background soundtracks, songwriting help, and even therapy. Yet the same tools can flood streaming platforms with low-effort tracks, blur authorship, and weaken the value of human-made compositions. Earlier research on detecting fake audio focused mainly on speech, or on narrow musical cases, and often relied on unpublished models or one-off tests. The authors argue that the field lacks a clear, systematic comparison of methods, especially one that also explains why a detector calls a track real or fake. Their goal is to build that early, comprehensive benchmark.
How the researchers tested the detectors
To compare competing approaches fairly, the authors evaluated ten popular types of models on a large open dataset called FakeMusicCaps, which mixes thousands of short clips of human-composed music with clips generated by several text-to-music systems. All audio was converted into Mel spectrograms, a visual representation of sound widely used in modern audio AI, and every model saw exactly the same inputs. The line-up included traditional machine learning, several families of deep neural networks, Transformer-based systems, and newer state space models that are designed to follow long sequences over time. The team then pushed the trained detectors onto a second, tougher dataset called M6, containing longer and more varied songs, to see how well they generalised beyond their training environment.
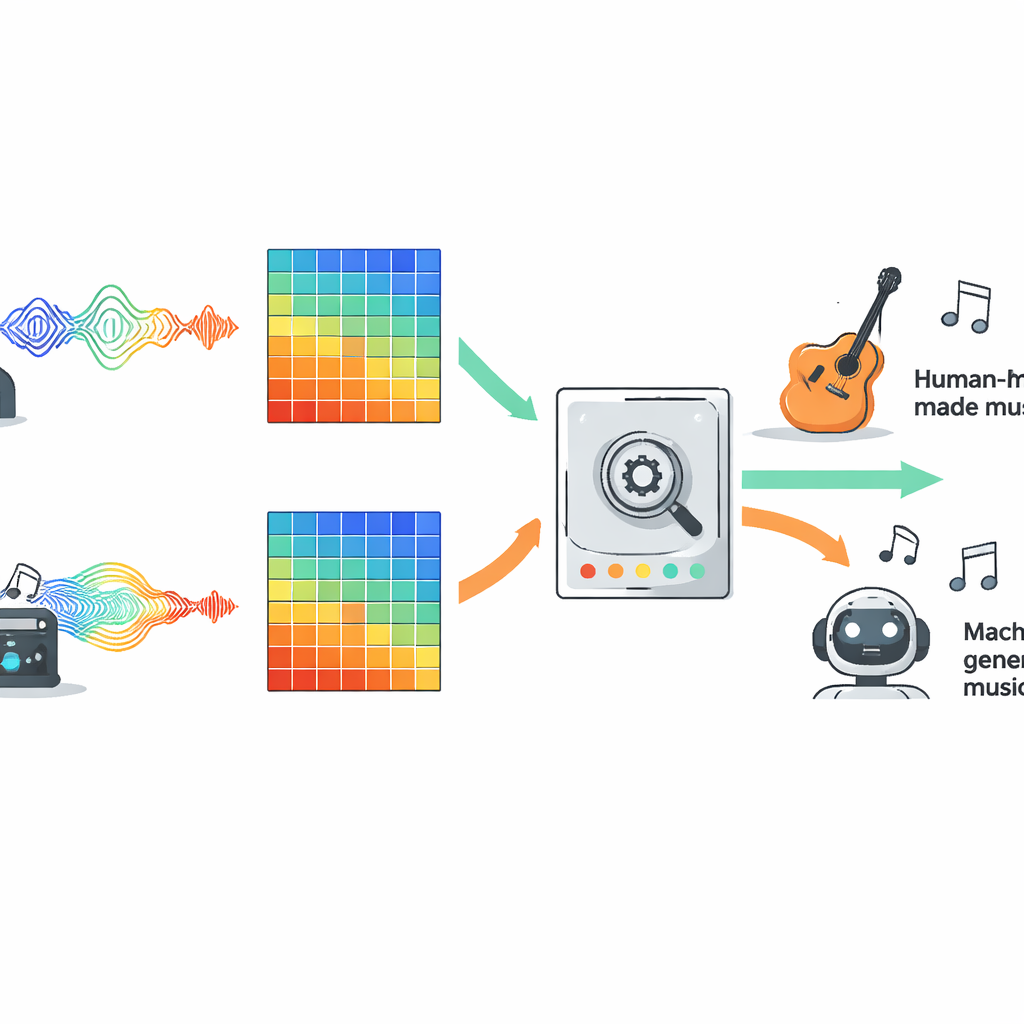
What worked best across different kinds of music
On the original FakeMusicCaps data, many deep learning models performed strongly. A compact architecture called MobileNet reached the highest accuracy and F1 score, showing that fast and lightweight systems can do well when test material looks similar to the training set. However, on the harder, out-of-domain M6 collection, performance dropped for all models, revealing how brittle current detectors can be when confronted with new generators, genres, or recording conditions. In this more realistic setting, a classic convolutional network known as ResNet18 delivered the best balance between in-domain success and out-of-domain robustness, beating more complex options such as Transformers and extended sequence models. The study also tested a simple multimodal setup that combined audio features with representations of the lyrics, and this fusion clearly outperformed audio-only baselines whenever sung text was available.
