Clear Sky Science · ja
機械生成音楽の説明可能な検出と初期の体系的評価
なぜこれが音楽ファンと制作者に重要か
人工知能は今や数秒で説得力のある楽曲を作曲できます。これは創作にとって刺激的ですが、独自性や正当なクレジットを重視するミュージシャン、レコード会社、聴衆にとっては懸念材料でもあります。本研究は単純だが差し迫った問いを投げかけます:楽曲が人間によって作られたのか機械によって作られたのかを信頼できる方法で判別できるか、そして検出システムがどのように判断しているかを理解できるか、です。
AI製の曲を見抜く難しさ
機械生成音楽は既に背景音楽、作曲支援、さらには療法用途にも使われています。しかし同じ技術がストリーミングプラットフォームを低労力のトラックで溢れさせ、作者の所在を曖昧にし、人間の作曲物の価値を損なう可能性もあります。これまでの偽音声検出研究は主に音声や限られた音楽ケースに集中し、未発表のモデルや断片的なテストに依存することが多かったと著者らは指摘します。この分野には、特に検出器がなぜトラックを人間作か機械作かと判断したのかを説明する比較が欠けていると論じており、彼らの目標はその初期かつ包括的なベンチマークを構築することです。
研究者たちが検出器を検証した方法
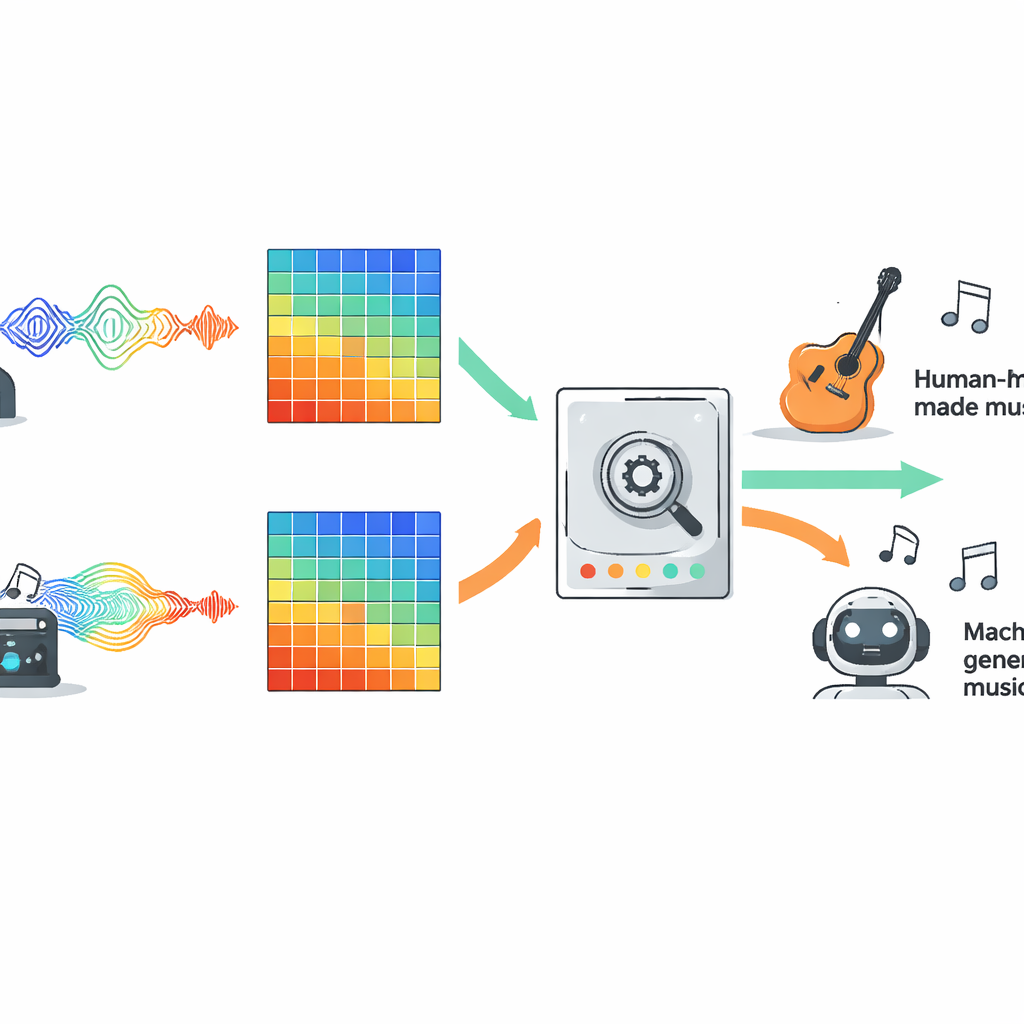
公正に手法を比較するために、著者らはFakeMusicCapsと呼ばれる大規模な公開データセット上で、十種類の代表的モデルを評価しました。このデータセットは、人間が作曲した短いクリップと複数のテキストから音楽を生成するシステムが作ったクリップを数千混合しています。全ての音声はメルスペクトログラムに変換され、現代の音声AIで広く使われる音の視覚表現が各モデルに同一の入力として与えられました。ラインナップには従来の機械学習、いくつかの深層ニューラルネットワーク群、トランスフォーマーベースのシステム、そして長い系列を追跡する設計の新しいステートスペースモデルが含まれていました。訓練済みの検出器は次に、より長く多様な楽曲を含む難しい二次データセットM6に適用され、訓練環境を越えてどの程度一般化するかが評価されました。
