Clear Sky Science · es
Detección explicable de música generada por máquinas y evaluación sistemática temprana
Por qué esto importa para aficionados y creadores musicales
La inteligencia artificial puede ahora componer canciones convincentes en segundos. Eso es estimulante para la creatividad, pero inquietante para músicos, discográficas y oyentes que valoran la originalidad y el crédito justo. Este estudio plantea una pregunta simple pero urgente: ¿podemos distinguir de forma fiable si una pieza musical fue creada por un humano o por una máquina, y podemos entender cómo estos sistemas de detección toman sus decisiones?
El desafío de detectar canciones hechas por IA
La música generada por máquinas ya se utiliza para bandas sonoras de fondo, ayuda en la composición e incluso en terapias. Sin embargo, las mismas herramientas pueden inundar las plataformas de streaming con pistas de bajo esfuerzo, difuminar la autoría y debilitar el valor de las composiciones humanas. Investigaciones anteriores sobre detección de audio falso se centraron principalmente en voz, o en casos musicales muy restringidos, y con frecuencia dependieron de modelos no publicados o pruebas puntuales. Los autores sostienen que el campo carece de una comparación clara y sistemática de métodos, especialmente una que también explique por qué un detector considera una pista real o falsa. Su objetivo es construir ese benchmark temprano y comprensivo.
Cómo probaron los detectores
Para comparar los enfoques de forma justa, los autores evaluaron diez tipos populares de modelos sobre un gran conjunto de datos abierto llamado FakeMusicCaps, que mezcla miles de fragmentos cortos de música compuesta por humanos con fragmentos generados por varios sistemas texto-a-música. Todo el audio se convirtió en espectrogramas de Mel, una representación visual del sonido ampliamente usada en la IA de audio moderna, y cada modelo vio exactamente las mismas entradas. La alineación incluyó aprendizaje automático tradicional, varias familias de redes neuronales profundas, sistemas basados en Transformers y modelos de espacio de estado más recientes diseñados para seguir secuencias largas en el tiempo. El equipo llevó después los detectores entrenados a un segundo conjunto más exigente llamado M6, que contiene canciones más largas y variadas, para ver hasta qué punto generalizaban más allá de su entorno de entrenamiento.
Qué funcionó mejor en distintos tipos de música
En los datos originales de FakeMusicCaps, muchos modelos de aprendizaje profundo tuvieron un rendimiento fuerte. Una arquitectura compacta llamada MobileNet alcanzó la mayor precisión y la mejor puntuación F1, mostrando que sistemas rápidos y ligeros pueden rendir bien cuando el material de prueba es similar al del entrenamiento. Sin embargo, en la colección M6, más difícil y fuera de dominio, el rendimiento cayó para todos los modelos, lo que revela lo frágiles que pueden ser los detectores actuales al enfrentarse a nuevos generadores, géneros o condiciones de grabación. En este escenario más realista, una red convolucional clásica conocida como ResNet18 ofreció el mejor equilibrio entre éxito en dominio y robustez fuera de dominio, superando opciones más complejas como Transformers y modelos de secuencia extendida. El estudio también probó una configuración multimodal simple que combinó características de audio con representaciones de las letras, y esta fusión superó claramente las baselines solo de audio siempre que había texto cantado disponible.
Mirando dentro de la caja negra
Las altas puntuaciones por sí solas no bastan cuando la detección puede afectar carreras y derechos de autor, por lo que los autores recurrieron a herramientas de inteligencia artificial explicable para inspeccionar cómo el mejor modelo, ResNet18, llegó a sus decisiones. Aplicaron varios métodos de explicación populares que resaltan qué regiones de un espectrograma fueron más relevantes para clasificar un fragmento como humano o generado por máquina. En lugar de confiar en una única técnica, introdujeron un enfoque de “conjunto” que busca regiones en las que varios métodos coinciden en su importancia. Cuando eliminaron digitalmente solo esas regiones solapadas de la representación de audio, el rendimiento de detección cayó drásticamente, aunque solo se enmascaró una porción relativamente pequeña del espectrograma. Esto sugiere que el consenso destaca patrones acústicos genuinamente críticos y no ruido aleatorio.