Looking inside the black box
High scores alone are not enough when detection may affect careers and copyrights, so the authors turned to explainable artificial intelligence tools to inspect how the best model, ResNet18, reached its decisions. They applied several popular explanation methods that highlight which regions of a spectrogram mattered most for classifying a clip as human or machine-made. Rather than trusting any single technique, they introduced an “ensemble” approach that looks for regions that multiple methods agree are important. When they digitally removed only these overlapping regions from the audio representation, detection performance dropped sharply even though a relatively small portion of the spectrogram was masked. This suggests that the consensus highlights genuinely critical acoustic patterns rather than random noise.
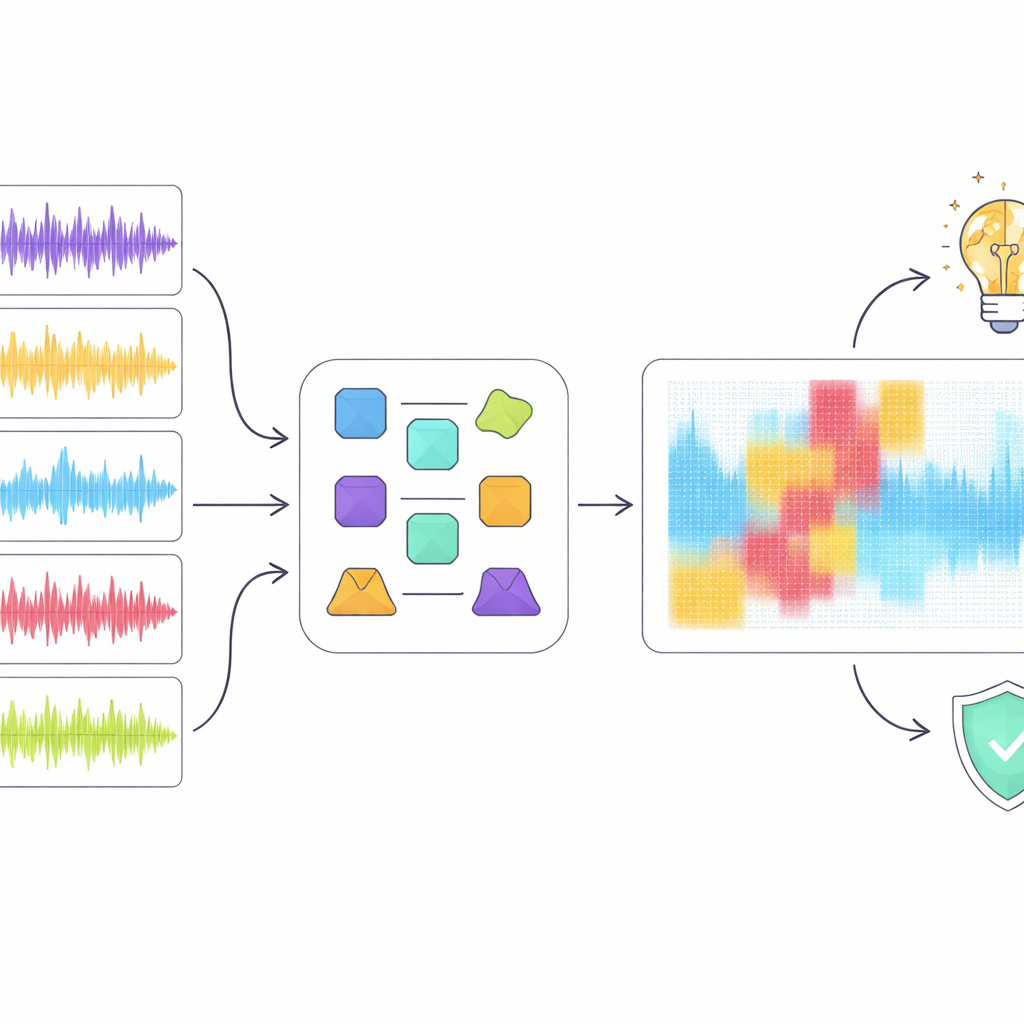
What this reveals about music and machines
The explainability analysis uncovered a gap between how the model “listens” and how humans hear music. For example, the detector sometimes treated short musical pauses as suspicious artefacts instead of natural structure, penalising clips that human listeners would consider well-formed. Overall, the model appeared to rely more on low-level spectral quirks than on high-level musical ideas like rhythm, melody, and form. The authors argue that future detectors should weave in richer music-aware features and better use of lyrics, aiming for decisions that align more closely with musical understanding rather than just surface patterns.
Where this leaves AI and music today
This work delivers one of the first broad, transparent yardsticks for detecting AI-generated music and for explaining how such detectors operate. It shows that current systems can often flag fake tracks correctly in controlled settings but struggle when music comes from new sources, and that they do not yet grasp musical structure the way people do. The authors propose building next-generation detectors that combine acoustic cues, lyric meaning, music theory concepts, and explainable methods into a single pipeline. If successful, such tools could help streaming services, rights holders, and listeners navigate a future where human and machine-made music coexist more fairly and transparently.
Citation: Li, Y., Sun, Q., Li, H. et al. Explainable detection of machine generated music and early systematic evaluation. Sci Rep 16, 13757 (2026). https://doi.org/10.1038/s41598-026-42133-7
Keywords: AI-generated music, deepfake audio detection, music authenticity, explainable AI, multimodal models