異なる音楽ジャンルで最も有効だったもの
元のFakeMusicCapsデータでは、多くの深層学習モデルが高い性能を示しました。コンパクトなアーキテクチャであるMobileNetは最高の精度とF1スコアを達成し、テスト素材が訓練セットに似ている場合に高速で軽量なシステムでも優れた結果を出せることを示しました。しかし、より難しいドメイン外のM6コレクションでは全モデルの性能が低下し、新しい生成器やジャンル、録音条件に直面したときの現行検出器の脆弱性が明らかになりました。このより現実的な設定では、ResNet18として知られる古典的な畳み込みネットワークが、ドメイン内での成功とドメイン外での堅牢性の間で最良のバランスを示し、トランスフォーマーや拡張系列モデルのようなより複雑な選択肢を上回りました。研究では歌詞の表現と音声特徴を組み合わせた単純なマルチモーダル構成も試し、歌唱テキストが利用できる場合はこの融合が音声のみのベースラインを明確に上回ることが示されました。
ブラックボックスの中を覗く
検出が職業や著作権に影響を及ぼす可能性があるため、高いスコアだけでは不十分です。そこで著者らは説明可能なAIツールを用いて、最良のモデルであるResNet18がどのように判断を下しているかを調査しました。彼らはいくつかの一般的な説明手法を適用して、スペクトログラムのどの領域が人間作か機械作かを分類する際に重要だったかを強調しました。単一の手法を盲信するのではなく、複数の手法が重要と一致する領域を探す“アンサンブル”アプローチを導入しました。これらの重複領域だけを音声表現からデジタルに除去すると、スペクトログラムの比較的小さな部分がマスクされただけでも検出性能が急落しました。これは合意された領域がランダムノイズではなく、本当に重要な音響パターンを示していることを示唆します。
