Clear Sky Science · fr
Détection explicable de la musique générée par machine et première évaluation systématique
Pourquoi cela compte pour les fans et les créateurs de musique
L'intelligence artificielle peut désormais composer des chansons convaincantes en quelques secondes. C'est stimulant pour la créativité, mais préoccupant pour les musicien·ne·s, les maisons de disques et les auditeurs soucieux d'originalité et d'un crédit juste. Cette étude pose une question simple mais urgente : peut-on dire de manière fiable si un morceau a été créé par un humain ou par une machine, et peut-on comprendre comment ces systèmes de détection prennent leurs décisions ?
Le défi de repérer les chansons fabriquées par l'IA
La musique générée par machine est déjà utilisée pour des bandes sonores d'ambiance, de l'aide à la composition et même des thérapies. Pourtant, les mêmes outils peuvent inonder les plateformes de streaming de morceaux produits sans soin, brouiller la paternité et dévaluer les créations humaines. Les travaux antérieurs sur la détection d'audio truqué se concentraient principalement sur la parole, ou sur des cas musicaux restreints, et s'appuyaient souvent sur des modèles non publiés ou des tests ponctuels. Les auteurs soutiennent que le domaine manque d'une comparaison claire et systématique des méthodes, en particulier d'une comparaison qui explique aussi pourquoi un détecteur qualifie un morceau de réel ou de faux. Leur objectif est de bâtir cette référence précoce et complète.
Comment les chercheurs ont testé les détecteurs
Pour comparer équitablement les approches concurrentes, les auteurs ont évalué dix types de modèles populaires sur un large jeu de données ouvert appelé FakeMusicCaps, qui mélange des milliers de courts extraits de musique composés par des humains avec des extraits générés par plusieurs systèmes texte-vers-musique. Tout l'audio a été converti en spectrogrammes de Mel, une représentation visuelle du son largement utilisée en IA audio moderne, et chaque modèle a vu exactement les mêmes entrées. La sélection comprenait l'apprentissage automatique traditionnel, plusieurs familles de réseaux neuronaux profonds, des systèmes basés sur Transformer et des modèles d'état d'espace plus récents conçus pour suivre de longues séquences dans le temps. L'équipe a ensuite testé les détecteurs entraînés sur un second jeu de données plus difficile, appelé M6, contenant des morceaux plus longs et plus variés, afin de mesurer leur capacité de généralisation hors de l'environnement d'entraînement.
Ce qui a le mieux fonctionné selon les types de musique
Sur les données FakeMusicCaps d'origine, de nombreux modèles de deep learning ont obtenu de bons résultats. Une architecture compacte appelée MobileNet a atteint la meilleure précision et le meilleur score F1, montrant que des systèmes rapides et légers peuvent bien fonctionner lorsque le matériau de test ressemble au jeu d'entraînement. Cependant, sur la collection M6, plus difficile et hors domaine, les performances ont chuté pour tous les modèles, révélant la fragilité des détecteurs actuels face à de nouveaux générateurs, genres ou conditions d'enregistrement. Dans ce contexte plus réaliste, un réseau convolutionnel classique connu sous le nom de ResNet18 a offert le meilleur compromis entre succès in-domain et robustesse out-of-domain, surpassant des options plus complexes comme les Transformers et les modèles de séquence étendue. L'étude a également testé une configuration multimodale simple combinant des caractéristiques audio avec des représentations des paroles, et cette fusion a clairement dépassé les bases uniquement audio dès lors que du texte chanté était disponible.
Regarder à l'intérieur de la boîte noire
Des scores élevés ne suffisent pas lorsque la détection peut affecter des carrières et des droits d'auteur, aussi les auteurs se sont tournés vers des outils d'intelligence artificielle explicable pour examiner comment le meilleur modèle, ResNet18, prenait ses décisions. Ils ont appliqué plusieurs méthodes d'explication populaires qui mettent en évidence quelles régions d'un spectrogramme ont le plus compté pour classer un extrait comme humain ou fabriqué par machine. Plutôt que de se fier à une seule technique, ils ont introduit une approche « ensembliste » qui recherche les régions jugées importantes par plusieurs méthodes. Lorsqu'ils ont supprimé numériquement uniquement ces régions chevauchantes de la représentation audio, les performances de détection ont chuté fortement bien qu'une portion relativement petite du spectrogramme ait été masquée. Cela suggère que le consensus met en évidence des motifs acoustiques réellement critiques plutôt que du bruit aléatoire.