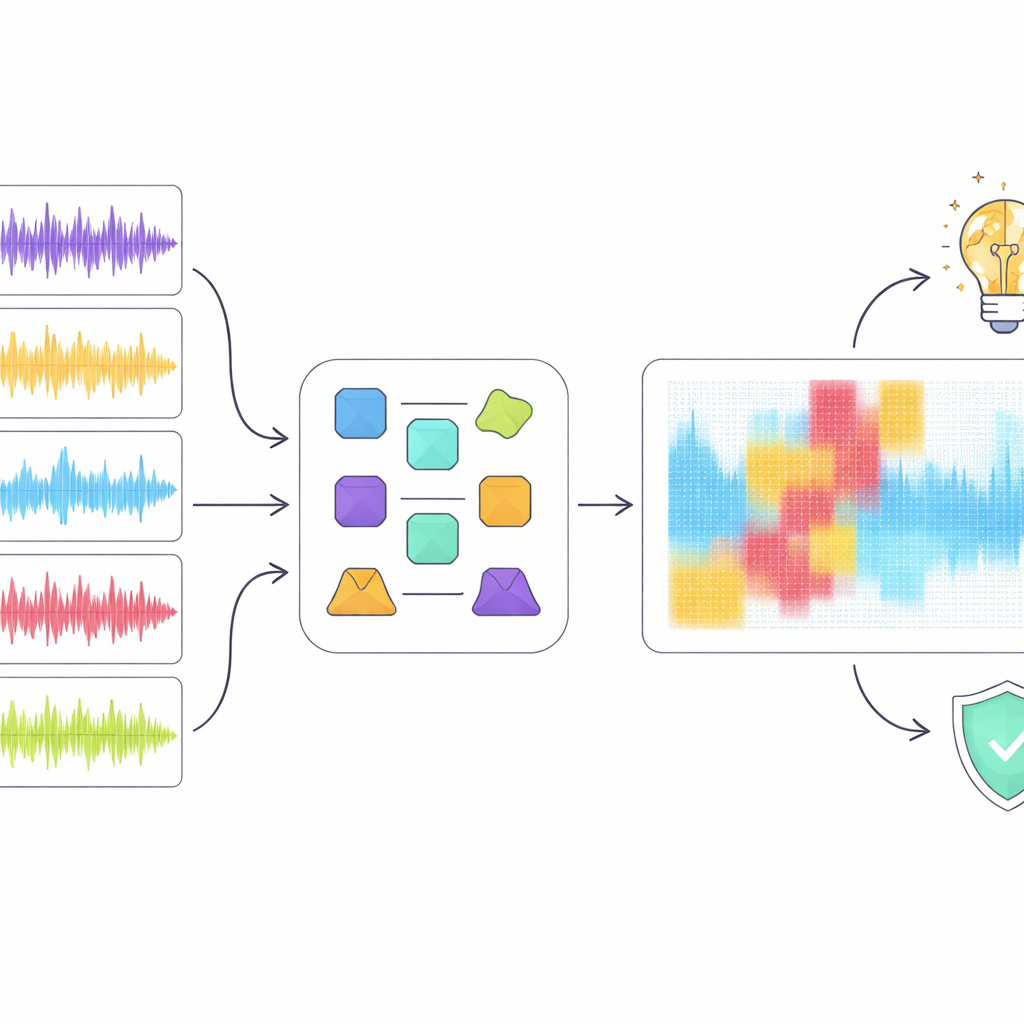
Qué revela esto sobre la música y las máquinas
El análisis de explicabilidad descubrió una brecha entre cómo el modelo “oye” y cómo las personas perciben la música. Por ejemplo, el detector a veces trató pausas musicales breves como artefactos sospechosos en lugar de como estructura natural, penalizando fragmentos que oyentes humanos considerarían bien formados. En general, el modelo parecía apoyarse más en peculiaridades espectrales de bajo nivel que en ideas musicales de alto nivel como ritmo, melodía y forma. Los autores sostienen que los detectores futuros deberían incorporar características más ricas y conscientes de la música y un mejor uso de las letras, buscando decisiones que se alineen más estrechamente con la comprensión musical en lugar de limitarse a patrones superficiales.
Dónde deja esto a la IA y la música hoy
Este trabajo ofrece uno de los primeros puntos de referencia amplios y transparentes para detectar música generada por IA y para explicar cómo operan dichos detectores. Muestra que los sistemas actuales a menudo pueden señalar pistas falsas correctamente en entornos controlados, pero tienen dificultades cuando la música proviene de nuevas fuentes, y que aún no comprenden la estructura musical como lo hacen las personas. Los autores proponen construir detectores de próxima generación que combinen indicios acústicos, significado de las letras, conceptos de teoría musical y métodos explicables en una única canalización. Si tienen éxito, estas herramientas podrían ayudar a servicios de streaming, titulares de derechos y oyentes a navegar un futuro en el que la música humana y la generada por máquinas coexistan de forma más justa y transparente.
Cita: Li, Y., Sun, Q., Li, H. et al. Explainable detection of machine generated music and early systematic evaluation. Sci Rep 16, 13757 (2026). https://doi.org/10.1038/s41598-026-42133-7
Palabras clave: Música generada por IA, detección de audio deepfake, autenticidad musical, IA explicable, modelos multimodales