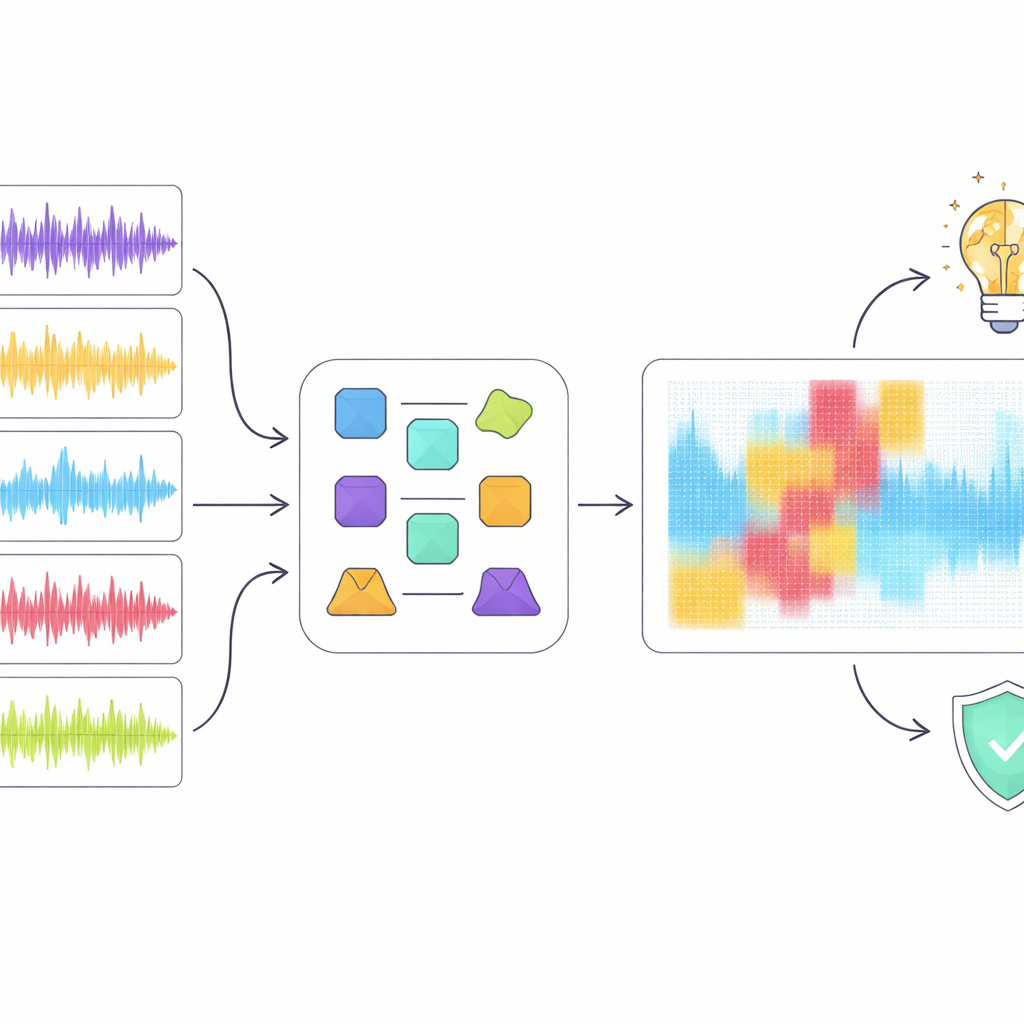
音楽と機械についてこれが示すこと
説明可能性の分析は、モデルの“聞き方”と人間の音楽の聞き方との間にギャップがあることを明らかにしました。例えば、検出器は短い音楽的な間(ポーズ)を不自然なアーティファクトとして疑わしく扱い、人間の聴き手が良く構成されたものと見なすクリップを不利に扱うことがありました。全体として、モデルはリズムやメロディ、形式のような高レベルの音楽的概念よりも、低レベルのスペクトルの特異性に依存しているように見えました。著者らは将来の検出器がより豊かな音楽認識特徴と歌詞のよりよい活用を組み込み、表層パターンだけでなく音楽的理解とより整合する判断を目指すべきだと主張しています。
現時点でのAIと音楽の位置付け
本研究は、AI生成音楽を検出しその動作を説明するための初期の広範で透明な指標の一つを提供します。制御された設定では現行システムが偽トラックを正しく検出できることが多い一方で、新しいソースから来る音楽では苦戦し、人間のような音楽構造をまだ把握していないことが示されました。著者らは、音響手がかり、歌詞の意味、音楽理論の概念、説明可能な手法を単一のパイプラインに統合する次世代の検出器の構築を提案しています。これが実現すれば、ストリーミング事業者、権利者、聴衆が人間と機械生成の音楽がより公平かつ透明に共存する未来を進める手助けになる可能性があります。
引用: Li, Y., Sun, Q., Li, H. et al. Explainable detection of machine generated music and early systematic evaluation. Sci Rep 16, 13757 (2026). https://doi.org/10.1038/s41598-026-42133-7
キーワード: AI生成音楽, ディープフェイク音声検出, 音楽の真正性, 説明可能なAI, マルチモーダルモデル