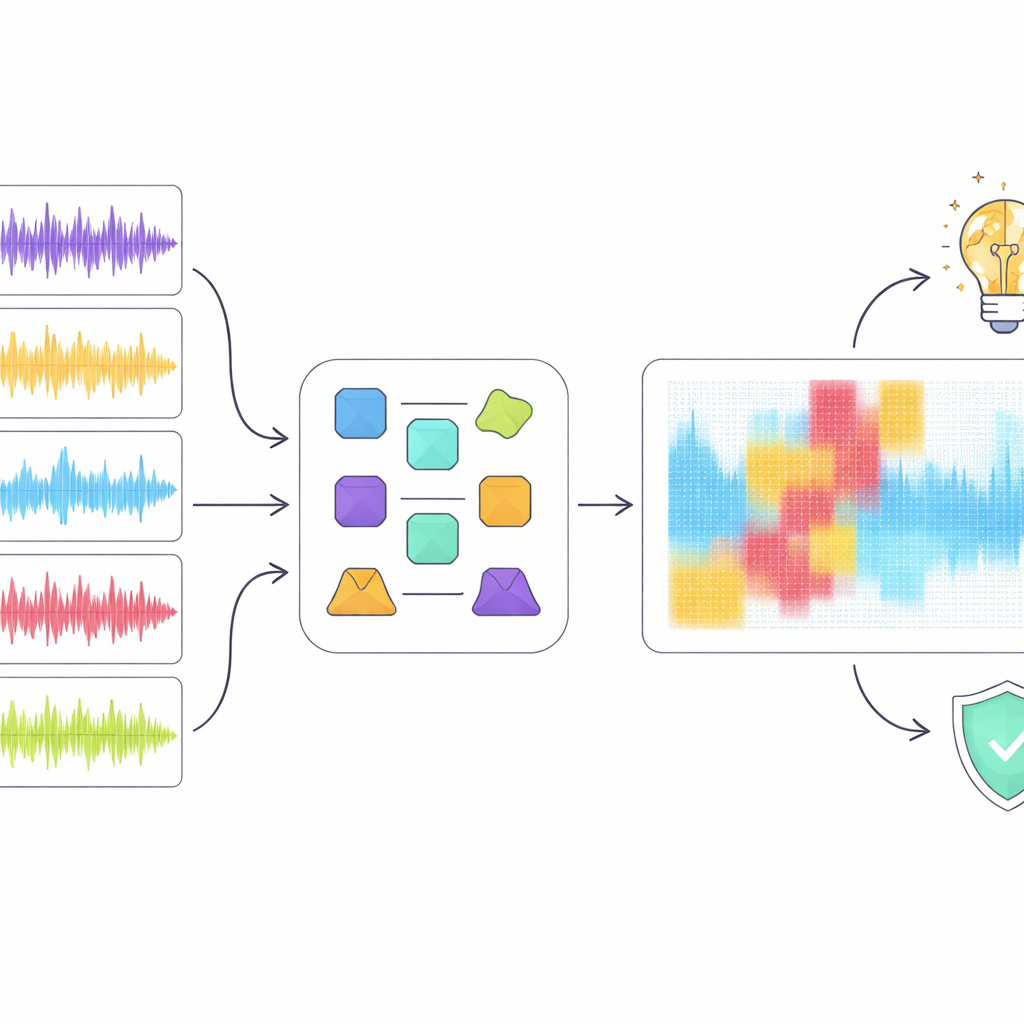
Ce que cela révèle sur la musique et les machines
L'analyse d'explicabilité a mis au jour un fossé entre la façon dont le modèle « écoute » et la manière dont les humains perçoivent la musique. Par exemple, le détecteur traitait parfois de courtes pauses musicales comme des artefacts suspects plutôt que comme une structure naturelle, pénalisant des extraits que des auditeurs humains jugeraient bien formés. Globalement, le modèle semblait s'appuyer davantage sur des bizarreries spectrales de bas niveau que sur des idées musicales de haut niveau comme le rythme, la mélodie et la forme. Les auteurs soutiennent que les détecteurs futurs devraient intégrer des caractéristiques plus riches conscientes de la musique et mieux exploiter les paroles, visant des décisions qui s'alignent davantage sur la compréhension musicale plutôt que sur de simples motifs de surface.
Où en est l'IA et la musique aujourd'hui
Ce travail fournit l'un des premiers étalons larges et transparents pour détecter la musique générée par l'IA et pour expliquer le fonctionnement de tels détecteurs. Il montre que les systèmes actuels peuvent souvent repérer correctement les morceaux falsifiés dans des conditions contrôlées, mais peinent lorsque la musique provient de sources nouvelles, et qu'ils ne saisissent pas encore la structure musicale comme le ferait un humain. Les auteurs proposent de construire des détecteurs de nouvelle génération qui combinent indices acoustiques, sens des paroles, concepts de théorie musicale et méthodes explicables dans un même pipeline. S'ils sont efficaces, ces outils pourraient aider les services de streaming, les ayants droit et les auditeurs à naviguer vers un avenir où la musique humaine et la musique fabriquée par machine coexistent de manière plus juste et transparente.
Citation: Li, Y., Sun, Q., Li, H. et al. Explainable detection of machine generated music and early systematic evaluation. Sci Rep 16, 13757 (2026). https://doi.org/10.1038/s41598-026-42133-7
Mots-clés: musique générée par IA, détection d'audio deepfake, authenticité musicale, IA explicable, modèles multimodaux